Updated July 8, 2023

Introduction to Kafka Partition
In Kafka, the data is stored in the Kafka topics. The Kafka topic will further be divided into multiple partitions. The actual messages or the data will store in the Kafka partition. It is directly proportional to the parallelism. If we have increased the number of partitions, then we can run multiple parallel jobs on the same Kafka topic. The partition level is also depending on the Kafka broker as well. We cannot define the “n” number of the partition to the Kafka topic. We need to define the partition as per the Kafka broker availability. In partition, the data is stored with the help of keys.
Syntax:
As such, there is no specific syntax available for the Kafka Partition. Generally, we are using the Kafka partition value while creating a new topic or defining the number of partitions on the Kafka commands.
Note 1) While working with the Kafka Partition. We are using the core Kafka commands and Kafka Partition command for the troubleshooting front.
2) At the time of Kafka Partition configuration, we are using the CLI method. But generally, we are using the UI tool only.
How Kafka Partition Works?
The Kafka Partition is useful to define the destination partition of the message. Internally the Kafka partition will work on the key bases i.e. the null key and the hash key. If it sets the null key, then the messages or data will store at any partition or the specific hash key provided then the data will move on to the specific partition. Majorly the Kafka partition is deal with parallelism. If we are increasing the number of partitions, it will also increase the parallel process also.
Below is the list of properties and its value that we can use in the Kafka partition.
| Sr No | Property | Value | Description |
| 1 | broker.id | In the Kafka partition, we need to define the broker id by the non-negative integer id. The broker’s name will include the combination of the hostname as well as the port name. We have used single or multiple brokers as per the requirement. | |
| 2 | log.dirs | /tmp/kafka-logs | It will be a single or multiple Kafka data store location. While creating the new partition, it will be placed in the directory. |
| 3 | port | 6667 | On the 6667 port no, the server will accept the client connections. |
| 4 | zookeeper.connect | null | We need to specify the zookeeper connection in the form of the hostname and the port i.e. 2181. We need to define the multiple zookeeper hostname and ports in the same partition command. Zookeeper is very important while communicating with the Kafka environment. It is the primary thing to communicate with the Kafka environment. |
| 5 | message.max.bytes | 1000000 | With the help of the Kafka partition command, we can also define the maximum size of a message. The same count of messages that the server will receive. It is very important that the same property is in sync with the maximum fetch value with the consumer front. |
| 6 | num.network.threads | 3 | We can define the same value to handle the number of network threads. The same count the server will use for managing the network requests. We don’t need to change this value. |
| 7 | num.io.threads | 8 | We can define the same value to handle the number of input and output threads. We can define the number of threads as per the disk availability. |
| 8 | background.threads | 4 | It will help to manage the various background processes like file deletion. Generally, we are not changing the same value. |
| 9 | queued.max.requests | 500 | With the help of this property, we can define the number of requests that can be queued up. It will help for the I/O threads. |
| 10 | host.name | null | It will help to define the property as the hostname of the Kafka broker. If we have set the same property, then it will only bind with the same address. If the same value will not set, then it will bind with all the present interfaces and will publish on the zookeeper. |
| 11 | advertised.host.name | null | It will help to connect with the multiple Kafka components like the consumers, producers, brokers, etc. As per the configuration, we can define the value like hostname or the ip address. In some cases, we can find it like 0.0.0.0 with the port number. |
| 12 | advertised.port | null | The advertised.port value will give out to the consumers, producers, and brokers. It will help to establish the connections. We can define the value in different forms as well. |
| 13 | socket.send.buffer.bytes | 100 * 1024 | It is also known as the SO_SNDBUFF buffer. It will prefer for server socket connections. |
| 14 | socket.receive.buffer.bytes | 100 * 1024 | It is also known as the SO_RCVBUFF buffer. It will prefer for server socket connections. |
| 15 | socket.request.max.bytes | 100 * 1024 * 1024 | The socket.request.max.bytes value will help to define the request size that the server will allow. |
Examples
In the Kafka environment, we can create a topic to store the messages. As per the Kafka broker availability, we can define the multiple partitions in the Kafka topic.
Note: The default port of the Kafka broker in the cluster mode may verify depending on the Kafka environment.
- The cluster Kafka broker port is “6667”.
- Zookeeper port will be “2181”
- The single Kafka broker port is “9092”
- On TLS or SSL Kafka environment, the port will be “9093”.
Command :
./kafka-topics.sh --create --zookeeper 10.10.132.70:2181 --replication-factor 1 --partitions 3 --topic elearning_kafka
Explanation :
As per the above command, we have created the “elearning_kafka” Kafka topic with the partition value 3. In screenshot 1 (B), we have seen the 3 partition is available in the “elearning_kafka” topic.
Output:

Screenshot 1 (A)
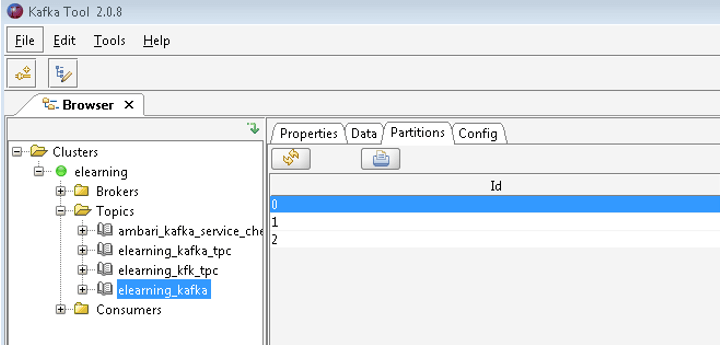
Screenshot 1 (B)
Conclusion
We have seen the uncut concept of “Kafka Partition” with the proper example, explanation, and methods with different outputs. As per the requirement, we can create multiple partitions in the topic. It will increase the parallelism of the get-and-put operation.
Recommended Articles
This is a guide to Kafka Partition. Here we discuss the definition, How Kafka Partition works, and how to implement Kafka Partition. You can also go through our other related articles to learn more –
