Updated April 17, 2023

Introduction to Hierarchical Cluster Python
The following article provides an outline for Hierarchical Cluster Python. The clustering in the hierarchical method allows clustering of the data which are unlabeled. So, all data points which are of the same type should be taken under a specific cluster. That is how the hierarchical clustering will work. So, all the data points which are of very similar characteristics should be associated under the same cluster is the key ideology of hierarchical clustering. Even in some specific cases the values of K-means clustering and hierarchical clustering result may be the exact same. The hierarchical clustering can be made in two ways Agglomerative and Divisive.
How Hierarchical Clustering works?
Given below are the steps involved in Agglomerative Clustering:
- Every datapoint is involved in the cluster of the datapoint. So the total number of clusters needs to be associated to a value called K. Here K will be one point that will be considered for all data points. So the overall number of clusters will be starting a the value K. This K value is a distant value corresponding to the number of data points. So the value of K will be useful in setting the distant values corresponding to the data points.
- The next step is the formation of the cluster. This is a very major step. This step comes after setting the k value. So after the K value is considered the cluster has to be formed by joining two of the data points which are very close. These two closest data points will be resulting to K-1 clusters. This is how the K-1 cluster setup is framed.
- The above steps have to be repeated again and again to form several more clusters. Several more cluster formation is accomplished by joining several other closest data points. These form the K-2 cluster.
- Now the final cluster formation needs to be formed. The final cluster formation expects the most critical step. All data points considered previously has to be taken into account for forming the final cluster. The final cluster involves performing the above three steps on a cycle to set the final cluster. This repetition will lead to one big cluster which will be the final cluster.
- After a single cluster is formed and the single cluster is formulated through values from various other small clusters then the dendograms are useful in dividing into multiple clusters based on the type of problem involved.
- In the below section we will see how the denodograms are taken to place.
- The key item is to identify the distance between the clusters, this means to determine the distance between the clusters the below-given steps can be performed.
- The major consideration is measuring the distance between two data points. This is a very important aspect to consider. We need to measure the distance between two different points which form the sections of the given cluster.
- Next is a considerable opposite of the last statement. According to this the farthest point between the two clusters need to be determined. So the maximum distance between the two clusters has to be identified and determined. This can be done by the below means. The data points associated to the endpoint of the cluster can be considered and then those data points can be used for determining the farthest points of the cluster.
- Next the centroids are expected to be considered. So the centroids of two clusters have to be taken into account and the distance between the centroids have to be calculated. This is the next item to the process section.
- The last point is to identify the mean value, the mean value has to be identified between all possible combinations. This means that all values and combinations have to be considered for determining the points between two clusters and then the mean value associated between these two points have to be calculated. This is done here.
Example of Hierarchical Cluster Python
Given below example shows how to design a hierarchical clustering code and get it executed into a grap output.
Code:
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
Input = np.array([[5,3],
[20,25],
[35,42],
[44,30],
[50,30],
[65,70],
[71,30],
[80,78],
[90,55],
[80,91],])
from sklearn.cluster import AgglomerativeClustering
cluster = AgglomerativeClustering(n_clusters=2, affinity='euclidean', linkage='ward')
cluster.fit_predict(Input)
plt.scatter(Input[:,0],Input[:,1], c=cluster.labels_, cmap='rainbow')
Explanation:
- The process of defining the hierarchical cluster involves the below steps. First matplot lib has to be used through pyplot. The matplot lib is useful in making the graphs associated to the pyplot. So this is the initial important item of the hierarchical clustering process. Then declaration of pandas and numpy will be expected. Next, the input data need is expected to be fed. The numpy array. The numpy array is filled with values and loaded. Next, the agglomerative cluster is designed by means of importing the AgglomerativeClustering from the sklearn library under the cluster item. So from the cluster item of the sklearn library, the agglomerative clustering is performed. This is the critical step in design of these clusters. The next step is the formation of the cluster.
- Next, the clustering has to be performed by calling the Agglomerative clustering method, the clustered value will be stored in the cluster variable. The cluster variable will be having this output value. Then the predict method is used for predicting the output value from the cluster through the fit method. The plt. scatter is used to depict the graphical representation of the output with all the clusters associated to it. So all the clusters will be depicted along with the data points on the graph through the scatter method.
Output:
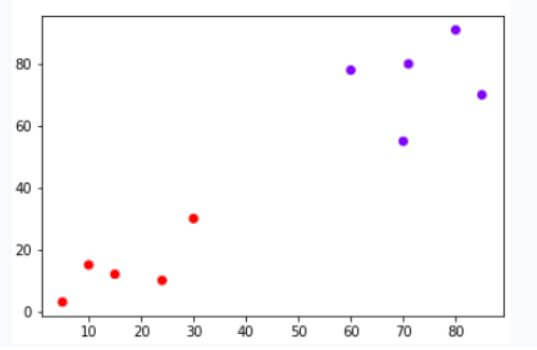
Conclusion
The above-given article clearly shows how the hierarchical clustering can be used for getting the predictions to happen. The how to work section briefly describes the algorithm behind the process and the example shows a real-time example related to this process of performing hierarchical clustering.
Recommended Articles
This is a guide to Hierarchical Cluster Python. Here we discuss the introduction, how hierarchical clustering works? and example. You may also have a look at the following articles to learn more –

