Updated March 29, 2023

Definition of spaCy ner
SpaCy ner is nothing but the named entity recognition in python. The most important, or, as we like to call it, the first stage in Information Retrieval is NER. The practice of extracting essential and usable data sources is known as information retrieval. NER locates and categorizes identified entities in unstructured text into standard categories such as human names, locations, organizations, time expressions, monetary values, percentages, codes, and so on.
What is spaCy ner?
- A component that recognizes named entities based on transitions. The entity recognizer looks for non-overlapping labeled token spans. The transition-based technique contains some conventionally named entity recognition tasks but may not be appropriate for all span identification problems. The loss function, in particular, optimizes for entire entity correctness.
- NER is a common NLP task that entails detecting named entities (people, locations, organizations, and so on) in a block of text and categorizing them into a set of predetermined categories. NER can be used in a variety of ways, for example, by identifying the persons, organizations, and locations mentioned in news articles.
- Providing concise search optimization features: instead of searching the complete material.
- As we know, each data contains a variety of words, some of which are stopwords or part of spoken words, and there can be a variety of words in a text file that can be separated into named entities.
- Objects that are named entities in any written data. Names of people, places, and things in data using their proper names are examples of objects.
- Below example shows scrapy NER as follows.
Code:
import spacy
py_nlp = spacy.load ('en_core_web_sm')
py_doc = py_nlp (py_sentence)
for ent in py_doc.ents:
print (ent.text, ent.start_char, ent.end_char, ent.label_)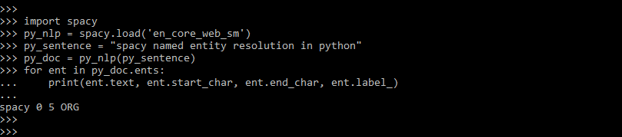
Using spaCy ner
- SpaCy is a Natural Language Processing (NLP) package that can be used for a variety of tasks.
- It provides built-in mechanisms for recognizing named entities. SpaCy has a system for quickly recognizing statistical entities.
- We may easily use spaCy for NER jobs. Despite the fact that we frequently spaCy model performs admirably for all types of text data.
- The capacity of NER models is highly dependent on the data on which they were trained. NER has a wide range of uses.
- The numerous Named Entities in a text can be collected using NER, and can be deduced using that data.
To use spaCy ner we need to install scrapy in our system. The below example shows to install scrapy in our system are as follows. We can install the scrapy module by using the pip command in the below example we have already installed scrapy so it will show the requirement is already satisfied.
pip install scrapy
- After installing scrapy in this step we are login into the python shell by using python3 command.
python3
- The below example shows how to use spaCy ner are as follows. First, we have imported the spaCy module.
Code:
import spacy
from spacy import displacy
py_ner = spacy.load ("en_core_web_sm")
py_text = py_ner (text_py)
for word in py_text.ents:
print (word.text,word.label_)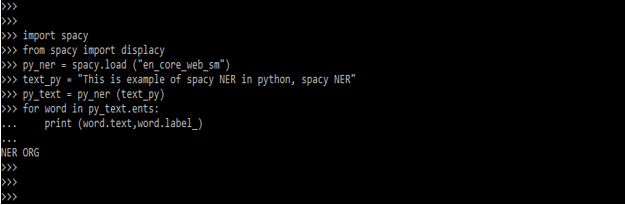
- The below example shows to display the named entities of specified text which was we have provided.
Code:
spacy.explain ("ORG")
spacy.explain ("GPE")
spacy.explain ("LOC")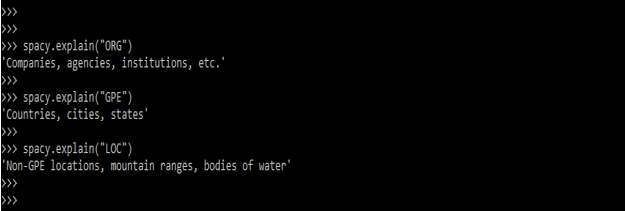
Adding spaCy ner methods
- The SpaCy library includes a feature for document-level entity annotation. This cannot, however, be written to the token.ent type attributes directly.
- There are three methods used to add spaCy ner are as follows.
Method 1
In this method, we are creating an entity name as span assigning the same to the doc.ents. The below example shows the method1 to add spaCy ner.
Code:
import spacy
from spacy.tokens import Span
py_nlp = spacy.load("en_core_web_sm")
py_doc = py_nlp("spaCy ner in python")
py_ent = [(e.text, e.start_char, e.end_char, e.label_) for e in doc.ents]
print ('Before : ', py_ent)
py_ent = Span (py_doc, 0, 1, label="ORG")
py_ent = [(e.text, e.start, e.end, e.label_) for e in doc.ents]
print('After : ', py_ent)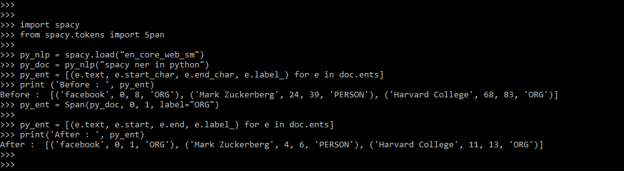
Method 2
In this method, we are creating a span entities new list. The below example shows method2 spaCy ner methods.
