Updated March 6, 2023
Definition of Kafka Replication Factor
Replication Factor in Kafka is basically the multiple copies of data over the multiple brokers. Replication is done to ensure the high availability of data and secures the data loss when the broker fails or unavailable to serve the request. For security reasons, the value of Replication factor should be greater than 1 which shows that the replica of files are stored at the other brokers from where the user can access it in case of failover. Apache Kafka follows the Leader-Follower concept in order to ensure the availability of data in every case. In Apache, Kafka replication takes place at the partition granularity level which means that the multiple copies of data will be present at different brokers using the special partition ahead log.
How does the Replication Factor works in Kafka?
Through the Principle of Replication, Kafka guarantees that no data would be lost in any scenario. If one Broker fails then the data can be retrieved from the other Brokers having copies of that data. Let us understand the Replication Factor and its working in Kafka step by step:
1. There is a special write-ahead log in every partition which stores the messages at their unique offset.

Write-ahead log of partition mechanism
2. Every topic partition in Kafka is replicated ‘n’ number of times ( where n is the replication factor defined by the user) which means that n copies of that partition would be present at the different brokers in the cluster.
3. As Apache Kafka follows the Leader-Follower mechanism, so there is a leader of every topic partition. In the ‘n’ replicas of the topic partition, one is chosen as the Leader and the rest as Followers.
4. Leader takes all the data from the Producers and handles all the read and write operations of the partitions.
5. Followers-only follow the Leader and copies all the data that the Leader has.
6. In order to handle the client request for the particular data, the cluster may get confused from which broker the data needs to be extracted. In order to avoid such confusions following rules are already set:
– For the client request, in the presence of the Leader, only the Leader will serve the request. None of the followers is allowed to serve.
– In case of the failure of the broker having the Leader of the requested Partition, Kafka automatically chooses one of the followers which will take the ownership and become the Leader to serve the client request.
7. The Followers in Kafka are known as ISR (in-sync replicas) and through replication factor multiple ISRs are present for the particular Partition.
8. Leader in Kafka follows a list of its in-sync replicas and it checks their status from time to time. If any follower from the in-sync replica list dies or is unable to copy the Leader in any case, it will be removed from the list. Zookeeper in Kafka determines the Leader and Followers.
9. When the leader is back after the Failover, it will again try to become the Leader and take the position of the substitute Leader.
Kafka allows the Producers to choose for the Acknowledgements in case of data writes and retrieving. These acknowledgments can be set by the Producer depending on the Project severity and requirements. For the no data loss, the Acknowledgement factor ‘aks’ needs to be set to ‘all’ to wait for the acknowledgment of the Leader and all the ISRs.
An important point to note is that anode is considered to be alive if it maintains the session with the Zookeeper and the follower node need not be ‘far behind’ the Leader. For the scenario of far- behind the follower node, various conditions like replica.lag.max.messages, replica.lag.time.max.ms are defined in Kafka.
Example
Let us understand the above explanation of Kafka replication Factor working with the help of its Leader and Followers with the help of an example:
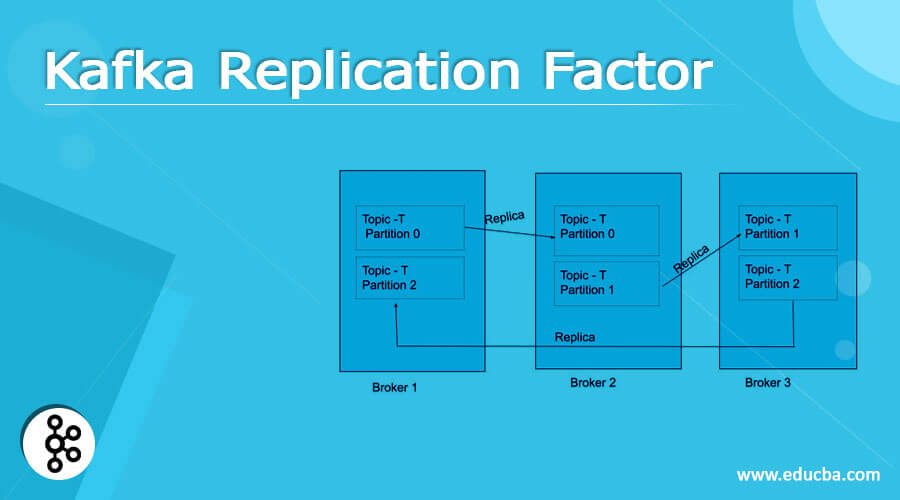
Consider a scenario in which there is a Topic- T having the 3 Partitions: Partition 0, Partition 1, and Partition 2. There are 3 brokers in the cluster which are named Broker 1, Broker 2, and Broker 3.
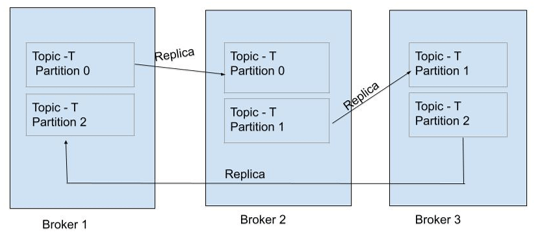
As shown in the above diagram, there are 2 copies of a particular Partition. For Partition 0 of the Topic -T, Broker 1 is the Leader and Broker 2 is the ISR (in-sync Replica). Similarly, for Partition 1 Broker 2 is the Leader and Broker is the ISR and for Partition 2, Broker 3 is the Leader, and Broker 1 is the ISR. There can be ‘n’ number of ISRs for a particular Partition (but to keep it simple, we can consider 1 Leader and 1 ISR for every Partition).
1. For any data related to Partition 0, Broker 1 will take from the Producer and read and write operations of the Partition 0 of Broker 2 (ISR) will take place from it. Producer will directly contact the Leader for any update.
2. For any client request of Partition 0, Broker 1 (Leader) will respond. No ISR (i.e. Broker 2 will respond to the client request of Partition 0 if Broker 1 is alive.
3. If Broker 1 is not available or there is some failover scenario of Broker 1 (Broker 1 goes down) and in that case, a client request for Partition 0, then the Kafka will automatically choose one of the ISR (which is Broker 2 in this case) and make it a Leader which will respond to the client request.
4. If Broker 1 will come back after the failover, it will try to take the position of Broker 2 to become the Leader of Partition 0 again.
Conclusion
The above description clearly explains what the Kafka Replication Factor is and how it works practically in a cluster to serve the client request of the data which is spread over multiple servers. Though this replication process seems to be easy while talking theoretically about it, it is quite challenging in real scenarios when there are varying workloads and client request changes with time. Kafka is an excellent framework when required to spread the data over multiple servers but it is important to understand it well before working on it.
Recommended Articles
This is a guide to Kafka Replication Factor. Here we discuss definition, How does the Replication Factor work in Kafka? example with code implementation. You may also have a look at the following articles to learn more –
