Introduction to HBase Architecture
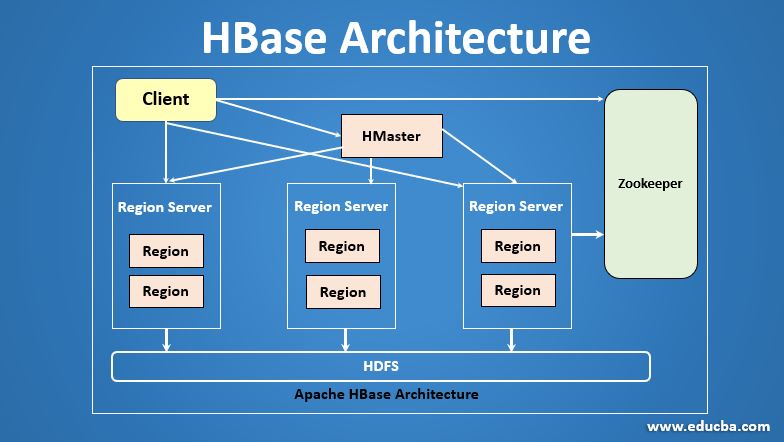
HBase is an open-source, distributed key-value data storage system and column-oriented database with high write output and low latency random read performance. By using HBase, we can perform online real-time analytics. HBase architecture has strong random readability. In HBase, data is sharded physically into what are known as regions. A single region server hosts each region, and one or more regions are responsible for each region server. The HBase Architecture is composed of master-slave servers. The cluster HBase has one Master node called HMaster, and several Region Servers called HRegion Server (HRegion Server). There are multiple regions – regions in each Regional Server.
HDFS Storage Mechanism
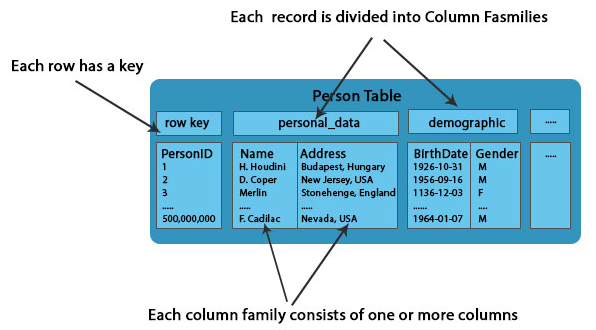
In HDFS, Data is stored in the table, as shown above.
Each row has a key.
Column: It is a collection of data belonging to one column family, which is included inside the row.
Column Family: Each column family consists of one or more columns.
Each table contains a collection of Columns Families. These Columns are not part of the schema.
HBase has Dynamic Columns. Cells within the database can have other columns because they encode the column names internally.
Column Qualifier: Column name is known as the Column qualifier.
HBase Architecture Components
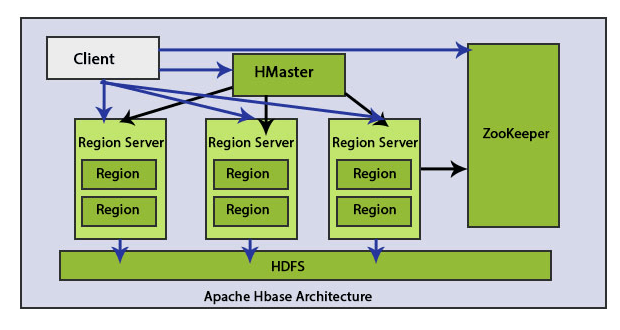
There are central elements in the HBase architecture: HMaster and Region Server. Regional HBase Saving Data.
1. HMaster
The HMaster node is responsible for lightweight tasks such as assigning the region to the server region.
There are some main responsibilities of the Hmaster, which are:
- First, carrying out some administration tasks, including loading, balancing, creating data, updating, deletion, etc.
Responsible for changes in the schema or modifications in META data according to the direction of the client application
- HMaster handles much DDL work on HBase tables.
Some of the methods that HMaster Interface exposes are mainly. META data-oriented methods.
