Updated March 16, 2023
Introduction to Hadoop DistCp
Hadoop distcp is one of the tools that can be used to perform large inter and intracluster copy operations by using the MapReduce technique for distributing the data, which is handled by the data error handling, recovering, and creating the report datas so that the distcp command called distributed copy tool which invoked the file system copy at each folder of every file will work between the two different clusters.

Overview of Hadoop DistCp
DistCp is the distributed copy tool that mainly helps to interact with the large inter and intracluster copying datas. It primarily converts the list of files and directories to mapped through the map tasks distcp refactor the fix with additional factors, which helps to extend the programming logic. The new paradigms serve and programmatic the datas to improve the performance, which simulates the data legacy behavior as the default views.
Suppose we want to copy the multiple set of files from different or numerous source locations; it’s to abort the operation and show the copy error message between the source and destination collisions resolved in options. The node and data managers will communicate between the source and destination file systems that run in the HDFS system services with the same version of the protocols. It should follow the generic options like configuring the files, which helps track the value declared with the property value, and tracking the file system using commands like fs and passing the source file url and target file location.
-conf <configuration file>,-D <property=value>, -fs<local path|file system URI>, -jt<localpath|jobtracker:port>,-files<f1,f2,f3,..>,-libjars<lib1,lib2,..>
And additionally, we used map sizing to create and declare the size ranges according to the map assigned and comparatively to the number of data bytes ranges. Therefore, the tuning number of maps will reduce the size of both source and destination clusters available between the bandwidth for the short, long and regular running jobs.
Hadoop DistCp Parameters
It has n number of parameters followed by the command options that can be supported using the Hadoop distcp command.
Like some of the below parameters, which have different usages, we called in the Hadoop command-line interface.
- <source>: It mainly denotes the source file data; it may be the URL or another format like file etc.
- <destination>: It denotes the target or destination file data and uses the URL or other formats.
- -p[erbugp]: It has n number of blocks for denoting the chunks, and it specifies the options that split with the data files that can be copied to the parallel location. If the positive set of values and files will be more blocked with the values that achieved to the more number of file chunks denotes the <number-of-blocks-per-chunk> the parameter denotes and identified for destination reassembled operations.
- -i: It denotes that the operations are ignored failures stored in the logs.
- -f<URI list>: This command is mainly used to list the source file in the URL with a fully qualified URI.
- -filelimit<n>: This specified the file limit and denoted the total number of files that satisfied the condition like files <= n.
- -sizelimit<n>: It specified the file total sizes that can be used to validate the condition like <=n bytes.
- <update>: This mainly plays the <source> and <destination> file sizes that can be preceded by using the sync operation. This primarily differs in the source and destination file sizes.
- <overwrite>: This denotes overwriting the file clusters between the semantics to generate the destination paths.
Hadoop DistCp Running Common
Distcp is the tool that helps to perform the large number of datas that can be replicated by using the clusters among the two different clusters. It mainly used the operation called MapReduce for the tasks to implement the distributed copy for a large number of datas stored and retrieved from the backend. The main prerequisites are for the Yarn client, or it contains Yarn that can be installed using the directory like /opt/client. Service users for each component will create the system-based administrator role based on the service requirements. In security mode, the cluster machine will vary to download the keytab file for changing the credentials like password, and other enable inter-cluster data copy functions.
First, we need to log in to the node as the client authentication, and we can run the command called cd client path in the installation directory, which is already mapped on the client. Then we can configure the command like the source file path in the environment variable. Distcp will take the n number of files listed, including single and multiple sets of files that distribute the data between the numerous map tasks that can be copied to the data assigned to the destination path.
Map Reduce mainly uses the distribution data, which handles the error, data recovery, and other reporting areas. Directories and other input areas reduce the map tasks. Copy consumptions and other DistCP classes are used programmatically to construct and initialize the object appropriately.
Hadoop DistCp Copying
The Hadoop distcp copying is worked from cluster1 to cluster2, with different clusters.
Here are some of the below steps to perform the distcp copying operations from Hadoop.
1. In this, we set up the Oracle virtual box cloud in the machine.
2. Next, we download the Cloudera Hadoop software to perform the Hadoop and other related operations.
3. https://downloads.cloudera.com/demo_vm/virtualbox/cloudera-quickstart-vm-5.12.0-0-virtualbox.zip; with the help of this link, we can download the Cloudera in the oracle virtual box.
4. The Hadoop will default be configured in the Cloudera machine.
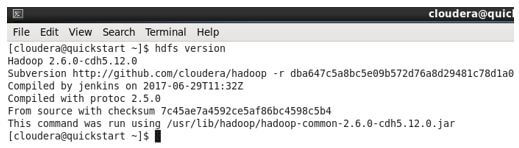
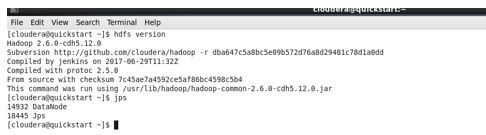
5. Same thing, we have set up the cluster in localmachine like windows or some other machine.
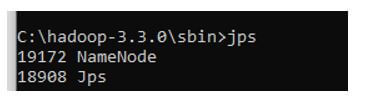
6. Then, we use the distcp command to copy cluster machine1 to cluster machine2.
![]()


Conclusion
Hdfs has many features and default commands for performing file operations in various modes. Among that, distcp is one of the commands that can be used to perform the copy operations from one cluster machine to another cluster machine with different operating systems and hosting machines.
Recommended Articles
This is a guide to Hadoop DistCp. Here we discuss the introduction, overview, parameters, and Hadoop DistCp running common. You may also have a look at the following articles to learn more –
