Updated February 18, 2023

Introduction to Cloudera Impala
Cloudera Impala is an integrated part of Cloudera and is supported by Cloudera Enterprise. It is an open-source analytical tool under Apache License for Massive parallel processing on databases for Hadoop applications. It lets Business Analysts get insights into the data through BI, exploratory analytics, and high-performance standards meant for interactive computing. It also enables users to issue low latency SQL queries stored in Hadoop HDFS and HBase without any data movement or transformations. It is integrated with Hadoop using the same file and data formats, security, resource management, and metadata by Hive, MapReduce, Apache Pig, and other Hadoop software.
Why Cloudera Impala?
Hundred of Cloudera customers use Impala to power up BI and analytical workload for faster time value. SQL queries that used to run overnight are now being executed in about 3 seconds.
This fast response enables fine-tuning of analytic queries rather than jobs associated with SQL Hadoop technologies.
- It integrates with the existing CDH ecosystem, i.e., data can be stored, shared, and accessed using various solutions with CDH.
- It provides access to the data stored without requiring Java skills for the MapReduce job. It can access data directly from the Hadoop file system. In addition, it provides SQL front end in accessing data in the HBase database system or the Amazon S3.
- It returns results within seconds or a few minutes instead of the minutes or hours that are usually required for queries to be completed.
- It uses Parquet file format, i.e., a columnar data storage layout optimized for large queries.
- It is an open-source platform under Apache License, and users can integrate with BI tools like Pentaho, Tableau, Zoom data, and Micro Strategy.
- It also supports various file formats such as Sequence file, RCFile, LZO, and Parquet.
Connecting Cloudera Impala
Cloudera Impala can be connected via DSN and Web, along with a few authentication modes.
Let us check how Impala can be connected with DSN:
1. DSN Connectivity
At first, the user needs to create a database instance.
Select the Impala version from the Database connection type Dropdown.
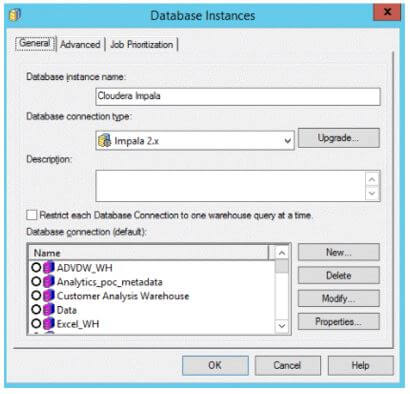
Click on OK and Next to go to Database connection.
Now create a Database connection that will point to the correct DSN.
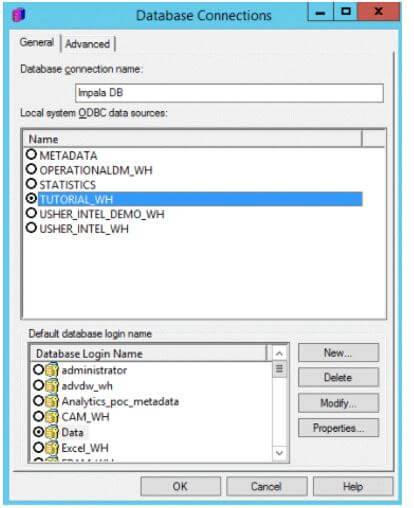
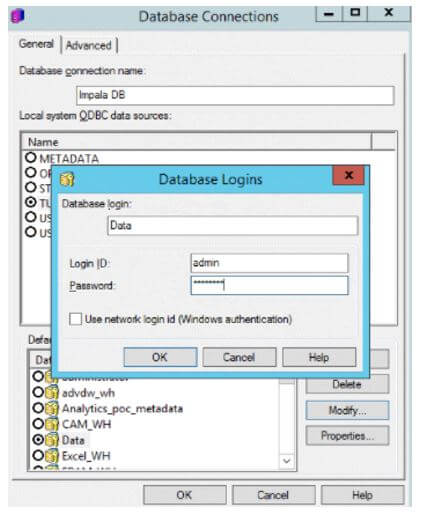
Click on “New..” beside the Database login name.
