Updated March 16, 2023

Introduction to Weka Data Mining
Basically, Weka is nothing but the collection of different machine learning algorithms which is used for data mining. Weka data mining contains different tools for classification, regression, and clustering with data mining rules. Weka is a free open-source tool used for data preprocessing as well as the implementation of different machine algorithms. In another word, we can say that it is used to solve the real-world problems of data mining.
Key Takeaways
- It is one of the most powerful tools used to develop a machine learning model which is based on real-world problems.
- Weka provides the platform to implement the different types of machine learning algorithms.
- It is free to open source, and portable so we can easily implement it.
What is Weka Data Mining?
It is a set-up of AI programming created at the University Of Waikato, New Zealand. The program is written in Java. It contains a collection of perception devices and calculations for information examination and prescient demonstration combined with graphical UI. Weka upholds a few standard information mining undertakings, all the more explicitly, information pre-handling, bunching, characterization, relapsing, representation, and element choice.
Data mining basically used to analyze huge amounts of data, or we can say that it is a process to work with raw data sets which are used to make the business logins and it will be helpful to increase the business. Inside the data mining, we can use any type of input such as CSV files, data from the warehouse, CRM, normal data and text files, etc.
Normally data mining has different steps such as the acquisition of data, cleaning of data, and integration of dataset. Because we collect the data from different datasets, we need to avoid data duplication and raw data. The different models can be applied to the equivalent dataset. We can then look at the results of various models and select the best that meets our prerequisite. Consequently, the utilization of Weka results in a speedier improvement of AI models in general.
Why Use Weka Data Mining?
Let’s see why we need to implement Weka data mining:
- It is freely available for users means we can use a public license.
- It is totally portable which means it is totally developed with the help of Java programming, so we can execute on any platform in today’s world to solve real-time problems with the help of data mining concepts.
- Basically, it includes all data mining processing as well as all modeling techniques.
- The most important use, it provides the graphical user interface so we can easily interact.
How to Install Weka?
First, we need to ensure the requirement for installation, so we can install Weka on different operating systems such as Windows, MAC OS, etc. We required a minimum of Java 8 or above and a stable version of Weka.
- First download Weka from the official website. After completion of the download, double-click on the setup file.
- Now accept the license agreement as shown in the below screenshot.
- After that, we need to select the component and click on the next button as shown in the below screenshot.
- In the next step, we need to select the location otherwise we can go with the default location and click on the install button as shown in the below screenshot.

- Finally, we need to click on the finish button as shown in the below screenshot.
- After successful installation, we get the below screen.

- In the above screenshot, we can see the different categories of applications and can select any as per our requirements.
Weka Data Mining Tool
Basically, it contains the visualization, so implementation, prediction as well analysis is very easy. It also provides a graphical user interface, users can easily access all the required functions. Weka data mining tool is a totally Java based application, the modeling algorithm can easily be implemented through Java, but we must ensure that during installation we need Java version 8 or above.
Weka Data Mining Features
Given below are the different weka data mining features:
1. Pre-processing
This is an essential feature of Weka because most of the time collected data is raw, so there are major chances to contain redundant data or we can say that empty data which contains garbage data as well added some extra data into the system, so it decreases the performance of algorithm we must need to preprocess raw data to get a better result. Weka provides this type of filter to the user.
2. Classification
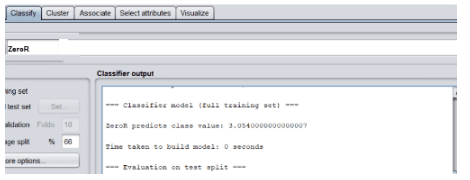
Classification is another feature that is used in machine learning. During the implementation of the machine learning algorithm, we need to assign classes or different categories of data. After the selection of a category or classification, we need to choose options for the training set for classification such as training set, supplied test set, and cross-validation. The sample classifies as shown in the below screenshot.
3. Clustering
Clustering is used to manage the different groups into a similar category of item. In this category, all data have the same kind of property, but it belongs to different clusters as shown below.

We can also see the graph of the above clustering as shown in the below screenshot.

4. Associate
It is a rule used to determine the relationship between the data and datasets. In another word, we can say that if the statement defines the probability of the relationship.
5. Select Attributes
We know that raw data contains several meaningless attributes, so at that time we need to select only valuable attributes and remove unwanted attributes.
6. Visualize
It is used to show the matrix and graph of the model, the sample graph as shown in the below screenshot.

FAQ
Given below are the FAQs mentioned:
Q 1. Why did we use Weka for data mining?
Answer: Basically, it provides the visualization to see the data, as well as we are also able to apply different models to the same dataset, so the comparison will be easy.
Q 2. Which programming language do we use in Weka?
Answer: Normally Weka is based on Java but while installing we must require a minimum of 8 java versions.
Q 3. How can we predict the result in Weka?
Answer: First we need to use pre-labeled data to train the dataset and make sure data should be in ARFF format. After that, we need to load models we already train and select the unlabeled data for preprocessing.
Conclusion
In this article, we saw what Weka data mining is, as well as we also saw some basic key ideas of Weka data mining with configuration. We also saw the uses and features of Weka data mining and how we can use them.
Recommended Articles
This is a guide to Weka Data Mining. Here we discuss the introduction, why use weka data mining? installation, tool, and features. You may also have a look at the following articles to learn more –

