Updated May 18, 2023
Difference between dataset vs dataframe
The dataset generally looks like the dataframe, but it is the typed one, so it has some typed compile-time errors with them. At the same time, the dataframe is more expressive and most common structured API. It is simply represented with the table of the data with more rows and columns; the dataset also provides a type-safe view of the data which is returned from the execution of the SQL Query statement dataset is a set of strongly-typed structured datas they familiar with the object-oriented programming languages capture the errors in compile time.
The dataset and dataframe are significant distinctions between the different APIs for working with complex and big data applications.
Dataset:
Generally, the dataset comprises collections of extensive data that we can refer to as tabular data, and these datasets correspond to one or more tables. In that, it will be calculated with every column of the table representing the particular variable, and each row will correspond to the given set of records for the data set. The dataset lists calculate for each type of value using the variables that calculate the height and weight of the object creation, thereby assisting each member of the dataset. We refer to each value as a datum, and datasets comprise collections of documents or files.
Several characteristics will be defined with the data set structure and properties. These include the number and types of attributes and variables with various statistical measures applicable to all values, including numbers, integers, or strings. All the data in the dataset is nominal, meaning it does not include numerical values. The algorithms generate this data, and we use certain types of software for testing purposes.
Dataframe:
In dataframe is similar to a dataset; it is the most common structured API, and it mainly represents the table structure with a set of rows and columns. The data table with rows and columns will calculate the list of columns and the types in those columns representing the schema. The data spreadsheet consists of named columns, but a fundamental difference is that while we use a spreadsheet on a single PC with specified locations, a Spark DataFrame can span thousands of computers. This allows intuitive usage when dealing with large data to fit on a single PC or when performing data computations that would take too long on a single machine.
The dataframe is not only for Spark; other languages, like R, Python, etc, support it. But when we use R and Python, it helps similar differences in the concepts of both dataframes with some exceptions that exist on one machine rather than the other multiple machines.
Head to Head Comparison Between dataset vs dataframe (Infographics)
Below are the top 9 differences between dataset vs dataframe:
Key differences between dataset vs dataframe
The dataset and dataframe have some key differences for performing the operations on the user end. Both play a role in managing complex datasets like big data and other data structures.
Dataset:
The dataset comprises a distributed collection of data elements spread across machines and combined and configured into clusters. The dataset unifies and distributes across other nodes, encompassing structured and unstructured data formats; it may vary with the data sources. The dataset is a combination of RDD and dataframe; also, the original RDD regenerates after transformation. It is the compile-time safety and tuning of the query optimization through the catalyst optimizers like dataframes. When we use an encoder, it handles the data conversion between the objects and the tables, and no need for garbage collection, so it saves memory. It accesses the individual attributes and elements without deserializing the objects.
Dataframe:
In the dataframe, the distributed collection of data organizations into each row and mainly in the columns. It supports structured and semi-structured datas and has various data sources transforming into the dataframe that loses the RDD. It does not have compile-time safety, only detects the runtime error, and it takes the query optimization through the catalyst optimizer; the serialization happens with the memory in the binary format. It manually avoids garbage collection for creating or destroying the objects and operations performed only on the serialized data without deserialization.
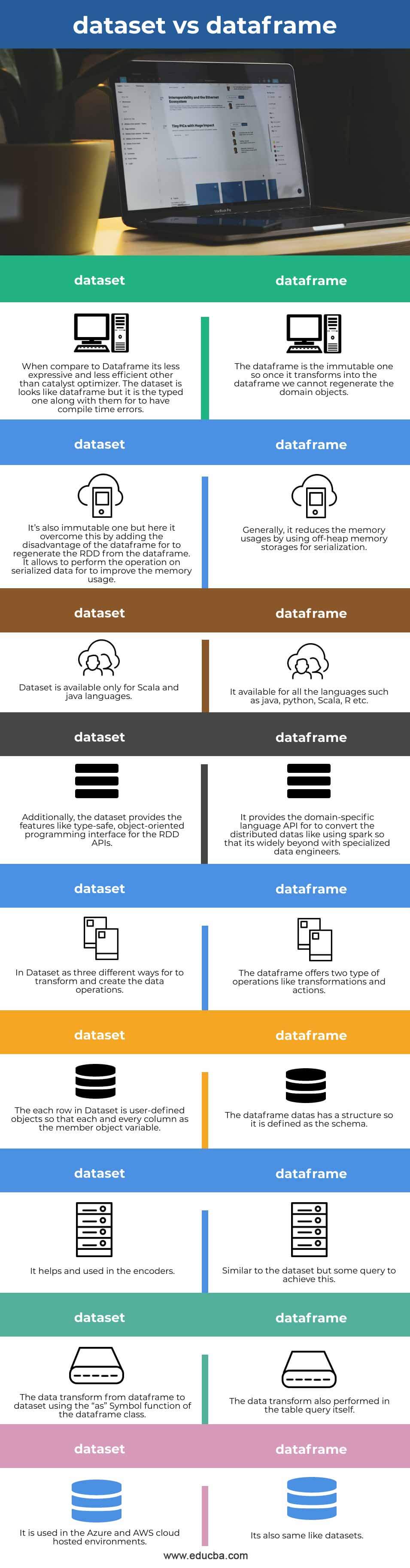
Comparative Table of Dataset vs Dataframe
| Dataset | DataFrame |
| When compared to Dataframe, it’s less expressive and less efficient than a catalyst optimizer. The dataset looks like a dataframe, but it is the typed one along with them to have compile-time errors. | The dataframe is immutable, so once it transforms into the dataframe, we cannot regenerate the domain objects. |
| It’s also immutable, but here it overcomes this by adding the disadvantage of the dataframe for regenerating the RDD from the dataframe. It allows operating on serialized data to improve memory usage. | Generally, it reduces memory usage by using off-heap memory storage for serialization. |
| The dataset is available only for Scala and Java languages. | It is available for all the languages, such as Java, python, scala, R, etc. |
| Additionally, the dataset provides the features like a type-safe, object-oriented programming interface for the RDD APIs. | It provides the domain-specific language API to convert the distributed datas like using Spark, so it’s widely beyond specialized data engineers. |
| In dataset as three different ways to transform and create the data operations. | The dataframe offers two types of operations like transformations and actions. |
| Each row in the dataset is a user-defined object, so every column is the member object variable. | The dataframe datas have a structure, so it is defined as the schema. |
| It helps and is used in the encoders. | Similar to the dataset, but some queries to achieve this. |
| The data transform from dataframe to dataset using the “as” Symbol function of the dataframe class. | The data transform is also performed in the table query itself. |
| It is used in the Azure and AWS cloud-hosted environments. | It is also the same as datasets. |
Conclusion
In conclusion, we use the concepts of dataset and dataframe in complex applications and big dataframes. It had different views when we used the dataframe; we used it to view the data as a set of rows and columns, unlike in the dataset.
Recommended Articles
This is a guide to dataset vs dataframe. Here we discuss dataset vs dataframe key differences with infographics and comparison tables. You may also have a look at the following articles to learn more –
