Updated March 6, 2023

Introduction to MapReduce vs spark
MapReduce and Spark are defined as frameworks that enable the building of flagship products in the zone of big data analytics. These frameworks are open source projects by Apache Software Foundation. Defining them individually, MapReduce or better known as Hadoop MapReduce, is defined as a framework that enables application writing that in turn enables processing vast amounts of data on clusters in a distributed form so that fault tolerance and reliability is maintained. MapReduce model is built by breaking it into 2 words of “Map” and “Reduce” both denoting the task that is followed in sequence to enable the working of MapReduce. On the other hand, a spark is a framework that is also used for processing a vast amount of data analytics applications across a cluster of computers and is commonly termed as a “Unified Analytics Engine”.
Head to Head Comparison Between MapReduce vs spark (Infographics)
Below are the top 8 differences between MapReduce vs spark:
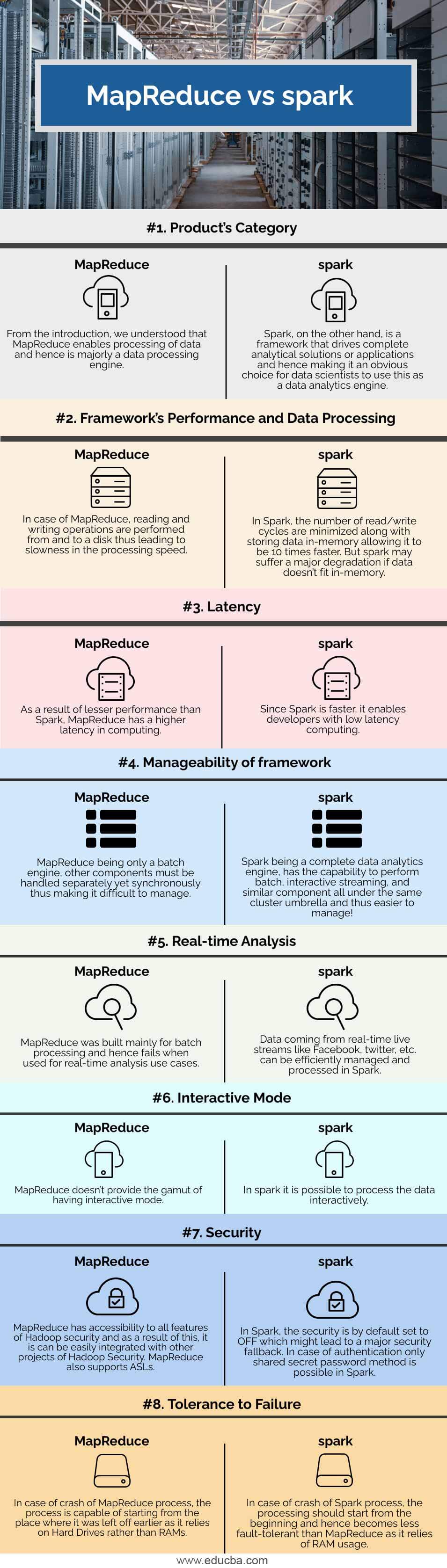
Key differences between MapReduce and spark
Before we learn about the differences between MapReduce and Spark, we need to understand the point of similarity so that we can try to know the reason for the confusion and the intention behind the scripting of this article. Both the frameworks are used for processing vast volumes of data in respective use cases. Not only that, Spark in itself uses MapReduce as the foundation, the compatibility of MapReduce and Spark remains the same and finally both are from the Apache Software Foundation.
Since the topic of discussion is a “versus”, understanding this similarity makes us aware of why such confusion is created, and hence without wasting much time, let us get into the first point of difference and that is the category of the product. MapReduce was built for batch processing data and is majorly used for the same, whereas spark is a complete data analytics engine and hence the undisputed choice for data science use cases. Next, in MapReduce, the read and write operations are performed on the disk as the data is persisted back to the disk post the map, and reduce action makes the processing speed a bit slower whereas Spark performs the operations in memory leading to faster execution. As a result of this difference, Spark needs a lot of memory and if the memory is not enough for the data to fit in, it might lead to major degradations in performance. MapReduce is used for handling the use cases when data is not possible to be fit in memory. As a result of faster processing by Spark, it provides lower latency in processing than MapReduce.
Next comes the manageability part, as MapReduce is just a single component of batch processing managing other components in sync with MapReduce might be a difficult task to manage whereas Spark being a wholesome engine all the components is easily manageable in the single cluster. Next, since MapReduce was built in order to solve the ONLY problem of batch processing, for the use cases of real-time processing it might cease to fail whereas Spark works like charm in real-time processing.
Talking about security, MapReduce has better security features in its kitty as it can easily lend the security features from the Hadoop security projects into its use cases without any hassle whereas for Spark, it might be a bit challenging as only shared secret password method is possible in case of authentication and by default the security is turned OFF. Last but not the least, MapReduce is a little more tolerant to failure because of involvement of interaction with hard disk and might not require a full restart in case of any disruption to MapReduce process, but in the case of Spark since operations occur in-memory, it is required to start the process from the initial point in case of process disruption.
Comparison Table of MapReduce vs spark
| Gerne of comparison | MapReduce | Spark |
| Product’s Category | From the introduction, we understood that MapReduce enables the processing of data and hence is majorly a data processing engine. | Spark, on the other hand, is a framework that drives complete analytical solutions or applications and hence making it an obvious choice for data scientists to use this as a data analytics engine. |
| Framework’s Performance and Data Processing | In the case of MapReduce, reading and writing operations are performed from and to a disk thus leading to slowness in the processing speed. | In Spark, the number of read/write cycles is minimized along with storing data in memory allowing it to be 10 times faster. But spark may suffer a major degradation if data doesn’t fit in memory. |
| Latency | As a result of lesser performance than Spark, MapReduce has a higher latency in computing. | Since Spark is faster, it enables developers with low latency computing. |
| Manageability of framework | MapReduce being only a batch engine, other components must be handled separately yet synchronously thus making it difficult to manage. | Spark is a complete data analytics engine, has the capability to perform batch, interactive streaming, and similar component all under the same cluster umbrella and thus easier to manage! |
| Real-time Analysis | MapReduce was built mainly for batch processing and hence fails when used for real-time analytics use cases. | Data coming from real-time live streams like Facebook, Twitter, etc. can be efficiently managed and processed in Spark. |
| Interactive Mode | MapReduce doesn’t provide the gamut of having interactive mode. | In spark it is possible to process the data interactively |
| Security | MapReduce has accessibility to all features of Hadoop security and as a result of this, it is can be easily integrated with other projects of Hadoop Security. MapReduce also supports ASLs. | In Spark, the security is by default set to OFF which might lead to a major security fallback. In the case of authentication, only the shared secret password method is possible in Spark. |
| Tolerance to Failure | In case of crash of MapReduce process, the process is capable of starting from the place where it was left off earlier as it relies on Hard Drives rather than RAMs | In case of crash of Spark process, the processing should start from the beginning and hence becomes less fault-tolerant than MapReduce as it relies of RAM usage. |
Conclusion
Going through all the differences, we do understand that there are some similarities like both are used for processing a vast pool of data, but there is no clear-cut answer on which is better. The answer to either’s usage depends on the problem statement we are trying to solve and pick the best based on the difference to suit the best for the scenario!
Recommended Articles
This is a guide to MapReduce vs spark. Here we discuss the MapReduce vs spark key differences with infographics and comparison table. You may also have a look at the following articles to learn more –