- Table (create, remove, enable, disable, remove table)
- ColumnFamily (add Column, modify Column)
- Region (move, assign)
The client communicates with both HMaster and ZooKeeper bi-directionally. It contacts HRegion servers directly to read and write operations. HMaster assigns regions to regional servers and, in turn, checks regional servers ‘ health status.
2. Region Server
The diagram below gives us a rough idea of the region server.
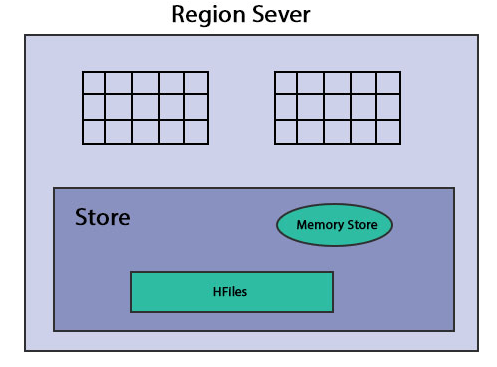
Region Servers are working nodes that handle customers’ requests for reading, writing, updating, and deleting. Region Server is lightweight; it runs at all the cluster Hadoop nodes. The region server’s main task is to save the data in areas and perform customer requests. Another important task of the HBase Region Server is to use the Auto-Sharding method to perform load balancing by dynamically distributing the HBase table when it becomes too large after inserting data.
Multiple HRegion servers can be contacted by HMaster and perform the following functions:
- Managing and Regions hosting
- Automatically split regions
- Handling requests for reading and writing
- Direct customer communication
3. HDFS
HDFS stands for the Hadoop Distributed File System. It stores every file in several blocks and replicates blocks across a Hadoop cluster to maintain fault tolerance. HDFS delivers high fault tolerance and works with low-cost materials. Using cheap commodity hardware to add nodes to the cluster and process & save it will give the customer better results than the existing hardware. HDFS contacts the components of HBase and saves a lot of data in a distributed way.
4. Zookeeper
Zookeeper is an open-source project. HMaster and HRegionServers register themselves with ZooKeeper.
It provides various services like maintaining configuration information, naming, providing distributed synchronization, etc. Distributed synchronization is the process of providing coordination services between nodes to access running applications. It has ephemeral nodes that represent region servers. Master servers use these nodes to search for available servers.
These nodes also serve the purpose of tracking network partitions and server failures. Zookeeper is the interacting medium between the Client region server. The zookeeper is the communication medium if a client wants to communicate with the region server.
How Search Initializes in HBase Architecture?
As you know, the zookeeper saves the location of the META table. Whenever a customer approaches or writes requests for HBase, the procedure is as follows.
The customer finds out from the ZooKeeper how to place the META table. The client then requests the appropriate row key from the META table to access the region server location. With the META table location, the customer caches this information. Please avoid using the META table unless you have relocated or repositioned the area. In that case, the system will request another META server and update the cache. As always, customers do not waste time finding the Region Server location on META Server, so it saves time and speeds up the search process.
Features
It is easy to integrate from the source and destination with Hadoop.
Distributed storage, like HDFS, is supported.
It has a random access feature using an internal Hash Table to store data for faster searches in HDFS files.
Advantages and Disadvantages of HBase Architecture
Below are the advantages and disadvantages:
Advantages of HBase Architecture
Below are mentioned the advantages:
- These can store large data sets.
- We can share the database.
- Gigabytes to petabytes cost-effective
- High availability through replication and failure
Disadvantages of HBase Architecture
Below are mentioned the disadvantages:
- SQL structure does not support
- It does not support transaction
- Only with the key sorted
- Cluster memory problems
Conclusion
Apache HBase represents one of the column-oriented distributed databases in the NoSQL domain. While comparing with Hadoop or Hive, HBase performs better for retrieving fewer records. So, in this article, we discussed HBase architecture and its essential components.
Recommended Articles
This has been a guide to HBase Architecture. Here we discussed the Concept, Components, Features, Advantages, and Disadvantages. You can also go through our other Suggested Articles to learn more –
