Updated March 13, 2023
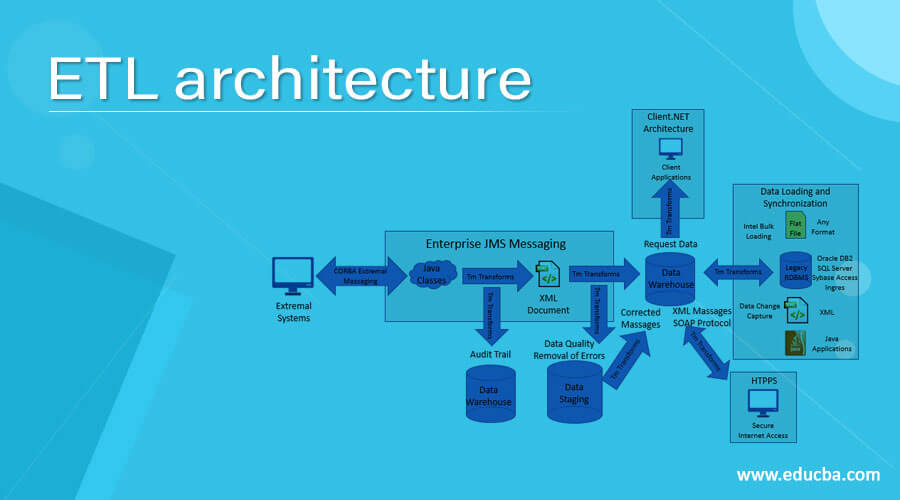
Introduction to ETL architecture
The method by which data are gathered from its source, transformed to achieve the desired objective, and then sent to its intended target is the extract, transform, load, or “ETL.” An efficient ETL infrastructure is important to any company that wants to turn its information into assets, make data-driven decisions, or keep up with cloud data sharing. Data in its “original” form, in other words, the state in which it is created or reported first, is usually not enough to achieve the desired objectives of an organization. A collection of steps must be taken before the data can be used, usually called ETL. In this topic, we are going to learn about ETL architecture.
Architecture of ETL
Extract, Transform, and Load is defined by ETL. The word E-MPAC-TL or Collect, Track, Profile, Analyze, Clean, Transform, and Load is used in the data warehousing world today. This means that ETL relies on the consistency of the data and MetaData.
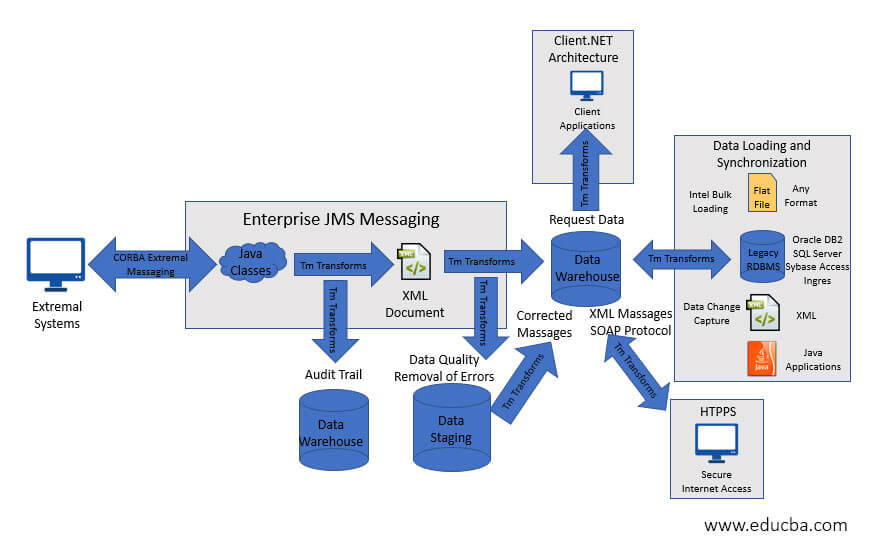
-
Extraction
The main goal is to obtain the data for these sources from the source network as soon as possible and less conveniently. This also notes that for source date/time stamps, database log tables and hybrid depending on the case, the most appropriate method of extraction should be chosen.
-
Transform and Loading
The data must all be converted and loaded to merge the data and then move the merged data to the display area, where the end-user audience will use the front end software. In this context, attention should be on the ETL-tool’s features and its use more effectively. The use of an ETL method is not necessary. The data must be centralized as far as possible instead of being personalized in a medium to large data warehouse environment. ETL should minimize the time of the various source to target creation activities that form the bulk of conventional ETL efforts.
-
Monitoring
The monitoring of data makes it possible to check the data moved in the ETL cycle with two key goals. The data should be reviewed first and foremost. There should be an appropriate balance between checks on the entry data and not slow down the whole ETL cycle when too many checks are completed. The internal method used for screening methodology in Ralph Kimbal can be applied here. This methodology can reliably capture all errors based on a pre-defined set of business rules for metadata and facilitates the recording of these by means of a simple star scheme that allows a view of the changes in data quality over time. Second, ETL efficiency should be centered. This metadata can be linked to all sizes and factual tables and an audit aspect.
-
Quality Assurance
Quality Assurance is a method which can be calculated according to the requirement between different stages, and can check the completeness of the value; do we still have the same number of records or total of particular acts between different stages of ETLs? This data will be stored as metadata. Lastly, the data history in the entire ETL cycle should be foreseen, including error records.
-
Data Profiling
This is used for the processing of source statistics. The aim is to understand the origins of data profiling. The Data Profiling would analyze the content, structure and consistency of the information using analytical techniques by analyzing and validating the data and formats and by detecting and validating redundant data across the data source. The right tool to automate this process is critical to use. It offers a vast array of information.
-
Data Analysis
Data analyzes are used to interpret the effects of the profiled data. Data quality problems, including missing data, incorrect data, invalid information, restriction issues, parent-kid problems including orphaned data, duplicate data, are easier to detect when reviewing the datasets. The results of this assessment must be accurately recorded. The data processing should become the contact tool for coping with unresolved issues between the source and the data warehouse team. The mapping source relies heavily on the consistency of the source analysis.
-
Source Analysis
The aim should not only be on sources but also on the environment, so that the source documentation is obtained. The future of the source applications depends on the current origin of the data, the corresponding data models / metadata repositories and the effective implementation by source owner of the source model and business rules. In order to detect changes that could affect the data store and the associated ETL process, it was important to create regular meetings with owners of the source.
-
Cleansing
The found errors in this section, based on a collection of rules metadata, can be corrected. In this relation, a distinction must be made between records that have been totally or partially rejected and the manual correction of problems or fixing data by correction of inexact data fields, data format modification, etc.
Recommended Articles
This is a guide to ETL architecture. Here we have discussed What is ETL architecture and its components along with their working. You may also have a look at the following articles to learn more –
