Updated April 27, 2023

Difference Between Apache Nifi vs Apache Spark
Apache Nifi (the short form of NiagaraFiles) is another software project aiming to automate the data flow between software systems. The design is based on a flow-based programming model that provides features, including operating with cluster ability. It is easy to use, reliable, and a powerful system to process and distribute data. It supports scalable directed graphs for data routing, system mediation, and transformation logic. Apache Spark is a cluster computing open-source framework that aims to provide an interface for programming an entire set of clusters with implicit fault tolerance and data parallelism. It uses RDDs (Resilient Distributed Datasets) and processes the data as Discretized Streams, which are further utilized for analytical purposes.
Head-to-Head Comparison Between Apache Nifi vs Apache Spark (Infographics)
Below are the top 9 Comparision Between Apache Nifi vs Apache Spark:
Key Differences Between Apache Nifi vs Apache Spark
The differences between Apache Nifi and Apache Spark are explained in the points presented below:
- Apache Nifi is a data ingestion tool that delivers an easy-to-use, powerful, and reliable system to simplify processing and distributing data over resources. In contrast, Apache Spark is an extremely fast cluster computing technology designed for quicker computation by efficiently using interactive queries in memory management and stream processing capabilities.
- Apache Nifi works in standalone and cluster modes, whereas Apache Spark works well in local or standalone modes, Mesos, Yarn, and other big data cluster modes.
- Features of Apache Nifi include guaranteed delivery of data, efficient data buffering, Prioritized queuing, Flow Specific QoS, Data Provenance, Roll buffer recovery, Visual command and control, Flow templates, Security, and Parallel Streaming capabilities. In contrast, features of apache spark include Lightning fast speed processing capability, Multilingual, In-memory computing, efficient utilization of commodity hardware systems, Advanced Analytics, and Efficient integration capability.
- Apache Nifi provides visualization capabilities and drag-and-drop features for better readability and overall system understanding. Conventional techniques and processes can easily manage and govern the data flow. In contrast, in the case of Apache Spark’s case, a cluster management system like Ambari is needed to view these kinds of visualizations. Apache Spark in itself does not provide visualization capabilities and is only good as far as programming is concerned. It is a very convenient and stable system for processing huge amounts of data.
- The limitation of Apache Nifi is related to what is its advantage. The only drag-and-drop feature limits the ability to scale and provide robustness when integrating it with other components and tools. In contrast, in the case of Apache Spark, the primary limitation comes with using extensive commodity hardware, and managing them becomes a tedious task at times. The other reported restriction comes along with its streaming capabilities related to Discretized Stream and Windowed or batch stream, where the transformation of RDDs to Data frames and Data Sets provides a cause for instability at times.
Apache Nifi vs Apache Spark Comparision Table
Given below is the Comparision Table of Apache Nifi vs Apache Spark:
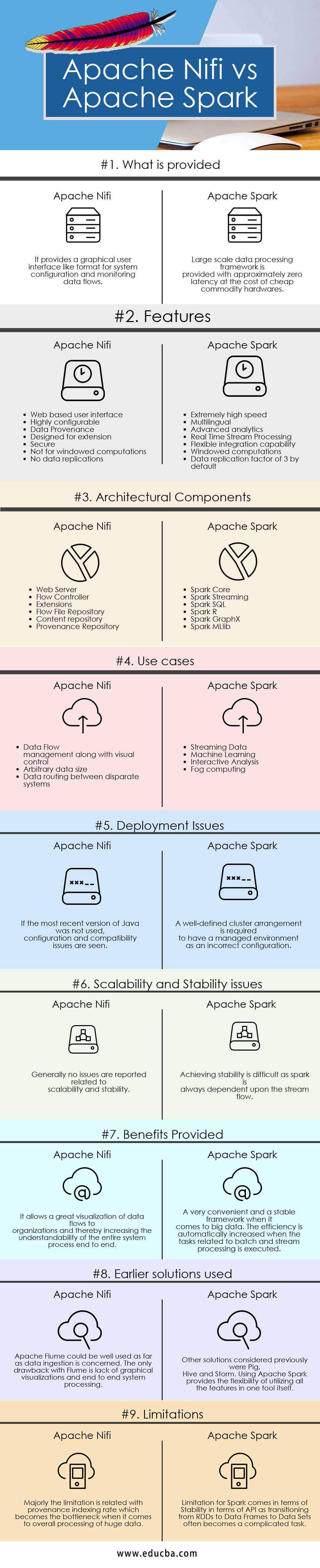
| Basis of Comparison | Apache Nifi | Apache Spark |
| What is provided | It provides a graphical user interface like a format for system configuration and monitoring data flows. | A large-scale data processing framework is provided with approximately zero latency at the cost of cheap commodity hardware. |
| Features |
|
|
| Architectural Components |
|
|
| Use cases |
|
|
| Deployment Issues | Config and compatibility issues are seen if the most recent version of Java was not used. | A well-defined cluster arrangement is required to have a managed environment as an incorrect configuration. |
| Scalability and Stability issues | Generally, no problems are reported related to scalability and Stability | Achieving Stability is difficult as a spark is always dependent upon the streamflow. |
| Benefits provided | It allows a great visualization of data flows to organizations, thereby increasing the understandability of the entire system process. | A very convenient and stable framework when it comes to big data. The efficiency is automatically increased when the tasks related to batch and stream processing are executed. |
| Earlier solutions used | Apache Flume could be well used as far as data ingestion is concerned. The only drawback with Flume is the lack of graphical visualizations and end-to-end system processing. | Other solutions considered previously were Pig, Hive, and Storm. Apache Spark provides the flexibility of utilizing all the features in one tool. |
| Limitations | Majorly the limitation is related to the provenance indexing rate, which becomes the bottleneck when it comes to the overall processing of massive amounts of data. | Limitation for Spark comes in terms of Stability in terms of API, as transitioning from RDDs to Data Frames to Data Sets often becomes a complicated task. |
Conclusion
To conclude the post, it can be said that Apache Spark is a heavy warhorse, whereas Apache Nifi is a nimble racehorse. Both have their benefits and limitations for use in their respective areas. It would be best if you decided the right tool for your business. Stay tuned to our blog for more articles about newer big data technologies.
Recommended Articles
This has been a guide to Apache Nifi vs Apache Spark. Here we have discussed Apache Nifi vs Apache Spark head-to-head comparison, key differences, and a comparison table. You may also look at the following articles to learn more –
