What are Embeddings?
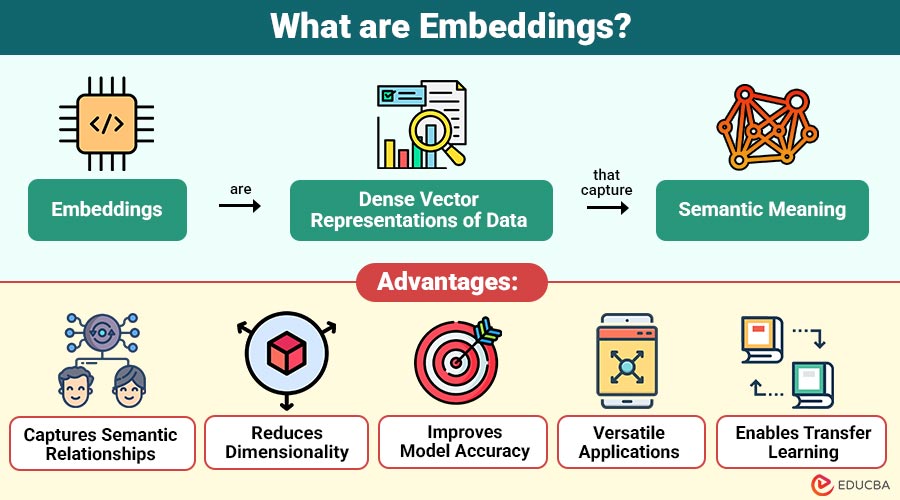
Embeddings are dense vector representations of data that capture semantic meaning. In simple terms, embeddings transform objects like words, images, or users into numerical vectors in a multi-dimensional space.
Unlike traditional representations (such as one-hot encoding), embeddings place similar items closer together in this space.
For example:
- Words like “king” and “queen” will have similar embeddings.
- Words like “apple” (fruit) and “Apple” (company) may have different embeddings depending on context.
This ability to capture relationships makes embeddings extremely powerful in machine learning and artificial intelligence.
Table of Contents:
- Meaning
- Importance
- Types
- Key Differences
- Advantages
- Limitations
- Real-World Applications
- Popular Models
Key Takeaways:
- Embeddings convert complex data into dense vectors that capture semantic relationships and contextual meaning.
- It reduces dimensionality and improve efficiency, enabling faster training and inference of machine learning models.
- It helps machines understand meaning, improving accuracy in NLP search and recommendation systems.
- It enables transfer learning and power applications like search engines, chatbots, and recommendation systems.
Why are Embeddings Important?
Embeddings are important because they enable machines to understand relationships, similarities, and patterns in data. Key reasons include:
1. Dimensionality Reduction
Convert high-dimensional sparse data into compact, efficient vector representations for easier processing.
2. Semantic Understanding
They capture meaning and contextual relationships in data rather than relying only on raw values.
3. Improved Model Performance
Enhances accuracy and effectiveness in NLP models, recommendation systems, and other AI applications.
4. Efficient Computation
They reduce storage requirements and improve computational efficiency, enabling faster model training and inference.
How do Embeddings Work?
Embeddings work by mapping data into a continuous vector space. The process typically involves:
1. Input Data Processing
Raw data, such as text, images, or user interactions, is collected, cleaned, and prepared for embedding model training.
2. Model Training
Machine learning models learn patterns, contextual relationships, and hidden structures from data to generate meaningful embeddings.
3. Vector Representation
Each data point is converted into a dense numerical vector that effectively captures semantic meaning and contextual relationships.
4. Similarity Measurement
Distance metrics like cosine similarity measure how closely two vectors are related in the embedding space.
For Example:
- If two words appear frequently together, their vectors will be closer.
- If two products are often bought together, their embeddings will be similar.
Types of Embeddings
Here are the different types of embeddings used in machine learning and AI to represent data as vectors.
1. Word Embeddings
It is a dense vector representations of words that capture semantic meaning, contextual relationships, and similarity in continuous space.
Use Cases:
- Text classification
- Sentiment analysis
- Language translation
2. Sentence and Document Embeddings
It represents entire sentences or documents as vectors capturing overall semantic meaning and contextual relationships.
Use Cases:
- Semantic search
- Document similarity
- Chatbots
3. Image Embeddings
It converts images into numerical vectors derived from visual features, enabling recognition, comparison, and similarity-based analysis tasks.
Use Cases:
- Image recognition
- Facial recognition
- Visual search
4. User and Item Embeddings
It represents users and products in vector space, enabling personalized recommendations and preference modeling systems.
