
Introduction to Azure Data Factory
Azure data factory is a platform to integrate and orchestrate the complex process of creating an ETL (Extract Transform Load) pipeline and automate the data movement. It is used to create a transform process on the structured or unstructured raw data so that users can analyze the data and use processed data to provide actionable business insight. Data factory is used to give meaning to big data stored in a storage system. It helps in data movement and performs a transformation on big-scale data.
Functions of Azure Data Factory
Azure data factory is an ETL service based in the cloud, so it helps users in creating an ETL pipeline to load data and perform a transformation on it and also make data movement automatic. So using data factory data engineers can schedule the workflow based on the required time. Here we will see how Azure data factory works to create such data-driven end-to-end ETL pipeline which in turn helps data engineers:
1. Connect and Collect
Azure storage systems may have data of different volumes and format data can be organized or unorganized arriving from different sources like Relational databases, file shares, and SFTP servers, etc. So the first thing a user has to do is connect all the data originating sources and then need to move all this data to a central repository for processing. Data factory uses the Copy Activity process from the data pipeline to copy and ingest data to a storage location in the cloud or on-premise so that users can perform further analysis on data.
2. Transform and Enrich
After data is ingested to the machines in the central repository, the next step is to do data processing and transformation. To perform activities like data transformation and process as part of a data pipeline azure data factory uses ADF mapping data flows so that developer or data engineer can create and manage the directed acyclic graph (DAG) created during the execution of Spark jobs. If a user is writing code to perform transformation ADF can use external big data tools like Hadoop, Spark, HDInsight, etc. with computing services in azure.
3. CI/CD and Publish
Data factory has support for DevOps and GitHub so that developers can run CI/CD processes on the developed code and improve the ETL process incrementally and once the data end-to-end pipeline is ready with all ETL processes it publishes the end product. It helps in loading business-ready data to the final SQL or NoSql database so that businesses can create reports and draw actionable insight from the data.
4. Monitor
Users can monitor the build and deploy ETL data-pipeline and scheduled activities in the data factory as it has built-in support from monitoring. The data factory has Azure monitor platform in the azure portal to handle the logs and health of the deployed data pipeline.
Components of Azure Data Factory
Azure data factory is mainly composed of four key components which work together to create an end-to-end workflow:
- Pipeline: It is created to perform a specific task by composing the different activities in the task in a single workflow. Activities in the pipeline can be data ingestion (Copy data to Azure) -> data processing (Perform Hive Query). Using pipeline as a single task user can schedule the task and manage all the activities in a single process also it is used to run multiple operation parallel.
- Activity: It is a specific action performed on the data in a pipeline like the transformation or ingestion of the data. Each pipeline can have one or more activities in it. If the data is copied from one source to the destination using Copy Monitor then it is a data movement activity. If data transformation is performed on the data using a hive query or spark job then it is a data transformation activity.
- Datasets: It is basically collected data users required which are used as input for the ETL process. Datasets have different formats; they can be in JSON, CSV, ORC, or text format.
- Linked Services: It has information on the different data sources and the data factory uses this information to connect to data originating sources. It is mainly used to locate the data stores in the machines and also represent the compute services for the activity to be executed like running spark jobs on spark clusters or running hive queries using the hive services from the cloud.
How to Create Azure Data Factory?
Given below shows how to create azure data factory:
1. Login into the Azure Portal by clicking on the below link use valid login credential:
https://portal.azure.com/learn.docs.microsoft.com
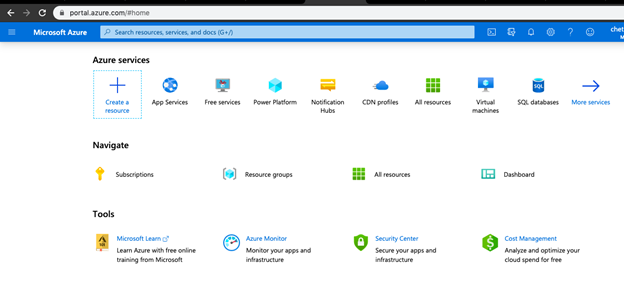
2. Now select the Create a resource option from the azure portal menu page.

3. From the Create a resource page select Analytics from the left pane:
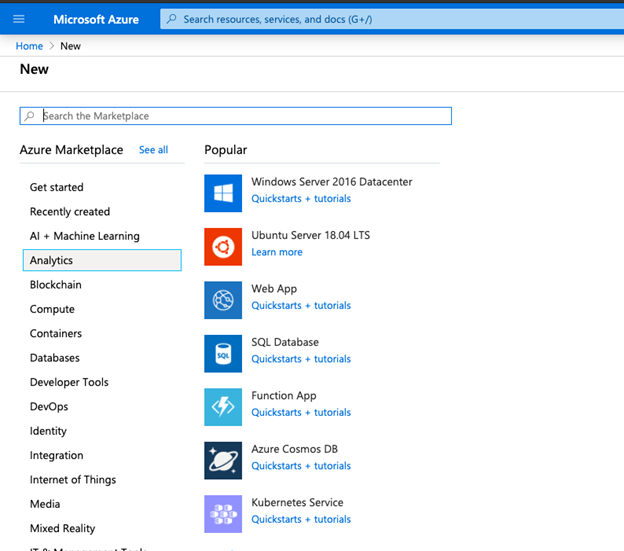
4. On selecting Analytics you will see Data Factory on the left pane select the Data Factory.

