Updated March 29, 2023

Definition of spaCy models
SpaCy models training pipelines are available as Python packages. This implies they, like any other module, are a part of our program. They’re versioned and can be specified in our requirements.txt as a dependency. Trained pipelines can be installed manually or using pip. The pipelines are built to be efficient in terms of speed and size, and they function effectively when they are fully loaded.
Introduction to spaCy models
- The spaCy is very efficient and customizable. Multiple components, for example, can share a similar “token-to-vector” paradigm, and the lemmatizer can be easily swapped out or disabled.
- For creating the spaCy models first, we need to create a code environment and add “spaCy” to our package needs, just like any other Python package.
- Some spaCy features are not included in the library. An extra download step is required to use these models. On shared DSS nodes, this can cause problems because users don’t have write access to shared server locations.
- Unlike in spaCy v2, when the tagger parser was self-contained, several v3 components rely on earlier pipeline components.
- As a result, deactivating has an impact on the quality of the annotations or results in warnings and errors.
- The tok2vec component is monitored by the tagger, morphologizer, and parser components.
- If morphologizer, the attribute ruler binds token.tag to token.pos. If there is no tagger, the attribute ruler also ensures that whitespace is uniformly tagged and transfers token.pos to token.tag.
- SpaCy’s dedicated pip delivery system can help us to solve this problem. To use spaCy models first, we need to install spaCy in our system. SpaCy models are very useful and important in python.
- The below steps show how to install and check spaCy modules are as follows.
- In this step, we are installing the spaCy package by using the pip command. In the below example, we have already installed the spaCy package in our system so it will show that requirement is already satisfied, then we have no need to do anything.
pip install spacy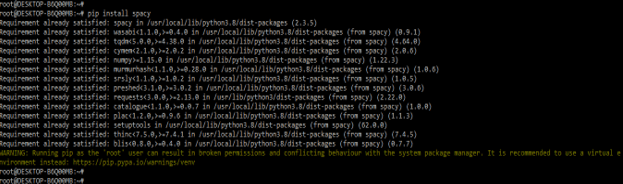
- After installing all the modules, we are opening the python shell by using the python3 command.
python3
- After login into the python shell in this step, we are checking bs4, and the requests package is installed in our system.
import spaCy
print (spaCy)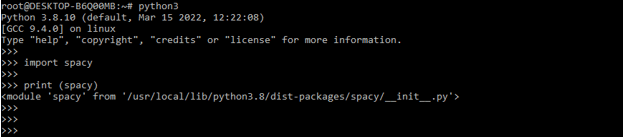
SpaCy models and languages
- We already know that spaCy’s models are installed by using a package of python, which means they are part of our program just like any other module. The requirement.txt file can be used to version and define certain modules.
- Alternatively, we may use pip to install a model directly. We can do this by running the pip command on the archive file’s URL or local directory. If we don’t have a model’s direct URL, go to its release page and copy it from there.
- The below example shows how to install spaCy models in Linux-like systems as follows. In the below example, we have installed the spaCy models by using external URLs as follows.
pip install https://github.com/explosion/spaCy-models/releases/download/en_core_web_sm-2.2.0/en_core_web_sm-2.2.0.tar.gz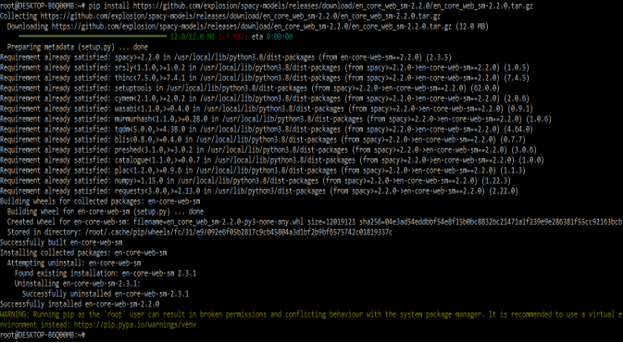
- In the below example, we have to install the model by using a local file as follows.
