What is Synthetic Data?
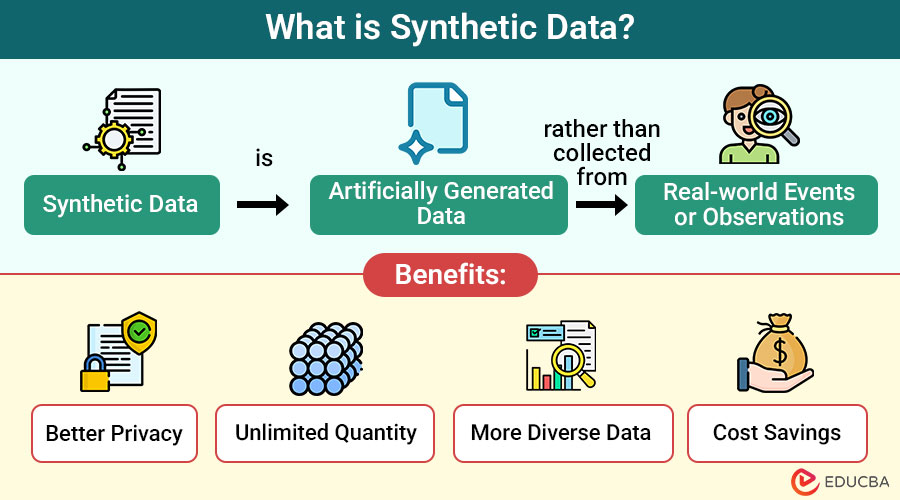
Synthetic data refers to the data that is artificially generated rather than collected from real-world events or observations. It is created using algorithms and simulations to resemble real data in structure, format, and statistical properties, but it contains no actual information about real individuals or events.
This data can take many forms:
- Tabular data for databases and spreadsheets
- Time-series data for financial applications
- Text data for natural language processing (NLP)
- Image and video data for computer vision
Table of Contents:
- Meaning
- Why Synthetic Data Matters?
- How is Synthetic Data Generated?
- Benefits
- Real World Examples
- Challenges
- Future
Key Takeaways:
- Synthetic data actively mimics real-world data using artificial creation methods and excludes personal details to ensure stronger privacy protections.
- It enables the generation of large, customizable datasets that help train AI models efficiently, especially where real data is limited or costly.
- It can help reduce biases in datasets by allowing balanced representation of underrepresented groups or scenarios.
- Despite its advantages, developers must carefully validate and ethically manage data to ensure realism and responsible use.
Why Synthetic Data Matters?
The growing need to overcome several limitations and risks in using real-world data fuels the rise of synthetic data:
1. Privacy and Compliance
Strict guidelines for collecting and releasing personal data are enforced by data privacy legislation, including the CCPA, GDPR, and HIPAA. Real user data often contains sensitive details that require anonymization or restrictions. This data, by design, contains no real personal information, enabling organizations to share and use data without risking privacy violations.
2. Data Scarcity and Cost
High-quality, labeled datasets for training AI models can be scarce or expensive. Real data may not exist sufficiently for emerging technologies or niche domains. This data generation allows companies to create vast amounts of customized data tailored to their needs, drastically reducing costs and time.
3. Bias Reduction
Real-world data often contains biases that can lead to the development of unfair or inaccurate AI models. By carefully designing, developers can balance datasets to ensure fair representation across demographics or scenarios, helping to build more ethical and robust AI systems.
4. Safety and Risk-Free Testing
It can be dangerous and impractical to use real data for testing in delicate industries like healthcare, finance, or autonomous driving. It eliminates the need to put real people or systems in danger by offering a controlled and safe environment for testing and verification.
How is Synthetic Data Generated?
There are several approaches to generating the data, depending on the use case:
1. Rule-Based Systems
These use predefined logic and statistical models to generate data. For example, generating synthetic customer data using rules like name, age, income, and purchase behavior distributions.
2. Generative Adversarial Networks (GANs)
GANs are among the most popular techniques for generating synthetic images, videos, and tabular data. A GAN involves two neural networks—the generator and the discriminator—that compete with each other. The discriminator seeks to distinguish between actual and fake data, while the generator aims to generate realistic data. The generator gradually develops the ability to create incredibly lifelike synthetic data.
3. Variational Autoencoders (VAEs)
VAEs learn the underlying structure of the data and use probabilistic techniques to generate new instances. They are particularly effective in applications like image generation and anomaly detection.
4. Simulations
In areas like robotics and autonomous driving, simulated environments generate synthetic data. These simulations are often physics-based and can recreate millions of scenarios that would be hard to capture in the real world.
Benefits of Synthetic Data
Here are some of the most significant benefits:
1. Better privacy
It eliminates risks by avoiding real personal information, ensuring confidentiality while maintaining data usefulness.