5. Now, here on New Data Factory page, you can enter the details as required by your application.
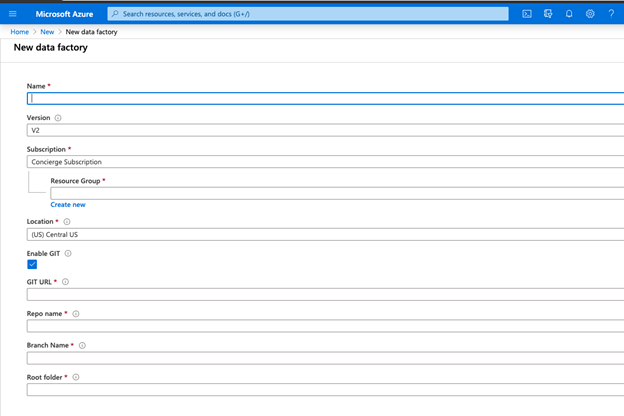
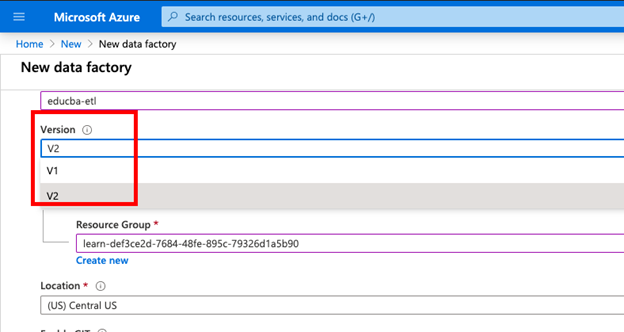
6. You have option to choose version in the Version dropdown based on requirement you can choose V1 or V2:
7. In the Subscription, field selects your Azure Subscription.
8. In Location, drop-down select the location to store your metadata in the data factory.
9. Also, you can provide your GitHub location by enabling the Enable Git option so that CI/CD process can run it based on users requirements and users can disable the same.
10. Now click on the create button on the page.
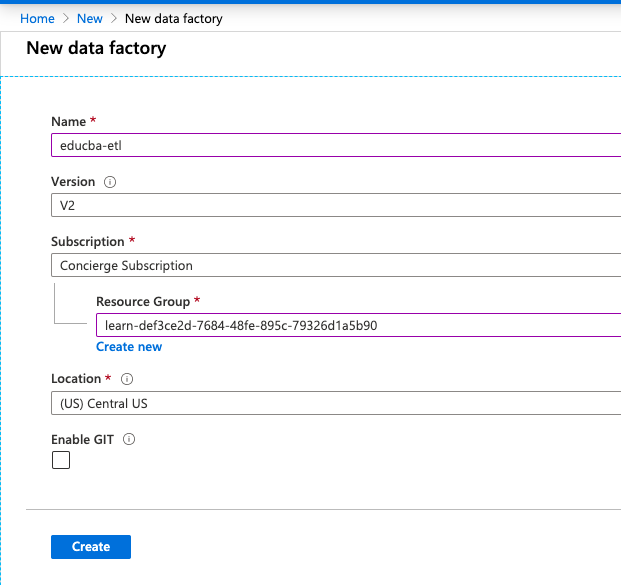
It will start deploying the Data factory:
11. Once Deployment is complete and the Data factory is created successfully below page will populate:
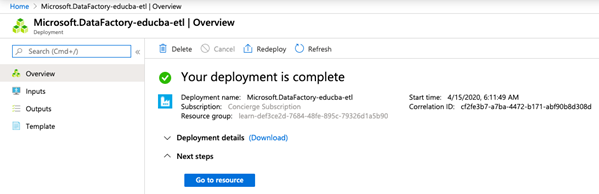
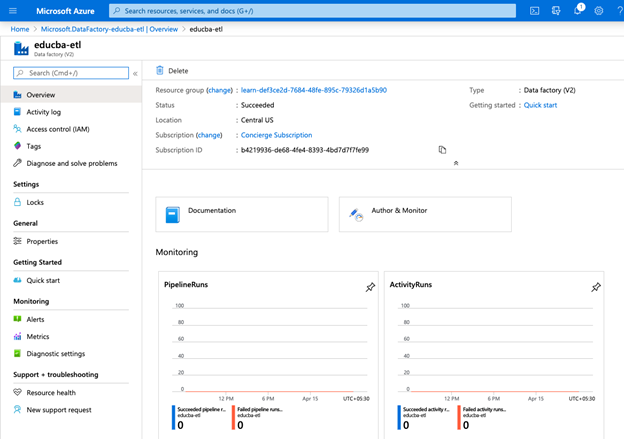
12. Click on Go to resource to validate.
Features of Azure Data Factory
- It has built-in features to create an ETL pipeline so that data can be transferred between files, relation or non-relational databases whether data is on cloud or on-premises machines.
- It has features to schedule and monitor the workflows using azure monitor also it supports event-based flow due to its workflow scheduling capability.
- It provides data security by encrypting data automatically while copying or sharing data with other networks.
- It has the feature of scalability to handle large data as Azure data factory was developed to handle data used in big data technology. It also has time-slicing and parallelism features to move large data using batch processing.
- To create and configure a data pipeline users can use the Azure portals and most of the configuration is written in JSON files so that data engineers or developers need minimum coding experience.
Conclusion
The Data factory in Microsoft Azure helps to manage and create ETL pipelines for big data. Azure Data Factory tools combine Cloud with Big Data technology which is the two innovative fields in today’s era to move any organization towards the future and draw valuable information from the data.
Recommended Articles
This is a guide to Azure Data Factory. Here we discuss the introduction to Azure Data Factory and its different components, functions and features. You can also go through our other suggested articles to learn more –

