Updated June 8, 2023

Introduction to SQLAlchemy backref
The sqlalchemy backreef is one of the parameters and it’s an argument that can be followed as the relationship method will allow for users to pass the new values under the new creation property which belongs to the specified classes that mapped and already created the document the complementing relationship property is not created automatically it makes more explicit with the model codes for hidden documentation for the more information.
What is SQLAlchemy backref?
The sqlalchemy backref is one of the simple ways that can be declared using the function called backref() method and it is listed by using the formatted arguments. For each set of arguments, it will be created and called the user input values to the form and it is interpreted through the links and in between the parent and child relationships is to be mapped and default load relationship among others like one to many, many to one, one to one, many to many association objects. Mainly the backref in the document relationship has to be set on the Document version and it will be created the relationship between the versions which makes the sense and it’s presented the recommendation to use the back_populates keyword which is to be used instead of the backref.
How does SQLAlchemy backref work?
Generally, the sqlalchemy behaves like the properly configured which has the declarative base class from the extension and it is more recommended with the sqlalchemy documents for the full set of references. Whenever the base class is more important for all the database models and it is stored on the separate sqlalchemy instances which are already created and it is optional for the table name which is automatically overridden. The relationship.backref is like the keyword and it is the parameter which introducing the Object-relational and it is mentioned in many examples. We can create the database connection and configured the objects which called as the attribute to the parent object. The common shortcut way on the address mapping which includes the event establishments of the listener on the sides will be called the mirror attribute operations in the directions.
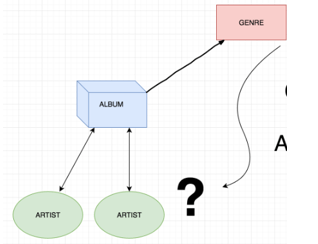
The above diagram shows the many to many relationships from the sqlalchemy the query and subquery will be called as the filter and to join the multiple set of parameters which based on the ids.
It has n number of Relationships and will be configured according to the object-relational mapping.
We can use the type called One Way Backrefs and it is more populated on the behavior which is more desirable on both single directional collections which contain the filtering to join the parent and child objects.
SQLAlchemy backref Setting
The basic key behaviors that occur in the sqlalchemy regarding cascades will be called in both directional and bidirectional default parameters. It will start at the one position of the user input objects that have been persisted throughout the session if the user session will be persistent that can be more intuitive for all the objects will append to each other for all the collections that can be added through automatically cascade the sessions the user session and the cache keys are more important than the query results. We can track the datas with the help of cache memory references that perform the cascading operation on each user session of the pending objects.
Class name(base):
---some logic codes—
Reference variable = relationship(“values”, back_populates=”value”, cascade_backrefs=boolean(true or false))The above codes are the basic syntax for mapping the user inputs in the database relationships like one to one, one to many, and many to many relationships. The user session will plays the main role of the sqlalchemy session and the id also taken as the reference of fetching the details from the database.
Since the behavior is more identified and taken as the counter-intuitive for most of the areas it can be disabled by using the setting like a relationship.cascade_backrefs as the boolean value like False.
It has follow some below steps,
- The relationship() method defines the linkage between one class to another class.
- It has followed many different steps among the one-to-many and many-to-many which are represented on the python collection objects.
- We can import the sqlalchemy packages like datatypes like Integer, Keys like Primary and Foreign keys, String, and other database columns.
- To Import other required packages that must be necessary for the project. Here mainly we can import the relationships
- By using these relationships we can call the ORM(Object Relational Mapping) that the entity should necessarily trigger on the project.
- While we executing these imports take the necessary actions for performing the tasks then we can declare the base declarative classes by using the below syntax,
- Reference = declarative_base() by using this line we can declare the base classes and pass the same references in the other classes.

- The above class is the basic syntax for to mapping the tables with the help of relationship() keyword and we can pass the arguments like back_populates and cascade_backrefs.
Example 1:
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import relationship
from sqlalchemy import create_engine
eng = create_engine(
"sqlite:///D:/Mar9.db",
)
Varss1 = declarative_base()
class first(Varss1):
__tablename__ = 'Apr12'
sno = Column(Integer)
rollno = Column(Integer)
varss = relationship("Entered inputs", backref="Apr12")
print("Your inputs are stored successfully")Sample Output:
![]()
- In the first example, we can declare the two different classes along with the required packages to be imported.
- Then we can connect the database connection either existing or creating new database connections.
- We declare the declarative_base classes for all the levels of the table creation.
- By using the relationship() method we can pass the parameters like string and method called backref string inputs.
- Here one table contains primary_key and another table has ForeignKey references for holding the user input values.
Example 2:
from sqlalchemy.orm.collections import mapped_collection
from sqlalchemy import create_engine
eng = create_engine(
"sqlite:///D:/Mar9.db",
)
class Example14(Base):
__tablename__ = 'Apr19'
id = Column(Integer)
res = relationship("All details",
news =mapped_collection(lambda res: res.text[1:12]),
cascade="all")
print("The datavalues are mapped successfully")Sample Output:
![]()
- In the second example, we can use the same relationship() method along with the other features.
- Here after class declaration we can create the table by using the tablename and declared the columns like id with Integer type along with enabled primary key.
- Then using the relationship() method we can pass the all details like mapped_collection() as additional methods for to store the values in the database index successfully.
- Lambda is the keyword for mapping the rows and columns areas with the orphan deleted nodes in the cascade buffers.
Conclusion
The sqlalchemy backref is one of the type keywords and it passed as the separate argument parameters which has to be used in the ORM mapping objects. It mainly includes the event listener on the configuration attributes with both directions of the user datas through explicitly handling the database relationships.
Recommended Articles
This is a guide to SQLAlchemy backref . Here we discuss the Introduction, What is SQLAlchemy backref, How does work SQLAlchemy backref, examples with code implementation. You may also have a look at the following articles to learn more –