pip install en_core_web_sm-2.2.0.tar.gz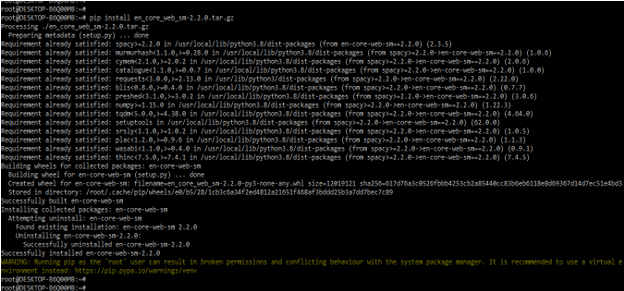
- We can also manually download the data and save it to our own directory. Manually download the data using one of these methods. From the most recent release, we can download the model directly from our browser. The archive files can be used to create our own download script.
- We can save the package model wherever we choose on our local file system once we’ve finished downloading it.
- The below example shows importing as module are as follows.
Code –
import spaCy
import en_core_web_sm
py_exmp = en_core_web_sm.load ()
py_doc = py_exmp ("spaCy models")
print (py_doc)

- We can also make use of our previously trained model. To do so, use the language. We may also encapsulate it as a Python package to make deployment easier.
- The following is reflected in the model versioning.
- SpaCy compatibility
- The major and minor versions of the model.
- A model will translate as follows,
- r – SpaCy major version.
- S – Model major version. It prevents users from loading several major versions with the same code.
- T – Minor version of the model. The model structure is the same, but the parameter values are different. For instance, different data for varying numbers of iterations could be used to train the model.
- Below is the spaCy models used in python as follows.
- en_core_web_sm – The language of this model is English. Type is syntax, entities, and vocabulary. The size of the model is 13 MB. The license is from MIT.
- en_core_web_md – The language of this model is English. Type is vectors, syntax, entities, and vocabulary. The size of the model is 43 MB. The license is from MIT.
- en_core_web_lg – The language of this model is English. Type is syntax, vectors, entities, and vocabulary. The size of the model is 741 MB. The license is from MIT.
- en_core_web_trf – The language of this model is English. Type is syntax, entities, and vocabulary. The size of the model is 438 MB. The license is from MIT.
- SpaCy will support the following languages as follows. The below table shows language and its code.
| Language | Code | Language | Code |
| Chinese | zh | Danish | da |
| English | en | Dutch | nl |
| French | fr | German | de |
| Greek | el | Italian | It |
| Japanese | ja | Lithuanian | It |
| Multi-language | xx | Norwegian Bokmål | nb |
| Polish | pl | Portuguese | Pt |
| Romanian | ro | Spanish | es |
| Afrikaans | af | Albanian | sq |
| Arabic | ar | Armenian | hy |
| Basque | eu | Bengali | bn |
| Bulgarian | bg | Catalan | ca |
| Croatian | hr | Czech | cs |
| Estonian | et | Finnish | fi |
| Gujarati | gu | Hebrew | he |
| Hindi | hi | Hungarian | hu |
| Icelandic | is | Indonesian | Id |
| Irish | ga | Kannada | kn |
| Korean | ko | Latvian | lv |
| Ligurian | lij | Luxembourgish | lb |
| Macedonian | mk | Malayalam | ml |
| Marathi | mr | Nepali | ne |
| Persian | fa | Russian | ru |
| Serbian | sr | Sinhala | si |
| Slovak | sk | Slovenian | sl |
| Swedish | sv | Tagalog | tl |
| Tamil | ta | Tatar | tt |
| Telugu | te | Thai | th |
| Turkish | tr | Ukrainian | uk |
| Urdu | ur | Vietnamese | vi |
| Yoruba | yo |
Conclusion
The spaCy models are very efficient and customizable. Multiple components, for example, can share a similar “token-to-vector” paradigm, and the lemmatizer can be easily swapped out or disabled. SpaCy models training pipelines are available as Python packages. This implies they, like any other module, are part of our program.
Recommended Articles
This is a guide to spaCy models. Here we discuss the Definition, Introduction, SpaCy models and languages, and examples with code implementation. You may also have a look at the following articles to learn more –

