Updated April 4, 2023

Introduction to Scrapy Redis
Scrapy redis is a web crawling and structured data extraction application framework that may be used for various purposes such as data mining, information processing, and historical archiving. It is a data structure of in-memory that is used as a database, cache, or message broker. It is open-source; hyperlogs and geographic indexes with redis queries are supported. Therefore, it is very important in web crawling.
What is Scrapy Redis?
- Scrapy redis is a key-value data store that is NoSQL. It’s a data structure server, to be precise. Because Redis has the persistence to disc, it can be used as a genuine database rather than merely a volatile cache.
- The data will not vanish when we restart, as it does with Memcached. Like Memcached, the complete data set is saved in memory, making it extremely fast, often even quicker than Memcached.
- Virtual memory was utilized in Redis, where infrequently used values were switched out to disc, leaving only the keys in memory, but this was deprecated.
How to Use Scrapy Redis?
Redis will be used in the future when it is possible (and desired) to fit the complete data set into memory. If we need data that can be shared by several processes, apps, or servers, Redis is an excellent solution. We will need our servers (with Redis-compatible OS systems). We can also use paid server provider APIs like Linode, Digital Ocean, and others to get this helpful distributed architecture. We would build the number of servers using these APIs based on the need to scrape and the amount of time we have to scrape that data. A redis-server with the bind-address set to 0.0.0.0 is also required.
It runs on the scrapy framework and is based on the redis database, allowing scrapy to support distributed tactics. The Slaver and Master sides share the Redis database’s item queue, request queue, and request fingerprint collection. Scrapy is a multi-threaded, twisted processing framework that comes with a downloader, parser, log, and exception handling. It has benefits for crawling the development of a single fixed website, but it is cumbersome to change and grow for multi-site crawling of 100 websites since processing.
The below steps show how to use scrapy redis as follows. First, we need to install the scrapy-redis package in our system to use it.
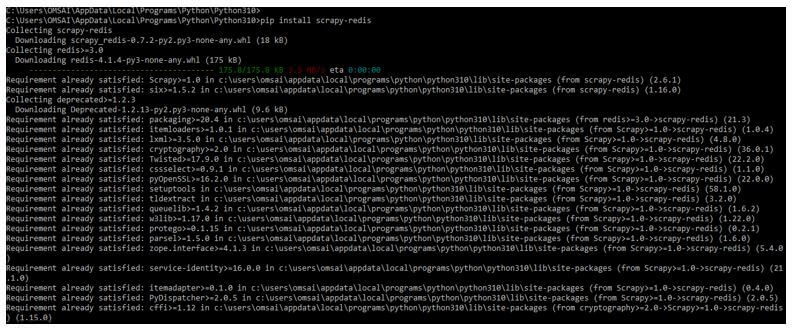
1. In the first step, we install a package of scrapy-redis by using the pip command.
The below example shows the installation of scrapy redis as follows. In the below example, we have already installed a scrapy-redis package in our system, so it will show that the requirement is already satisfied; we do not need to do anything.
Code:
pip install scrapy-redisOutput:
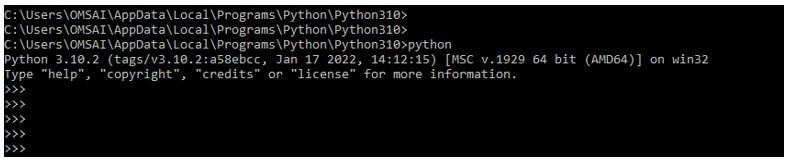
2. After installing the scrapy in this step, we log into the python shell using the python command.
Code:
pythonOutput:
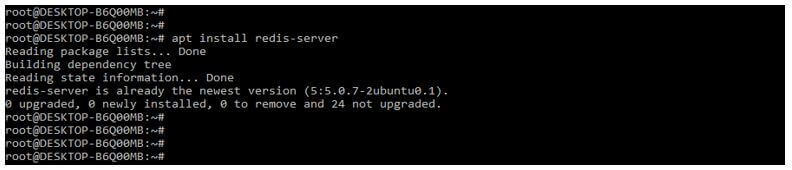
3. After installing the scrapy-redis package, we need to install the redis database server in our system. In the below example, we are installing the redis DB server in our system.
Code:
apt install redis-serverOutput:
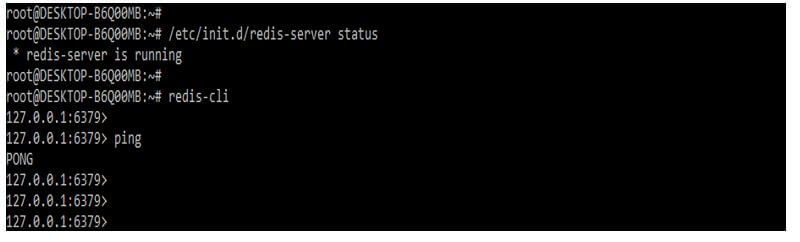
4. After installing the redis server in this step, we check the status of the redis server as follows.
Code:
/etc/init.d/redis-server statusredis-cliOutput:
Scrapy Redis Analysis
- Scrapy is a robust python crawler package, but a single host’s processing capacity is insufficient when we have many pages to crawl.
