Updated April 17, 2023

What is Dataset Pytorch?
- Dataset Pytorch is delivered by Pytorch tools that make data loading informal and expectantly, resulting to make the program more understandable. Pytorch involves neural network programming working with the Dataset and DataLoader classes of Pytorch.
- Basically, a Dataset can be defined as a collection of data which is organized in the tabular form data, so it corresponds to one or multiple tables present in the database, where each table column signifies a specific variable and each table row signifies a provided record of the dataset given in the question.
- The domain libraries in Pytorch deliver various pre-loaded datasets like FashionMNIST which subclass the functioning torch.utils.data.Dataset and apply functions particular to the specific data. They can be implemented to benchmark and archetype the model. We can check here Text Datasets, Image Datasets and also Audio Datasets.
Writing Custom Datasets in Pytorch
Even though Pytorch includes previously a lot of important datasets, any users may want to make their personal dataset having self-recorded or else any non-publicly existing data. So executing the datasets by the user may be forthright and it may be required to view the source code for resulting out how the several datasets are applied. A brief overview of what is required to configure a personal dataset is described as follows:
We deliver two abstract classes for the datasets such as torch_geometric.data.InMemoryDataset and torch_geometric.data.Dataset. Here, torch_geometric.data.InMemoryDataset receives from torch_geometric.data.Dataset and also must be implemented if the entire dataset turns into CPU memory.
Succeeding the touch vision agreement, every dataset grows distributed a root folder that designates where the dataset must be warehoused. After that, splitting up the root folder into other two folders named as: first is the raw_dir, here the dataset develops downloaded to and the other one is the processed_dir, here the administered dataset is being protected.
In tally, every dataset can be agreed on a transform, a pre_transformed and other a pre_filter function that are by default None. Where the transform function renovates vigorously the data object beforehand retrieving thus, it is the finest implemented for data augmentation. The function pre_transform relates the conversion afore saving the data objects to the disk thus; it is the finest implemented for weighty pre-computation that requires being just single done once. The function pre_filter can by hand screen out the data objects afore saving. Use cases can comprise the limitation of data objects existence of a particular class.
How to use Datasets Pytorch?
We will explore here the Pytorch dataset object from the ground up having the objective of making a dataset for handling text files and how anyone can go about optimizing the pipeline for a certain task. Pytorch works with two objects named a Dataset and a DataLoader, along with getting comfortable using the training set. We are yet in the stage of preparing data of deep learning project from a high-level perspective such as:
- Arranging the data
- Constructing the model
- Training the model
- Evaluating the model’s results
Let us view what the Torch Dataset consists of:
1. The class Torch Dataset is mainly an abstract class signifying the dataset which agrees the user give the dataset such as an object of a class, relatively than a set of data and labels.
2. The chief job of the class Dataset is to yield a pair of [input, label] each time it is termed. We can define functions inside the class to preprocess the data as well as in the required format that is returned.
3. The class should include two key functions as follows:
_len_(): len function which provides the length or size of the dataset.
_getitem_(): getitem function which provides a training instance or sample from a provided index.
4. We can import the torch dataset from torch.utils.data.Dataset.
The size of the specific dataset may be a grey region occasionally nevertheless it would be also equivalent to the total of samples which is present in the complete dataset. Therefore, if there are 10,000 words or say images, data points or sentences, so on in the dataset, then the _len_() functions must give 10,000 as result.