Code:
import spacy
from spacy.tokens import Span
py_nlp = spacy.load("en_core_web_sm")
py_doc = py_nlp("spacy ner in python")
py_ent = [(e.text, e.start_char, e.end_char, e.label_) for e in doc.ents]
print ('Before : ', py_ent)
py_ent = Span(py_doc, 0, 1, label="ORG")
orig_ents = list(doc.ents)
py_ent = [(e.text, e.start, e.end, e.label_) for e in doc.ents]
print('After : ', py_ent)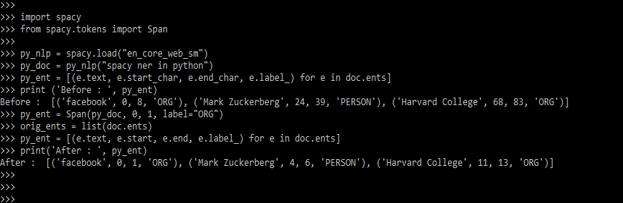
Method 3
In this method we are creating the numpy arrays as follows.
Code:
import numpy
import spacy
from spacy.attrs import ENT_IOB, ENT_TYPE
py_nlp = spacy.load ("en_core_web_sm")
doc = py_nlp.make_doc ("Python spacy ner, N.A.")
print('Before :', ents) # []
py_head = [ENT_IOB, ENT_TYPE]
py_arr = numpy.zeros ((len(doc), len(py_head)), dtype="uint64")
py_arr[0, 0] = 3
py_arr[0, 1] = doc.vocab.strings ["GPE"]
py_arr[7:, 0] = 3
py_arr[7:, 1] = doc.vocab.strings["GPE"]
doc.from_array (py_head, py_arr)
print('After :', ents)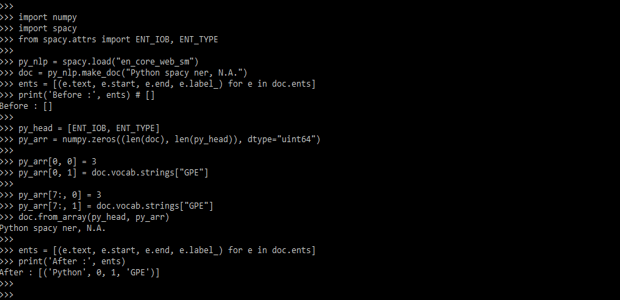
SpaCy ner models
- The doc ents return a sequence of Span objects, which is the most common mechanism to obtain entity annotations. The entity type can be accessed via ent.label or as a string.
- We can iterate Span object, which functions as a sequence of tokens. We can also receive the entity’s text form, as a token.
- The token.ent_iob and token.ent type attributes can also be used to get at token entity annotations. The attribute token.ent_iob specifies whether an entity begins, continues, or terminates on the tag.
- With single optimized functions provided, spaCy is considered the fastest NLP framework in Python.
- The process of identifying a named entity and linking it to its class is known as named entity recognition.
- SpaCy allows users to update the model to include new examples with existing entities. SpaCy provides a pipeline component called ‘ner’ that finds token spans that match entities.
- Below is the example of spaCy ner models as follows.
Code:
import spacy
from spacy.lang.en.examples import sentences
py_nlp = spacy.load ("en_core_web_sm")
py_doc = py_nlp (sentences[0])
print (py_doc.text)
for token in py_doc:
print (token.text, token.pos_, token.dep_)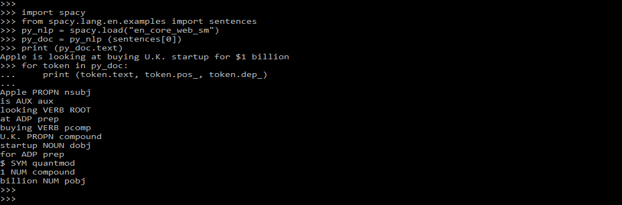
Conclusion
SpaCy allows users to update the model to include new examples with existing entities. SpaCy provides a pipeline component called ‘ner’ that finds token spans that match entities. With single optimized functions provided, spaCy is considered the fastest NLP framework in Python.
Recommended Articles
This is a guide to SpaCy ner. Here we discuss the definition, What is spaCy ner, SpaCy ner models, methods, and examples with code implementation. You may also have a look at the following articles to learn more –