- The benefits of crawlers are being exposed now, and the number of people interested in growing rapidly. Scrapy-redis combines scrapy with the distributed database redis, rewrites some of scrapy’s most crucial functionality, and simultaneously transforms numerous computers.
- We still need to look at the source code of scrapy to fully understand the operating principle of distributed crawlers must first understand the operating principle of scrapy.
- Only a few can be read quickly and are relatively simple to comprehend. Redis and scrapy make up the bulk of the scrapy-redis project.
- It is based on scrapy components redis, allowing for the rapid realization of a distributed crawler. Essentially, this component performs three tasks. Scheduler, Dupefilter, and Pipeline.
- Listed four items are available as follows. The components are nothing but the module, which we need to modify accordingly. Scheduler, Duplication Filter, Item pipeline, and Base spider.
URL Weight Removal
Reducing the color palette is an often-overlooked significant impact on image file size. Simple color schemes that incorporate those used in the corporate logo are frequently employed in landing page images. Another reason to include the library when a visitor first visits the page is that the browser caches them indefinitely once they are loaded.
The below example shows URL weight removal as follows. First, we are updating the spider middleware.
Code:
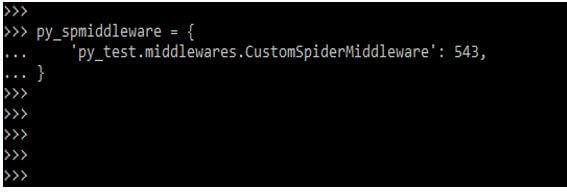
py_spmiddleware = {
'py_test.middlewares.CustomSpiderMiddleware': 543,
}Output:
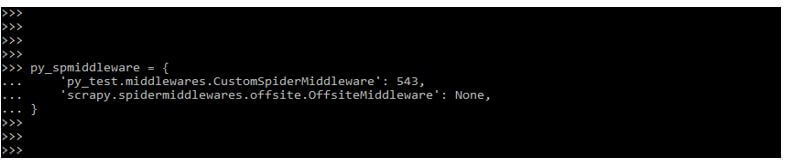
In the below example, we are adding scrapy with spider middleware for weight removal.
Code:
py_spmiddleware = {
'py_test.middlewares.CustomSpiderMiddleware': 543,
'scrapy.spidermiddlewares.offsite.OffsiteMiddleware': None,
}Output:
On the server side, HTTP headers can perform the initial request and, as a result, call up a webpage. This method can cut the amount of HTML, resulting in a substantially lighter webpage. In addition, using inline styles across the page instead of loading the complete style.css file is a good way to decrease weight on a landing page. This not only reduces the overall size of the homepage.
Scrapy Redis Project
In the below example, we are using the GitLab project.
We can also install the setup by using git. The below example shows to install the setup by using git as follows.
Code:
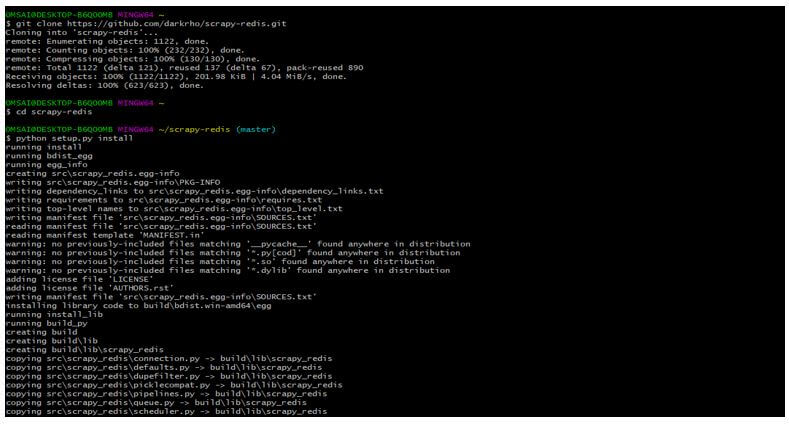
$ git clone https://github.com/darkrho/scrapy-redis.git
$ cd scrapy-redis
$ python setup.py installOutput:
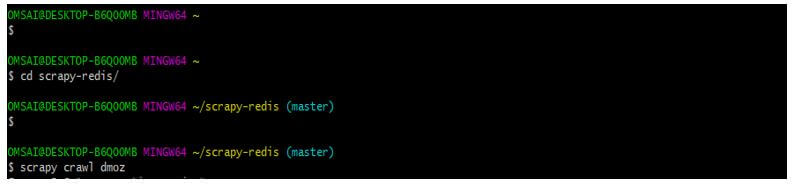
After all, setup is successful in this step; we run the project using a crawl.
Code:
$ scrapy crawl dmozOutput:
Conclusion
It is a key-value data store that is NoSQL. It’s a data structure server, to be precise. It is a web crawling and structured data extraction application framework that may be used for various purposes, such as data mining, information processing, and historical archiving.
Recommended Articles
We hope that this EDUCBA information on “Scrapy Redis” was beneficial to you. You can view EDUCBA’s recommended articles for more information.
