Updated February 28, 2023

Introduction to Static Hashing in DBMS
Static Hashing in a Database Management System (DBMS) can be defined as a technique for mapping the finalized or unchangeable data of illogical sizes into ordered flat sizes in the database. It is achieved by applying the respective hashing functions, where the static hash values are also called as static hash codes, static hashes, or digests. This process of static hashing is also referred to as ‘static scatter storage addressing’, as it involves gathering all the scattered static data by their address and mapping the same to be rearranged in an orderly fashion. It is a three-step process, namely, converting values into a fixed length, uniform rearrangement, and final mapping.
How Static Hashing is Carried out in DBMS?
For a Static Hashing technique to be applied on a DBMS system, it is important to maintain the objects, the attributes, and their relationship in a static manner in the database, otherwise, the mapping will become obsolete in no time.
The functional flow of static hashing includes a series of a process performed on the databases that need to be hashed and possesses all static value addresses for the records. In this process, the highest-ranked encloses a hash function, such as ‘h(x)’, in no particular order. This function should obey the limitations defined in the ‘Carter and Wegman’ hash function. After this, the previously mentioned highest ranker will hold ‘n’ buckets, and can be labeled as required by the user, like ‘A1, A2, A3, …………., and An’. With respect to this template, other buckets can have the hashing table, which will be of the size Sn.
As there are no clashes expected, and there shall be no cases such as two data has same address value in the system, the conflict limitations are usually anticipated to be n/2, which is directly proportional to the probability of conflict between two values, as well as ‘2n’ or less will be the value of the least ranking hash table in the system.
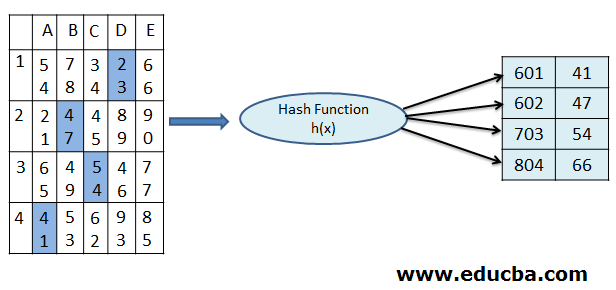
Example of Static Hashing:
In the below image, we can see the records are placed in the A4, B2, C3, and D1 cells in the Hash table. These records are then passed through the Hash function h(x), in order to apply the Static Hashing technique. After the hash function is executed on the records in the table, the records are then placed in the proper addresses in the storage memory. These new addresses for the given example are 601, 602, 703, and 804, which are situated to be the outcome of static hashing process in the DBMS.
Various Static Hashing Operations in DBMS
Below are the few commonly applied Static Hashing Operations in the Database Management System:
1. Insert Operation
The Insert operation, in the Static Hashing technique in the DBMS, is used for adding or including a new record in the hash table, which obviously should have static properties like unchangeable objects, attributes and their respective relationships. After the record is placed in the hash table, the hash function is applied on to this new record. It is, in turn, used to determine the exact address value where the new record can be placed in the hash table, as a result of the Insert operation applied to the hash table.
2. Delete Operation
This Operation is used for deleting a record from the hash table. The record that needs to be deleted is first required to be passed through the search operation, which is performed with the help of the hash function. The search result from this is later used as an input value for the delete operation. Delete is simply for removing the given value from the hash table, which then can be vacated from the assigned address from the memory.
3. Search Operation
The search operation is performed by making use of the Static Hash function, for fetching the required record by making use of the address value processed through the hash function. Like any other search process, the user or database administrator passes the desired input value through the hash function that was formulated specifically to the database in the process. The function matches the input value with that of the similar or equal values in the hash table, and locates the exact address value. The final search result is then provided to the user as the output value.
4. Update Operation
The Update Operation is a series of search, delete and insert operations performed on one go. Similar to other operations, the user passes the desired input in the update hash function, which then is applied on to the hash table. The function locates the previously allocated address, pulls down the record by the end of the search operation. Then the delete function is applied by removing the record from the address. It is then followed by the insert operation, where the new record takes the address value of the old record.
Advantages & Disadvantages of Static Hashing in DBMS
Below are the advantages and disadvantages:
Advantages
The advantages of using Static Hashing in the DBMS are as follows:
- Performance is exceptional for smaller databases.
- Aids in Storage management.
- Hash key values help in faster access to the storage addresses.
- The Primary key values can be used in the place of the hash value.
Disadvantages
The disadvantages of using the Static Hashing method in the DBMS are as follows:
- Static Hashing is not a good option for largely sized databases.
- Time taken for this function is higher than normal, as the hash function has to go through all the addresses of the storage memory in order to perform operations in the DBMS system.
- It doesn’t work well with scalable databases.
- The ordering process is not efficient compared to other hashing techniques.
Conclusion
Static Hashing is one amongst the various other hashing techniques used for mapping the unordered data placements into a sorted format, and also by providing the proper identification of the memory addresses to each value in the database. Unlike other Hashing, the Static Hashing process can be applied on the static value that doesn’t have to change values for objects, attributes, and the relationships of the data in the DBMS.
Recommended Articles
This is a guide to Static Hashing in DBMS. Here we discuss an overview of Static Hashing in DBMS and its various operations along with advantages and disadvantages. You can also go through our related articles to learn more –
