What is Data Wrangling?
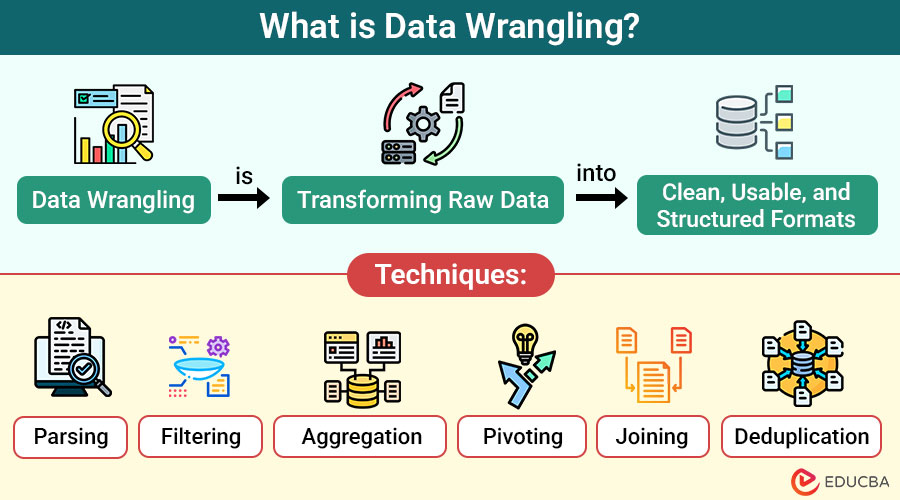
Data wrangling, also known as data munging or data preprocessing, is the process of cleaning, transforming, and arranging raw data into a structured and usable format. It involves tasks like correcting errors, handling missing values, reshaping data, and preparing it for analysis or modeling.
Why the Name?
“Wrangling” means handling or controlling something wild. It fits well because working with messy data can be tough, like taming it into a clean, useful form.
Table of Contents:
Key Takeaways:
- Data wrangling transforms disorganized raw data into structured formats, which is crucial for achieving reliable insights and accurate decision-making.
- Efficient data wrangling reduces analysis time, boosts productivity, and enhances outcomes across various industries and use cases.
- Human judgment remains vital in wrangling, especially for nuanced decisions like imputing values or filtering relevant information.
- Mastering wrangling techniques and tools empowers both technical professionals and non-coders to derive maximum value from data.
Why is Data Wrangling Important?
Mentioned below are the key reasons why cleaning and structuring data are essential for accurate analysis.
1. Raw Data is Often Messy and Inconsistent
Data collected from multiple sources frequently suffers from inconsistencies, errors, missing values, and formatting differences. For example:
- Dates recorded in different formats (MM/DD/YYYY vs. DD-MM-YYYY)
- Customer names with different spellings or casing (e.g., “John Smith” vs. “john smith”)
- Missing fields or null values in datasets
- Duplicates or conflicting records
Without proper wrangling, these issues lead to inaccurate insights and flawed decision-making.
2. It Saves Time During Analysis
Data scientists and analysts can spend up to 80% of their time wrangling data before they can start meaningful analysis. Proper wrangling speeds up this process by automating cleaning steps and creating reusable workflows.
3. Improves Data Quality and Decision Accuracy
High-quality, well-prepared data reduces errors in analysis and machine learning models, increasing the reliability of business decisions.
4. Enables Integration of Multiple Data Sources
Businesses today gather data from multiple systems, including customer relationship management systems, social media platforms, enterprise resource planning systems, and Internet of Things devices. Data wrangling helps merge and reconcile these disparate sources into one cohesive dataset.
5. Provides a Foundation for Advanced Analytics and AI
To work correctly, machine learning models, natural language processing, and other AI methods need clean, well-structured data. Data wrangling is essential before feeding data into these algorithms.
