Updated February 28, 2023

What is Machine Learning Feature Selection?
Feature selection is the process of identifying critical or influential variable from the target variable in the existing features set. The feature selection can be achieved through various algorithms or methodologies like Decision Trees, Linear Regression, and Random Forest, etc. These algorithms help us identify the most important attributes through weightage calculation.
“Feature selection is selecting the most useful features to train the model among existing features”
What is Machine Learning?
Machine Learning is an emerging and futuristic technology that stands as the starting point to create automated innovations with intelligence. It relies on the learning of patterns and trends that occurred in a period. The learning curve of the ML is high, as the implementation gets better with different programming languages with new perspectives. It has a wide range of learning capabilities over the internet. Classifications, Neural networks, Clustering, Model predicting are the core points in Machine Learning. The boom in technology is extended to cloud services and IoT creations.
To solve the problems with cutting edge machine learning technologies, we require a few processes to be carried out sequentially. They are,
- Collecting data points: importing the dataset to the modeling environment.
- Feature Engineering: A process of converting raw data into a structured format i.e. extracting new variables from the raw data. Making the data as ready to use for model training.
- Feature Selection: Picking up the most predictive features from enormous data points in the dataset.
- Model Selection: Picking up the right model for prediction through high weightage.
- Model Prediction: Deriving results from the predicted model.
Let’s see the important stage of machine learning for model prediction.
Why feature Selection is Important in ML?
This process reduces physical intervention in data analysis. It makes the feature interpretation easy and ready to use. The technique helps us to select the most targeted variable correlating with other variables. This reduces the dimension of the set and improves the accuracy of the selected features. Hence the model performance is increased with the selected features.
The three main executions of Feature Selection are,
- Feature selection can be done after data splitting into the train and validation set. To measure the performance of the variable and drop the columns through cross-validation.
- Removing unnecessary features i.e low correlated variables -> having less weightage value.
- Building a model on selected features using methods like statistical approaching, cross-validation, grid-search, etc.
How can you select Data points through feature Selection?
Let’s take a case study on finding Health Type of Cereal prediction using their Nutrition compositions. This dataset has a set of cereals having various nutrients like Fiber, Vitamins, Carbohydrates, and Potassium, etc. Let us juggle inside to know which nutrient contributes high importance as a feature and see how feature selection plays an important role in model prediction. Here, we will see the process of feature selection in the R Language.
Step 1: Data import to the R Environment.
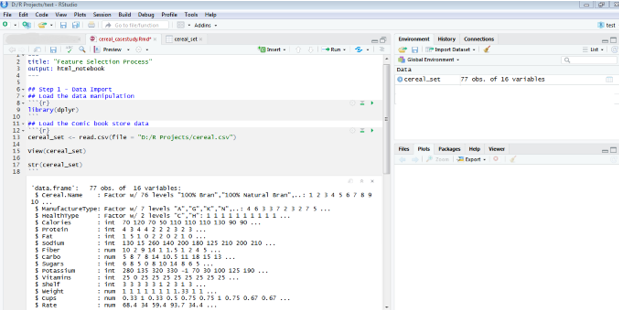
View of Cereal Dataset
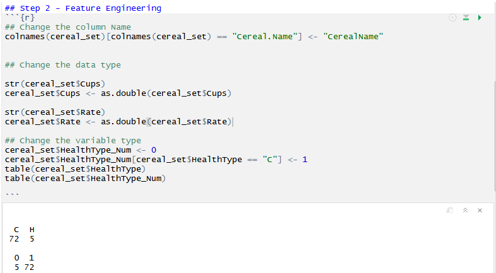
Step 2: Converting the raw data points in structured format i.e. Feature Engineering
Step 3: Feature Selection – Picking up high correlated variables for predicting model
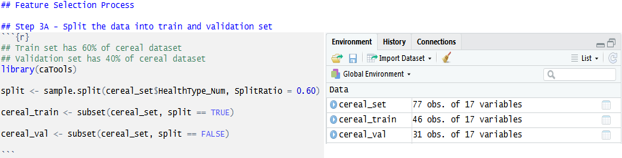
Step 3A: – Split the data into train & validation set
Step 3B: The train set is used for finding the importance and error rate using the RandomForest algorithm. You should see here that Cereal Name and Health Type are eliminated from the randomForest formula. Because the categorical variables with different sets of values are not supported in the algorithm.
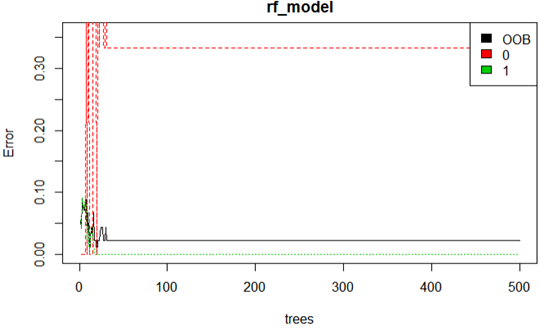
The error rate is represented using plotting. It is plotted based on the correlation values. The red plotting represents there is more number of low correlated values.
Step 3C: Rank the features using their correlations and high importance. Here the features are ranked according to their importance in the training set. And plotted using the ggplot library. The importance is plotted using MeanDecreaseGini.
MeanDecreaseGini is a measure of the purity of a feature which implies whether the featured variable will be useful or not.
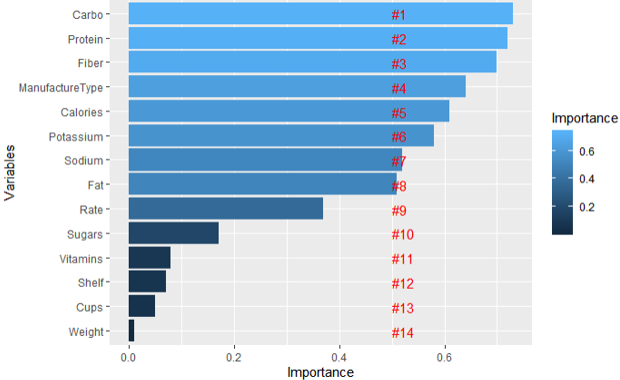
In this graph, we can see Carbohydrates, Protein, Fiber, Type of Manufacturing the cereals, and Calories are the top most important features. These features greatly contribute to the model prediction and decide the Health type of Cereal.
Step 3D: The top 10 variables are ranked according to their importance and ordered down. These 10 variables are considered as selected features and used for model prediction.