2. Unlimited quantity
Developers can generate data without limitations, providing vast training material for AI models.
3. More diverse data
Enables coverage of rare, unusual, or underrepresented cases, effectively improving model robustness and reducing bias.
4. Cost savings
Reduces expenses by eliminating the need for costly real-world data collection, annotation, and management.
Real World Examples of Synthetic Data
Synthetic data is rapidly gaining traction across numerous sectors. Here are some of the most prominent real-world examples:
1. Healthcare
Medical data is extremely sensitive and protected. Synthetic data allows researchers and developers to train algorithms for disease detection, drug discovery, and patient monitoring without violating privacy laws. For example, researchers can use synthetic MRI scans to train diagnostic models.
2. Autonomous Vehicles
Companies like Tesla and Waymo utilize data to train self-driving cars in rare or hazardous scenarios, such as a child running into the street or driving through heavy fog. These events are difficult (and unsafe) to capture in real life, but easy to simulate.
3. Finance
Financial institutions use synthetic data to simulate customer behaviors, test fraud detection systems, or stress-test economic models—all without exposing real customer information or breaching regulations.
4. Retail and E-Commerce
Retailers use synthetic customer data to test recommendation engines, demand forecasting tools, and marketing algorithms. This allows them to iterate quickly and innovate safely.
5. Cybersecurity
Cybersecurity professionals use synthetic network traffic to test intrusion detection systems and simulate cyberattacks. This enables more robust security systems without putting actual infrastructure at risk.
Challenges of Synthetic Data
Despite its advantages, synthetic data is not without its challenges:
1. Realism and Fidelity
If synthetic data is not realistic enough, it can mislead AI models, resulting in poor performance in the real world. High fidelity is crucial, especially in high-stakes domains like healthcare or finance.
2. Model Overfitting
Training on synthetic data that is too similar to the generated patterns might lead to overfitting, where the model learns the synthetic patterns too well but fails on real-world data.
3. Validation Complexity
How to evaluate the “truthfulness” of synthetic data? Validating its statistical properties and ensuring it reflects real-world phenomena can be tricky.
4. Ethical and Legal Grey Areas
While synthetic data sidesteps some privacy issues, it still raises questions. For instance, can synthetic versions of real people’s faces or voices be used ethically? What if deepfake technologies exploit synthetic data?
Future of Synthetic Data
The field is evolving rapidly. Key trends shaping its future include:
1. Data-Centric AI Development
The AI community is gradually shifting from model-centric to data-centric development. It will play a pivotal role here, improving the quality of training datasets, rather than endlessly tweaking model architectures.
2. Synthetic Data Marketplaces
We are seeing the emergence of platforms where these datasets can be bought and sold. Quality standards, regulation, and interoperability will become key discussion topics as the market matures.
3. Integration with Federated Learning
In privacy-focused fields, synthetic data and federated learning may combine to deliver even stronger guarantees. Federated learning trains models without centralizing data, and datasets can fill gaps where real data is insufficient.
4. AI Regulation and Compliance
Governments and regulatory bodies may soon mandate the use of this data in specific contexts, mainly where privacy and data protection laws apply. This will encourage broader adoption and innovation.
Final Thoughts
Synthetic data is no longer a futuristic concept but a practical tool reshaping the AI landscape. From ensuring privacy and reducing bias to accelerating innovation across sectors, it offers a compelling solution to many of the challenges posed by real-world data. As with all technology, the key lies in responsible use. It is not a silver bullet, but when integrated thoughtfully, it becomes a cornerstone of trustworthy, scalable, and ethical AI.
Frequently Asked Questions (FAQs)
Q1. How does synthetic data protect privacy better than anonymized real data?
Answer: Data scientists generate data from scratch without using any real personal information, eliminating the re-identification risk often present in anonymized datasets.
Q2. Can synthetic data be copyrighted?
Answer: In most jurisdictions, creators can copyright the data if they apply enough original effort or creativity in generating it. However, datasets generated purely by AI may face legal gray areas regarding authorship. Always check local IP laws if planning to license or sell datasets.
Q3. How does synthetic data interact with real-time systems?
Answer: Synthetic data is helpful for training and testing, but it is usually not used in production with real-time systems. However, it can simulate edge cases in live simulations to stress-test or pre-train systems before deployment.
Q4. Do synthetic datasets require labeling?
Answer: Not in the traditional sense. You can automatically embed labels during generation since you generate synthetic data with complete control. This removes the need for manual annotation and significantly speeds up supervised machine learning workflows.
Recommended Articles
We hope that this EDUCBA information on “Synthetic Data” was beneficial to you. You can view EDUCBA’s recommended articles for more information.

