Updated April 17, 2023

Introduction to GitLab Pipeline
When several jobs are executed stage by stage with the help of code automated in the form of a pipeline is called Gitlab pipeline. There can be numerous jobs in a single stage and these jobs are executed in parallel and if it succeeds, it goes to the next stage. If the pipeline fails, the user should investigate the issue of job failure and correct it so that the pipeline can be executed for the next stage. The pipeline is important for a project that it includes building, testing and deploying the jobs in the work environment and the jobs depends on the user.
Types of GitLab Pipeline
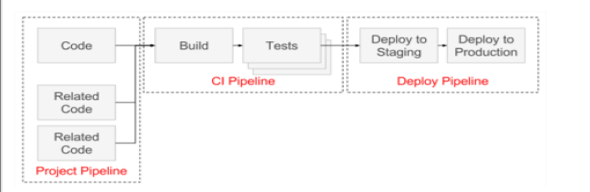
There are three types of Gitlab pipeline such as CI pipeline, Deploy pipeline and Project pipeline. Though these are called types, they belong to a single pipeline and we cannot run the pipeline without these three types are incorporated into the same.
CI Pipeline:
Continuous integration pipeline involves building something from the scratch and testing the same in a development environment. It might occur to the developers to add something after building the application and pushing it into production. This can be done with the help of continuous integration where we can add the code even after it is deployed. This phase includes testing as well where we can test with different approaches in the code.
Deploy Pipeline:
This pipeline helps to deploy the codes or any application to the staging environment or into production. The purpose of this pipeline is to push the code after continuous integration and testing into any environment of the user’s choice. Deployment pipelines can be automated where once the code gets into staging we can push it into production based on our requirements and timelines. The code is taken from the development environment as it is placed by the CI pipeline already.
Project Pipeline:
There can be different projects running on the same Gitlab and it might confuse the users as to which pipeline to be triggered. The project pipeline helps to describe the dependencies of the project and code thus helping in understanding the project. There are API’s used in the pipeline which is triggered automatically and this is specially used for micro-services. This also helps users to understand how the pipeline is moving from one stage to the other in terms of deployment.
Development Workflows:
There are various types of workflows such as branch flow, trunk-based flow and fork based flow.
Branch Flow:
A separate branch is created for each task and when these tasks are ready to be merged into the pipeline, a merge request is created for the pipeline. This helps in making the workflow continuously without any merge conflicts with main branches. Hence, developers can work on separate branches and the main branch will have only tested code thus making continuous integration easy for the developers. When the branches are given proper names, it is easy to track the same and make the work comfortable for the developers.
Trunk – based flow
In this workflow, there is only one branch, which can be probably the main branch where all the developers are working. Here the codes are merged in real-time and hence there is no waiting for other developers to merge it into the main branch. Sometimes developers create short-lived feature branches so that once the coding is done, it is merged into the main branch making the development to be continuous as there will be lesser merge conflicts. This saves time for the developers and the code will be in production within a short duration of time.
Fork–based flow
Forking workflow works differently from the other two workflows in that developers will have their own private repository in the work system. Codes need not be pushed to the main branch by the developers after developing the same as it will be pushed once it is submitted to the central repository. This makes the work really easier in public servers. Write access is not needed for the developers to do the commits and the maintainer can accept the same from developers and merge their code into the repository. The branching system is similar to other workflows where the branches are merged into the central repository directly. This is a distributed workflow that is good for any open-source project.
Visualizing Pipelines
We can see pipeline status in the pipelines tab in Gitlab that shows us the different pipelines running for various projects. The pipeline shows the job status by going into the details of the pipeline. The status of the pipeline helps us to understand whether the jobs got succeeded or not.
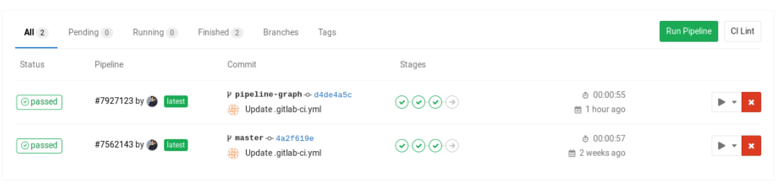
All the relevant jobs of the pipeline can be seen by clicking the pipeline. We can trace the pipeline and if needed, we can erase the records of the same pipeline. There are pipeline graphs that show the time duration, status of the pipeline and pipeline details. Also, we have pipeline widgets to see the merge and commit requests of the pipeline. The overall status of the pipeline can be seen from the job views on the Gitlab page.

Pipeline graphs also help us to delay the jobs if needed and group commonly occurring instances into the same pipeline and visualize the same to know the status. We can sort the jobs based on priority and set the timeline for each pipeline.

GitLab Pipeline
1. Create a project and set it as private or public in GitLab.

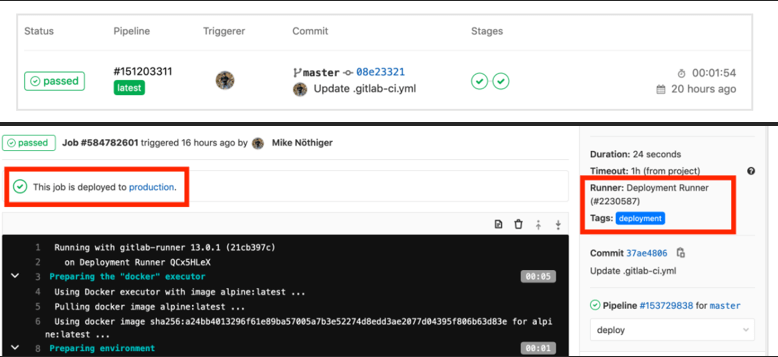
2. Now the server should be saved into GitLab runner so that all jobs running here will have CI/CD configuration. Add user to the server and docker group along with SSH key. Now, gitlab-ci.yml file has to be configured with different stages of jobs. All these have to be in PowerShell format. This is the first Gitlab pipeline and the process continues as explained above.

Conclusion
While working in public servers, we may need to rollback Git pipeline for defective works which can be done in the project overview. Git pipeline has changed the mode of working for developers and the work has been made easy for existing developers and newcomers.
Recommended Articles
This is a guide to GitLab Pipeline. Here we discuss the Introduction and three types of Gitlab pipeline for better understanding. You may also have a look at the following articles to learn more –

