Updated March 24, 2023
Introduction to Nearest Neighbors Algorithm
K Nearest Neighbor (KNN) algorithm is basically a classification algorithm in Machine Learning which belongs to the supervised learning category. However, it can be used in regression problems as well. KNN algorithms have been used since 1970 in many applications like pattern recognition, data mining, statistical estimation, and intrusion detection, and many more. It is widely disposable in real-life scenarios since it is non-parametric, i.e., it does not make any underlying assumptions about the distribution of data.
Classification of Nearest Neighbors Algorithm
KNN under classification problem basically classifies the whole data into training data and test sample data. The distance between training points and sample points is evaluated, and the point with the lowest distance is said to be the nearest neighbor. KNN algorithm predicts the result on the basis of the majority.
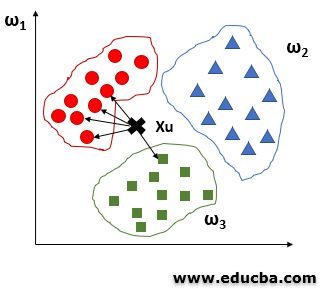
Let us see the idea behind KNN with the help of an example given below:
- Let us take three different classes, and we need to find a class label for the unknown data xu.
- In this case, let us find the Euclidean distance and k as 5 nearest neighbors.
- From the above figure, we can observe that among the 5 closest neighbors, 4 belong to class ω1 and 1 belongs to class ω3, so xu is assigned to ω1.
The basic KNN algorithm stores all the examples in the training set, creating high storage requirements (and computational cost). However, the entire training set need not be stored as the examples may contain information that is highly redundant. Most of the time almost all of the information that is relevant for classification purposes is located around the decision boundaries.
How to Implement the Nearest Neighbors Algorithm?
In KNN whole data is classified into training and test sample data.
In a classification problem, k nearest algorithm is implemented using the following steps:
- Pick a value for k, where k is the number of training examples in the feature space.
- Calculate the distance of unknown data points from all the training examples.
- Search for the k observations in the training data that are nearest to the measurements of the unknown data point.
- Calculate the distance between the unknown data point and the training data.
- The training data which is having the smallest value will be declared as the nearest neighbor.
In the KNN-regression problem, the only difference is that the distance between training points and sample points is evaluated and the point with the lowest average distance is declared as the nearest neighbor. It predicts the result on the basis of the average of the total sum.
How to Choose the K Value?
Hence the value of k is chosen properly according to the need.
- If k is chosen large it will be less sensitive to noise and hence performance increases.
- If k is chosen small it will be able to capture fine structures if exist in the feature space. If k is too small it may lead to overfitting i.e. algorithm performs excellently on the training set and its performance degrades on unseen test data
Distance Metrics
The distance can be calculated in the following ways:
a. Euclidian distance
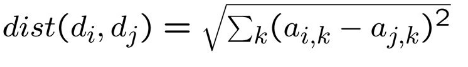
b. Manhattan distance
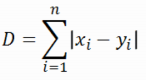
c. Weighted distance
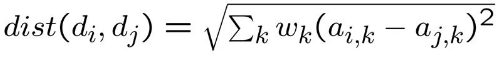
How to Choose the Weights?
For both classification and regression problems, the weighted distance method can be used to calculate the distance. Weights are assigned which signifies the contributions of the neighbors so that the nearer neighbors are assigned more weights showing more contribution than the average.
Weights can be chosen as:
- wi = 1/ k
- wi ∼ 1 − ||xi − xo ||
- wi ∼ k − rank ||xi − xo ||
Improvement
1. The first technique states that by providing different weights to the nearest neighbor improvement in the prediction can be achieved. In such cases, important attributes are given larger weights and less important attributes are given smaller weights.
2. There are two classical algorithms that can improve the speed of the nearest neighbor search.
Example:
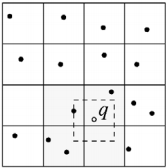
We have given a set of N points in D-dimensional space and an unlabeled example q. We need to find the point that minimizes the distance to q. The KNN approach becomes impractical for large values of N and D.
There are two classical algorithms that speed up the nearest neighbor search.
1. Bucketing: In the Bucketing algorithm, space is divided into identical cells and for each cell, the data points inside it are stored in a list n. The cells are examined in order of increasing distance from the point q and for each cell, the distance is computed between its internal data points and the point q. The search terminates when the distance from the point q to the cell exceeds the distance to the closest point already visited.
2. k-d trees: A k-d tree is a generalization of a binary search tree in high dimensions. Here, each internal node in a k-d tree is associated with a hyper-rectangle and a hyperplane orthogonal to one of the coordinate axis. The hyper-plane splits the hyper-rectangle into two parts, which are associated with the child nodes. The partitioning process goes on until the number of data points in the hyper-rectangle falls below some given threshold n.
Advantages and Disadvantages of Nearest Neighbors Algorithm
Given below are the advantages and disadvantages:
Advantages:
- It is very simple to understand and implement.
- Robust to noisy data.
- The decision boundaries can be of arbitrary shapes.
- It requires only a few parameters to be tuned.
- KNN classifier can be updated at a very little cost.
Disadvantages:
- K-NN is computationally expensive.
- It is a lazy learner i.e. it uses all the training data at the runtime and hence is slow.
- Complexity is O(n) for each instance to be classified.
- Curse of dimensionality: distance can be dominated by irrelevant attributes.
Conclusion
With increasing K, we get smoother, more defined boundaries across different classifications. Also, the accuracy of the above classifier increases as we increase the number of data points in the training set.
Recommended Articles
This is a guide to the Nearest Neighbors Algorithm. Here we discuss the classification and implementation of the nearest neighbors algorithm along with its advantages & disadvantages. You may also look at the following articles to learn more –
