Updated February 18, 2023
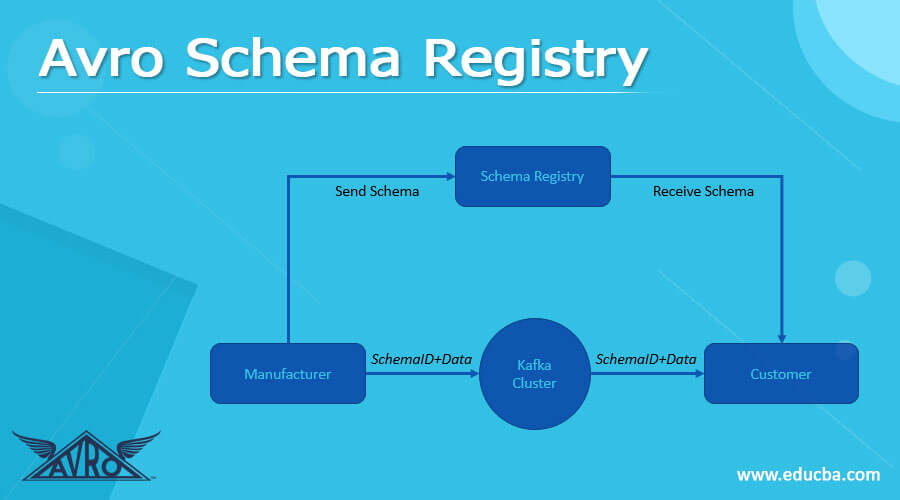
Introduction to Avro Schema Registry
The Avro schema registry is defined as the registry that can supply a RESTful interface, an architectural system controlling the Avro schema. It authorizes the preservation of the history of the schema, which is interpreted, and the schema registry can join the schema inspection for Kafka; we can configure similarity settings for managing the schema growth with Avro. Furthermore, the Kafka Avro can have a serializer in which its manufacturer and customers can utilize the serialization of Kafka Avro for handling the schema management, its records, and the schema registry.
Overview of Avro Schema Registry
The Avro schema registry can run differently from the Kafka broker in which the manufacturer and customer can communicate to display the data. It can support the confluent RESTful interface for reserving and giving out the Avro schema. It can reserve the details about schemas in the form of a list; its application can rely on the API and anticipate the updates as per the compatibility and updates. It can also ensure that the contract between the manufacturer and customer will not be broken in, which it can support as the middle schema management, and it can also examine the compatibility of the schema.
Why Avro Schema Registry?
Kafka can able to generate records or messages in Avro record; at the primary stage, Kafka can only able to transmit data in byte format, and Kafka cannot perform any verification in which it does not become aware of which kind of data it is dispatching or encountering, either it is a string, or it is an integer,
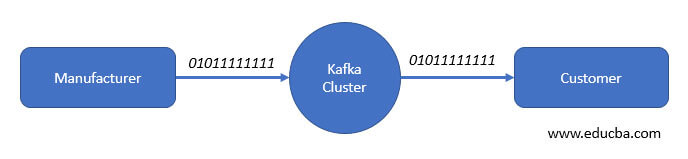
In the above figure, the manufacturer dispatches data in byte format to the Kafka cluster, and the customer also receives that data in byte format. So because of this nature, the manufacturer and customer can not be able to interact directly with each other. But if the customer wanted to know the kind of data the manufacturer is sending for deserialization. So let us assume that if the manufacturer dispatches the unpleasant data and Kafka will send that as it is, the customer will be disturbed.
Hence, the schema registry approaches the scenario, so a type of application comes before the Kafka cluster. It can control the dispersal of schemas to the manufacturer and customer by reserving the same schema in the local cache of it.
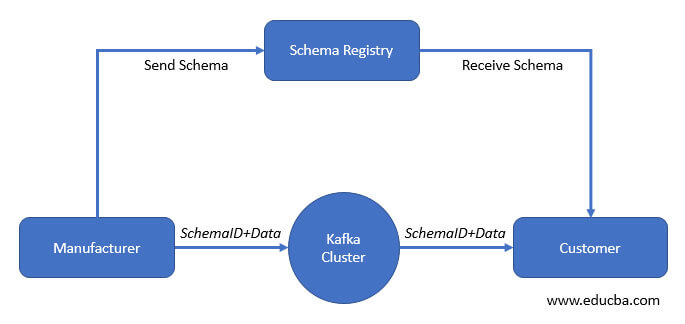
In the above figure, the schema registry is in use, so before dispatching data to the Kafka cluster, the manufacturer can able to check data with the schema registry; if the schema is present, then it will allow to serialize the data and dispatch it back to the Kafka in binary format, if not then it files cache in the schema registry when the customer receive the schema with ID then it has good communication.
How does Schema Registry work in Avro?
Let us see the working of the schema registry in avro, in which the schema registry can exist before the Kafka cluster so the manufacturer/producer can communicate with Kafka to bring out the schema with key-value. Similarly, they can communicate with the schema registry related to the dispatching and receiving schemas, which can have the data model.
So the schema registry has stages for reserving the data under the mechanism; for the verification purpose manufacturer will give a schema ID to every schema, data, and ID that has been sent to the schema registry, then the customer can ask for a schema with proper ID to the schema registry, if the ID is valid, then schema registry can provide the schema, and if the ID is invalid then schema registry can file a cache; hence manufacturer and customer can able to communicate properly with each other.
Authentication Avro Schema Registry
Schema registry has been structured for users to provide authentication by giving userID and password with the help of a basic authentication system,
- Perform the configuration for authentication as shown below,

The configuration of ‘authentication.roles’ can describe the list of users, and they will be authorized users for retrieving the schema registry in which users can be in the role which has been assigned as admin, developer, user, and senior user; they can be configured as given below,
![]()
- The configuration of ‘authentication.realm’ will have to be equivalent to the configuration of ‘jaas_config.conf’, in which it can describe the server authentication, so the user should be passed while the server is starting,

- Example of ‘jaas_config.conf’:
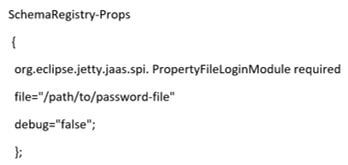
- We have to allocate the ‘SchemaRegistry-Props’ properties segment to the ‘authentication.realm’ configuration setting
![]()
Avro Schema Registry Setup
For the installation of the Avro schema registry,
- First, enter the confluent.io, or we enter the confluent Kafka in the browser, then the related site will get then click on useful site.
- Then we can get two options as given in the screenshot; we have to download self-managed software,
- After that, we will get a registration window; we have to fill it out and click on the start free.
- Then install it, and then from the desktop icon, we can open that file; after that, with the help of the command prompt, we can execute the queries.
- We have to open the etc/schema-registry/schema-registry.properties file in the browser. Then, we must modify Zookeeper or Kafka broker data and the related configuration.
- Then we can able to perform queries in command prompt such as,
![]()
- We can able to start the schema registry by using the command,
![]()
- If we wanted to stop the registry, then we have to perform a query as,
![]()
- We can able to check the status by using the below query,
![]()
Conclusion
This article concludes that the schema registry can provide authentication and valid customer data for better availability. We have also discussed why the schema registry is necessary, so this article will help understand the Avro schema registry concept.
Recommended Articles
This is a guide to Avro Schema Registry. Here we discuss the introduction and how Schema Registry works in Avro along with the setup. You may also have a look at the following articles to learn more –

