
Overview of Types of Clustering
Clustering is defined as the algorithm for grouping the data points into a collection of groups based on the principle that similar data points are placed together in one group known as clusters. This clustering method is categorized as Hard method( in this, each data point belongs to a max of one cluster) and soft methods (in this data point can belong to more than one clusters). Also, multiple clustering methods are present such as Partition Clustering, Hierarchical Clustering, Density-based Clustering, Distribution Model Clustering, Fuzzy clustering, etc.
Types of Clustering
Broadly methods of clustering techniques are classified into two types they are Hard methods and soft methods. In the Hard clustering method, each data point or observation belongs to only one cluster. In the soft clustering method, each data point will not completely belong to one cluster; instead, it can be a member of more than one cluster. It has a set of membership coefficients corresponding to the probability of being in a given cluster.
Currently, there are different types of clustering methods in use; here in this article, let us see some of the important ones like Hierarchical clustering, Partitioning clustering, Fuzzy clustering, Density-based clustering, and Distribution Model-based clustering. Now let us discuss each one of these with an example:
1. Partitioning Clustering
Partitioning Clustering is a clustering technique that divides the data set into a set number of groups. [For Example, the Value of K in KNN will be decided before we train the model]. It can also be called a centroid based method. In this approach, cluster centre [centroid] is formed such that the distance of data points in that cluster is minimum when calculated with other cluster centroids. The most popular example of this algorithm is the KNN algorithm. This is how a partitioning clustering algorithm looks like
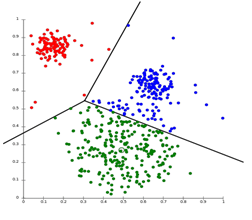
2. Hierarchical Clustering
It is a clustering technique that divides that data set into several clusters, where the user doesn’t specify the number of clusters to be generated before training the model. This type of clustering technique is also known as connectivity-based methods. In this method, simple partitioning of the data set will not be done, whereas it provides us with the hierarchy of the clusters that merge after a certain distance. After the hierarchical clustering is done on the dataset, the result will be a tree-based representation of data points [Dendogram], divided into clusters. This is how hierarchical clustering looks like after training is done.
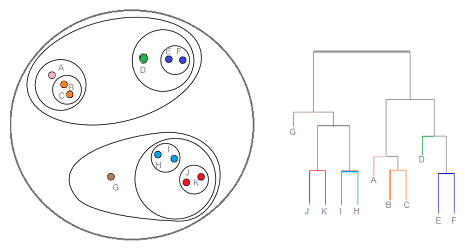
Source link: Hierarchical Clustering
In Partitioning clustering and Hierarchical clustering, one main difference we can notice is in partitioning clustering. We will pre-specify the value of how many clusters we want the data set to be divided into; we don’t pre-specify this value in hierarchical clustering.
3. Density-Based Clustering
In this clustering, technique clusters will be formed by the segregation of various density regions based on different densities in the data plot. Density-Based Spatial Clustering and Application with Noise (DBSCAN) is the most used algorithm in this type of technique. This algorithm’s main idea is there should be a minimum number of points in the neighbourhood of a given radius for each point in the cluster. So far, in the above-discussed clustering techniques, if you observe thoroughly, we can notice one common thing in all the techniques that are the shape of clusters formed are either spherical or oval or concave shaped. DBSCAN can form clusters in different shapes; this type of algorithm is most suitable when the dataset contains noise or outliers. This is how a density-based spatial clustering algorithm looks like after training is done.
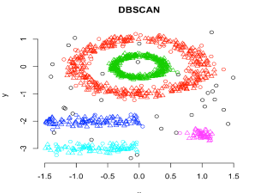
Source link: Density-Based Clustering
4. Distribution Model-Based Clustering
In this type of clustering, technique clusters are formed by identifying the probability of all the data points in the cluster from the same distribution (Normal, Gaussian). The most popular algorithm in this type of technique is Expectation-Maximization (EM) clustering using Gaussian Mixture Models (GMM).
Normal clustering techniques like Hierarchical clustering and Partitioning clustering are not based on formal models; KNN in partitioning clustering yields different results with different K-values. As KNN and KMN consider mean for the cluster centre, it is not best suitable in some cases with Gaussian Mixture Models. We presume that data points are Gaussian distributed; this way, we have two parameters to describe the clusters’ shape and the standard deviation. In this way, for each cluster, one Gaussian distribution is assigned. An optimisation algorithm called Expectation Maximization is used to get the optimum values of these parameters (mean and standard deviation). This is how EM – GMM looks like after training.
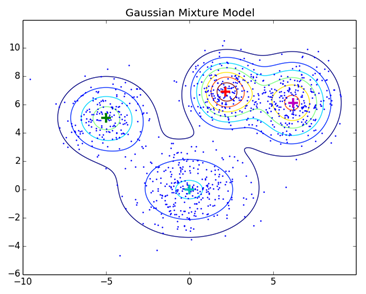
Source Link: Distribution Model-Based Clustering
5. Fuzzy Clustering
It belongs to a branch of soft method clustering techniques, whereas all the above-mentioned clustering techniques belong to hard method clustering techniques. In this clustering technique, points close to the centre may be a part of the other cluster to a higher degree than points at the same cluster’s edge. The probability of a point belonging to a given cluster is a value that lies between 0 to 1. The most popular algorithm in this type of technique is FCM (Fuzzy C-means Algorithm). Here, the centroid of a cluster is calculated as the mean of all points, weighted by their probability of belonging to the cluster.
Conclusion
These are some of the different clustering techniques currently in use, and in this article, we have covered one popular algorithm in each clustering technique. We have to choose the type of technology we use based on our dataset and the requirements we need to fulfil.
Recommended Articles
This has been a guide to Types of Clustering. Here we discuss the basic concept with different types of clustering and their examples. You may also have a look at the following articles to learn more –