Dataset Pytorch example (Screenshot)
Let us view an initially simple marginal functioning example by making a Dataset of entire numbers starting from 1 to 10,000 where it will be named as Numbers_Dataset coded below:
Code:
from torch.utils.data import Dataset
# after importing
class Numbers_Dataset(Dataset):
def __init__(self):
self.instances = list(range(1, 1001))
def __len__(self):
return len(self.instances)
def __getitem__(self, idx):
return self.instances[idx]
# putting condition
if __name__ == '__main__':
dataset = Numbers_Dataset()
print(len(dataset))
print(dataset[100])
print(dataset[122:361])Output:
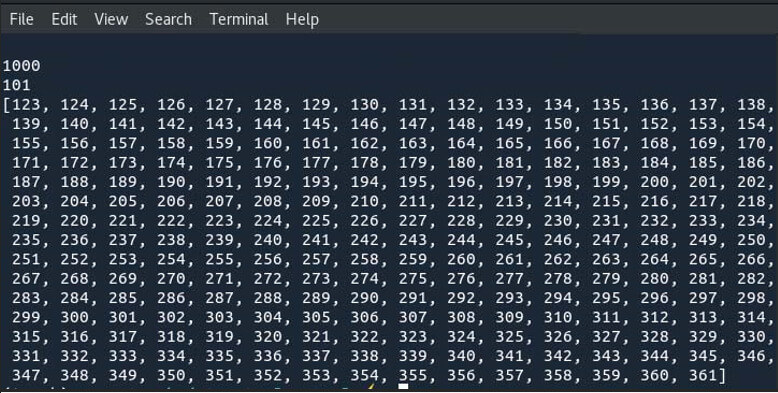
Here, at initial when the Numbers_Dataset is set then, instantly a list named instances is created that stores entire numbers between the range 1 and 1000. Also, the instances name is random, thus you can apply any other names that is comfortable to you. But the overridden functions are understandable and work on the list that was introduced in the constructor. When the file is executed, you can view the values like 1000, 101 and also a list in range 122 and 361 produced out that is the size of the dataset, the value of the data in the dataset at index 100 and the portion of the dataset in the range 121 and 361 correspondingly.
On extending the dataset we can also save total whole numbers in the range of an interval low and high.
Code:
from torch.utils.data import Dataset
#after importing
class Numbers_Dataset(Dataset):
def __init__(self, low, high):
self.instances = list(range(low, high))
def __len__(self):
return len(self.instances)
def __getitem__(self, idx):
return self.instances[idx]
#using condition
if __name__ == '__main__':
dataset = Numbers_Dataset(2821, 8295)
print(len(dataset))
print(dataset[100])
print(dataset[122:361])Output:
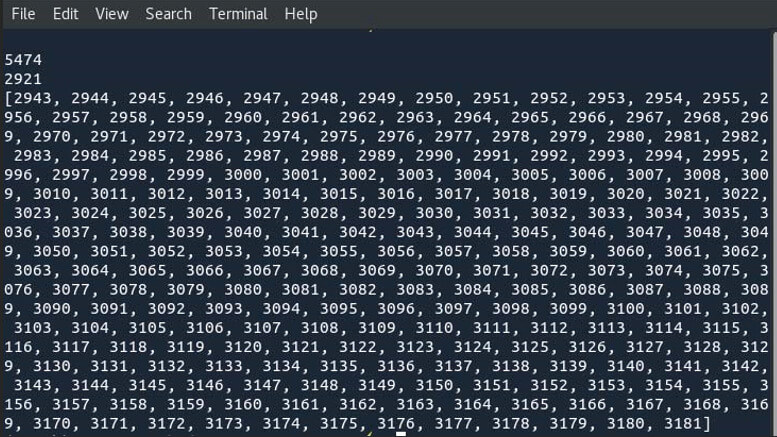
The code written above should display 5474, 2921 with the list of numbers in the range 2943 and 3181.
Conclusion
- Generally, Datasets also includes of an assembly of documents or even files where the dataset provides values for all of the variables like weight and height of an object; for every member of the data set. Here, each value can be recognized as a datum.
- It requires a lot of effort to solve any problem related to machine learning that goes into preparing the data. Therefore, Pytorch delivers several tools for making data loading efficient as well as the code to be understandable. It helps to learn to load and also preprocess data from a non-trivial dataset.
Recommended Articles
We hope that this EDUCBA information on “Dataset Pytorch” was beneficial to you. You can view EDUCBA’s recommended articles for more information.