Use Cases:
- E-commerce recommendations
- Streaming platforms (movies/music)
- Personalized content
5. Graph Embeddings
It encodes nodes and relationships in networks into vectors, supporting social analysis, fraud detection, and knowledge graphs.
Use Cases:
- Social network analysis
- Fraud detection
- Knowledge graphs
Key Differences Between Embeddings and Traditional Encoding
Here are the key differences that highlight how embeddings are more advanced compared to traditional:
| Basis | Embeddings | Traditional Encoding |
| Representation | Dense vectors | Sparse vectors |
| Dimensionality | Low | High |
| Semantic Meaning | Preserved | Not preserved |
| Efficiency | High | Low |
| Use Cases | Advanced AI applications | Basic ML tasks |
Advantages of Embeddings
Below are the advantages given in a simple and structured way:
1. Captures Semantic Relationships
Captures contextual meaning and relationships among data points rather than relying solely on raw representations.
2. Reduces Dimensionality
They convert high-dimensional data into compact vector representations, making storage and computation more efficient.
3. Improves Model Accuracy
Machine learning models using embeddings generally achieve higher accuracy due to better feature representation.
4. Versatile Applications
Are widely used in NLP, computer vision, recommendation systems, and many AI-driven applications.
5. Enables Transfer Learning
Pre-trained embeddings can be reused across tasks, reducing training time and improving performance efficiency.
Limitations of Embeddings
Despite their power in representation learning, it still faces limitations in understanding nuance, fairness, and adaptability across domains.
1. Context Limitations
Some embeddings may fail to capture complex contexts, such as sarcasm or subtle differences in meaning, effectively.
2. Bias in Data
Can inherit biases present in training data and may further reinforce unfair patterns in models.
3. Computational Cost
Training embeddings from scratch can be resource-intensive and require significant computational power and time resources.
4. Interpretability Issues
Vectors are not always easy to interpret directly, making them difficult for humans to understand clearly.
5. Data Dependency
Rely heavily on large, high-quality datasets; poor data quality significantly reduces performance and accuracy.
6. Domain Transfer Challenges
Trained in one domain may not generalize well to other domains or contexts.
Real-World Applications of Embeddings
It is widely used in modern AI systems to convert complex data into meaningful numerical representations for better decision-making.
1. Search Engines
Help search engines understand user intent and return highly relevant, accurate search results efficiently.
2. Chatbots and Virtual Assistants
Enable chatbots to understand user queries better and generate meaningful, context-aware conversational responses.
3. Recommendation Systems
Power’s recommendation systems to suggest personalized products, movies, or music based on user behavior.
4. Fraud Detection
Help detect anomalies in financial transactions by identifying unusual patterns and suspicious behavioral activities.
5. Healthcare
Assist medical research by analyzing patient data to improve disease prediction and treatment outcomes.
Popular Embedding Models
Various embedding models have been developed to represent words and text efficiently while capturing semantic and contextual meaning.
1. Word2Vec
developed by Google, uses neural networks to efficiently learn relationships between words based on context.
2. GloVe (Global Vectors)
focuses on global statistical information about words to effectively capture semantic relationships in large text corpora.
3. FastText
It improves word embeddings by incorporating subword information, enabling better representation of rare and morphologically rich words.
4. BERT Embeddings
Context-aware representations that understand word meaning from the surrounding sentence context are learned dynamically and effectively.
Final Thoughts
Embeddings are a key concept in machine learning that convert complex data into numerical representations, helping machines understand context, relationships, and patterns. They power search engines, chatbots, and recommendation systems, making AI more intelligent and effective. As technology advances, embeddings will play an increasingly important role in AI development.
Frequently Asked Questions (FAQs)
Q1. How are embeddings trained?
Answer: Embeddings are trained using machine learning models (such as neural networks) that learn patterns and relationships from large datasets by predicting context or associations between data points.
Q2. What is cosine similarity in embeddings?
Answer: Cosine similarity is a metric used to measure how similar two embedding vectors are by calculating the angle between them. A smaller angle indicates higher similarity.
Q3. Why do embeddings use dense vectors instead of sparse ones?
Answer: Dense vectors are more efficient and compact, allowing models to process data faster while preserving meaningful relationships between data points.
Q4. Can embeddings be reused?
Answer: Yes, pre-trained embeddings can be reused across multiple tasks, saving time and resources.
Recommended Articles
We hope that this EDUCBA information on “Embeddings” was beneficial to you. You can view EDUCBA’s recommended articles for more information