Data Wrangling Process
While the exact process varies by use case, data wrangling typically follows these stages:
1. Data Discovery and Extraction
Before wrangling, it is essential to:
- Understand the data’s source(s), format, size, and quality.
- Extract data from various repositories, including databases, APIs, flat files, and cloud storage.
2. Data Cleaning
This step involves:
- Handling Missing Data: Decide whether to remove incomplete records, fill missing values with means/medians, or flag them.
- Removing Duplicates: Identify and eliminate redundant records.
- Fixing Errors: Correct misspellings, typos, or inconsistent capitalization.
- Filtering Irrelevant Data: Remove columns or rows that don’t add value.
3. Data Transformation
Transforming data into a usable format through:
- Standardization: Converting date formats, currency units, or phone numbers into consistent representations.
- Normalization and Scaling: Adjusting numeric values to a standard scale.
- Feature Engineering: Creating new variables from existing data (e.g., extracting month from date).
- Data Type Conversion: Changing data types (string to date, int to float).
4. Data Enrichment
Adding value by:
- Integrating external data (e.g., geographic coordinates, demographic info).
- Categorizing or binning continuous data into groups.
- Deriving new attributes that improve analysis.
5. Data Validation and Quality Assurance
This step involves:
- Check data against business rules and constraints.
- Validate transformations have not introduced errors.
- Perform exploratory data analysis (EDA) to understand distributions and anomalies.
6. Data Loading and Export
Load the clean, transformed data into a data warehouse, database, or analytics platform.
Common Data Wrangling Techniques
Here are some frequently used data wrangling methods:
1. Parsing
Parsing breaks complex data fields into simpler parts. For example, splitting a full address into street, city, and state helps organize and analyze the data more effectively, enabling easier searching, filtering, and downstream processing.
2. Filtering
Filtering removes rows or columns that do not meet specific criteria. This process helps focus analysis on relevant data, excludes outliers, and handles missing values, thereby improving dataset quality and making insights more precise and meaningful.
3. Aggregation
Aggregation summarizes data by applying functions like sum, average, or count. It condenses detailed records into key metrics, making large datasets easier to interpret and compare, especially useful for generating reports and statistical insights.
4. Pivoting
Pivoting transforms data from a long format to a wide format. It rearranges rows into columns or vice versa, enabling better visualization, comparison, and analysis by reshaping the data to fit specific analytical needs or reporting formats.
5. Joining
Using standard keys, joining merges two or more datasets. It enriches data by linking related information from different tables, facilitating comprehensive analysis and enabling multi-dimensional insights from combined sources.
6. Deduplication
Deduplication removes duplicate records to ensure data accuracy and integrity. By eliminating redundant entries, it reduces errors, prevents inflated counts, and improves the quality of data analysis.
Popular Data Wrangling Tools
Popular tools that make data wrangling efficient and effective.
For Data Professionals:
- Python Pandas: The most popular library for data manipulation with powerful DataFrame objects and a rich set of functions.
- R (dplyr, tidyr): Widely used for data cleaning and reshaping.
- OpenRefine: An open-source tool designed specifically for cleaning messy data.
- Apache Spark: Suitable for large-scale data wrangling across distributed systems.
- SQL: Essential for extracting and transforming data stored in relational databases.
For Business Users:
- Microsoft Excel: Great for small datasets and quick cleaning tasks.
- Trifacta Wrangler: A visual data preparation tool ideal for non-programmers.
- Alteryx: Offers drag-and-drop workflows for ETL and analytics.
- Talend: A data integration platform supporting automated data pipelines.
Challenges in Data Wrangling
Typical challenges encountered during data preparation.
1. Volume and Variety
Processing massive datasets from various formats, such as CSV, JSON, or XML, requires significant computational resources and careful handling to maintain performance and integrity.
2. Unstructured Data
Cleaning and structuring unstructured formats, such as text, images, or audio, is challenging due to the lack of a predefined schema and the complexity of content extraction.