Step 3E: There are two methods for feature selection. One can stop here and use the most important features derived from RandomForest, and form formula for model prediction.
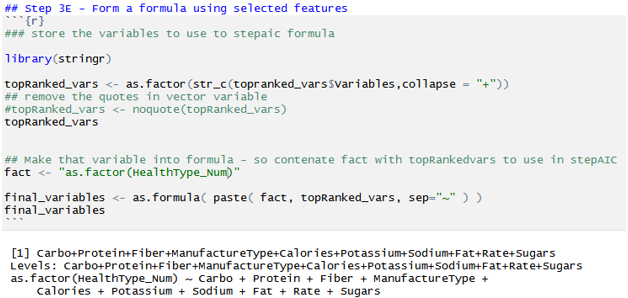
Step 3F: Another method to drill down the feature is the StepAIC method. This method uses reverse engineering and eliminates the low correlated feature further using logistic regression. This greatly helps to use only very high correlated features in the model. And that provides highly accurate results.
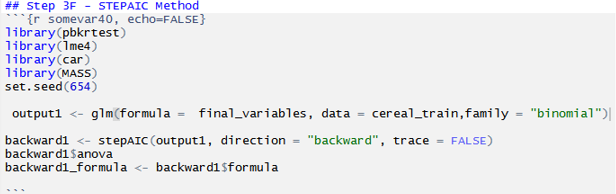

We achieved feature selection through the co-efficient of the variables used in the method. Below is the summarization of the StepAIC method for feature selection.
This summary is based on the logistic regression method.
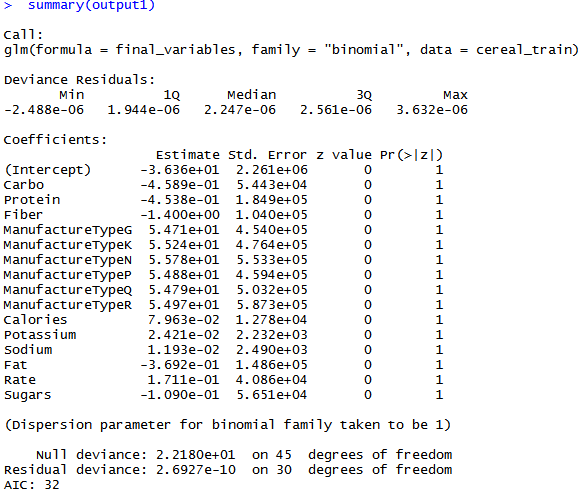
- Lower the AIC value produces efficient results.
- Null deviance represents how well the response is predicted by the trained model with nothing but the intercept value. If the null deviance is small, then the model performs well. The p-value is considered for the measure and checks how well it fits the data model.
- Residual deviance represents how well the response is predicted by the trained model when the predictors i.e. HealthType is included. It is used to see whether the null hypothesis is true or not.
- This summary is based on backward propagation in StepAIC. Eliminating the low correlated values using their weightage.
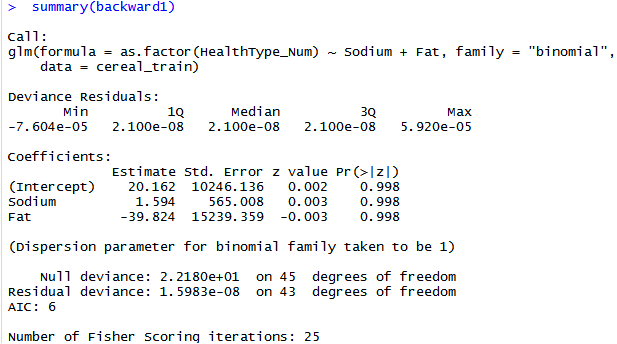
So, the two features of Sodium and Fat are used for modeling.
Conclusion
The feature selection changes according to parameter tuning. There are so many methods to process the feature selection. Here we used two methods and understood how important to select the features and model to get good results. This feature selection process takes a bigger role in machine learning problems to solve the complexity in it.
Recommended Articles
This is a guide to Machine Learning Feature Selection. Here we discuss what is feature selection and machine learning and steps to select data point in feature selection. You can also go through our other related articles to learn more –