Hence, configure and save the login credentials.
2. Web Connectivity
- At First, click on New data from the Dataset pane.
- Search and Select Impala in the “Connect to Data dialog” and select either Cloudera Impala connector or Cloudera Impala.
- From “Import options,” select the action that is best suited to the dataset (Building query, Typing query, or Selecting tables)
- Click on the “Plus icon” beside Data Sources.
- Complete the data source information and DSN less data source.
- Then, click on Save
3. Setting up Connection to Cloudera Impala Database
- Install driver on your system to get access to Cloudera Impala’s connector. Check the system requirements. http://support.spotfire.com/sr_spotfire_dataconnectors.asp and find the correct driver.
- To add a new Cloudera Impala connection to the library, Under Tools – Go to Manage Data Connections.
- Select Add New – Data Connection; under it, select Cloudera Impala.
- To add a new connection to the analysis, Select File – Add data tables.
- Then, click on Add. Next, select Connection to – Cloudera Impala.
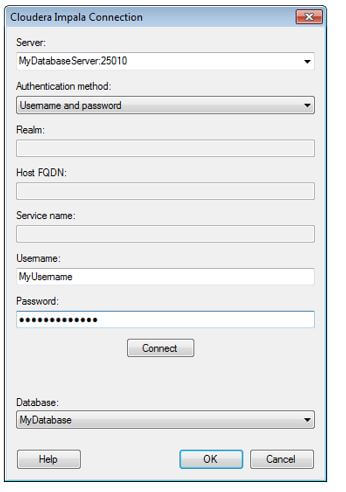
The authentication method used when logging into the database includes forms like Kerberos Authentication, No authentication, Username only authentication, Username, password-only authentication, and Username and password authentication with SSL. As a user, if we are planning to set up Impala into production, pre-planning is required for hardware setup with sufficient capacity such that the cluster topology is optimal for queries in Cloudera Impala and ETL process and schema design follow the best practices.
As Impala depends on software and hardware availability and its configurations, let us look through a few pre-requisites below:
- Product Compatibility Matrix refers to the compatibility among various versions of Cloudera Manager, CDH, and its multiple components.
- Supported Operating System: All relevant operating systems and the versions of Impala are the same, corresponding to CDH platforms.
- Hive Metastore and Configuration: Impala can operate with data stored in hive and use the same infrastructure for tracking metadata for schema objects. MySQL or PostgreSQL and Hive are the pre-requisites, hive being optional in a few cases.
- Java Dependencies: Cloudera Impala is written in C++ but uses Java to communicate with various other Hadoop components.
- Network Configurations: Cloudera Impala completes tasks on local data instead of using network connections for remote data. Impala matches the hostname provided for each Impala daemon with the IP address of each node by resolving the hostname. In most use cases, Impala can automatically detect and work correctly if the user wants to set the hostname explicitly by setting the hostname flag.
Hardware Requirements: Memory allocation for Cloudera Impala should be consistent across Impala nodes. The single executor of Impala with a lower memory limit than others can become a bottleneck, leading to suboptimal performance. - User Account Requirements: Cloudera Impala will create and use the user and group name as “impala.” None have the right to delete this user or the group or modify its permissions. Cloudera Impala should not run as a root user, better performance can be achieved using direct reads, but the root is not permitted for using direct reads. Hence, running Impala as root will affect the performance negatively. Default, any user can connect with Impala and access the associated databases and tables.
Conclusion
We have seen what Cloudera Impala means and how it relates to Apache Hadoop, Hive, SQL queries, databases, CDH, and other components. We have also listed it to be considered for Analytics and Business analysts being so keen on using this Impala. Have listed how it can be connected view DSN and Web, with applicable authentication. Also, see how it can be connected to databases to work with queries, etc. Finally, I have seen the pre-requisites to set up Impala into production.
Recommended Articles
This is a guide to Cloudera Impala. Here we discuss the introduction and connecting Cloudera impala for better understanding. You may also have a look at the following articles to learn more –