3. Missing and Inconsistent Data
Gaps or inconsistencies in data require careful treatment to avoid introducing bias or distorting results, making data reliability a significant concern.
4. Dynamic Sources
Frequent schema changes or the introduction of new data types can complicate integration, requiring flexible systems to adapt quickly without disrupting pipelines.
5. Lack of Documentation
Insufficient metadata or unclear definitions hinder understanding of datasets, slowing down cleaning efforts and increasing the risk of incorrect assumptions.
6. Time-Consuming
Data wrangling often consumes the majority of the project timeline due to its complexity and the need for precision in transforming raw data into usable information.
Best Practices for Efficient Data Wrangling
Below are the best practices for maintaining high data quality in the workflow.
1. Profile and Explore Data Thoroughly
Analyze data distribution, identify missing values, and detect anomalies early using tools or scripts to thoroughly understand your dataset before starting data cleaning, ensuring targeted and effective data preparation.
2. Automate Repetitive Tasks
Create reusable scripts and pipelines for common cleaning steps to save time, reduce human errors, and increase efficiency, enabling consistent and scalable data wrangling processes.
3. Document Every Step
Keep detailed records of all data transformations and decisions to ensure reproducibility, facilitate auditing, and enhance collaboration among team members working on the dataset.
4. Validate Frequently
Regularly verify intermediate results to detect errors or inconsistencies early, preventing issues from propagating and ensuring the cleaning process maintains data quality throughout.
5. Collaborate with Domain Experts
Work closely with business or subject-matter experts to accurately interpret data, gain context, and make informed cleaning choices that preserve data relevance and accuracy.
6. Use Version Control
Use version control systems, such as Git, to monitor script and data changes, prevent data loss, and facilitate cooperative working with transparent change histories.
Real World Applications
Below are some real-world applications of how industries utilize data wrangling to achieve better outcomes.
1. Marketing
Marketing teams wrangle customer data from CRM systems, social media, and web analytics to create unified customer profiles and improve campaign targeting.
2. Healthcare
Hospitals clean and integrate patient records from various departments to support medical research and personalized treatment.
3. Finance
Banks wrangle transactional data, detect fraud by spotting outliers, and enrich data with external credit scores.
4. E-commerce
Online retailers combine inventory data, customer feedback, and shipping records to optimize logistics and improve customer experience.
Final Thoughts
Data wrangling is essential for any successful data project. Though less glamorous than modeling or visualization, it ensures clean, structured data for accurate analysis. Mastering it leads to faster insights, better decisions, and stronger outcomes. Whether you are a data professional or business user, effective data wrangling transforms raw information into a strategic asset, turning messy data into meaningful, actionable intelligence using proper tools and techniques.
Frequently Asked Questions (FAQs)
Q1. How does data wrangling differ from data cleaning?
Answer: While often used interchangeably, data wrangling encompasses more than just cleaning. Data cleaning focuses on correcting or removing incorrect, incomplete, or irrelevant data. Wrangling, on the other hand, encompasses cleaning, transforming, reshaping, enriching, and loading data for further analysis and interpretation.
Q2. Is data wrangling only relevant for big data or advanced analytics?
Answer: No. Data wrangling is essential for any dataset, large or small. Even basic tasks, such as generating charts in Excel or analyzing customer feedback, require clean and structured data to ensure accurate results.
Q3. Can data wrangling be fully automated?
Answer: Some parts of data wrangling—like removing duplicates or converting formats—can be automated using scripts or tools. However, many decisions (like how to handle missing values or what data is irrelevant) require human judgment, especially when domain knowledge is involved.
Q4. Do I need programming skills to do data wrangling?
Answer: You do not always need programming skills for data wrangling. Many low-code and no-code tools enable non-programmers to efficiently clean, transform, and organize data with ease.
Recommended Articles
We hope that this EDUCBA information on “Data Wrangling” was beneficial to you. You can view EDUCBA’s recommended articles for more information.

