Updated March 16, 2023

Introduction to Scikit Learn Naive Bayes
Scikit learn naive bayes is a method set used in a learning algorithm based on the bayes theorem for the assumption of independence between pair of values and the class variable. Bayes’s theorem states the relationship between class variables. Using it is performing online updates for model parameters while using partial fit. We are using the algorithm for updating the features.
Key Takeaways
- The classifier in naive bayes will bring power to the theorem of machine learning. We can apply the classifier of naive bayes into the dataset of scikit learn.
- It provides different kinds of classifiers in naive bayes; all the classifiers differ in assumption.
What is Scikit Learn Naive Bayes?
It is the fast and most straightforward classification algorithm suitable for chunks of data. We can use the naive bayes algorithm in multiple applications. It is a classification technique that was based on the theorem of bayes. The classifier of naive bayes is accurate, fast, and reliable. The classifier of naive bayes in scikit learn contains speed on large sets and data accuracy. It will assume that a particular feature effect in the class is independent and does not depend on other features.
We can say that it is a method that was setting the supervised algorithms; it is based on the bayes theorem by using solid assumptions that the predictors we are using are separate from everyone. The presence feature is separate from the other one from the same class. This method defines the naive bayes assumption, which is called the scikit learn naive bayes method.
Scikit Learn Naive Bayes Classifier Calculation
We need to calculate the probability of different conditions. Suppose we are defining the probability of a sports player, then we need to classify whether that player is playing or not as per the specified condition. There are multiple approaches we are using to define this condition.
The naive bayes classifier calculates the probability by using the following events:
- In the first step, we will calculate the prior probability for the given labels.
- In the second step, we find the probability of likelihood of each class and attribute.
- In the third step, we are putting values in the bayes formula and calculate the probability.
- In the fourth step, we see which class contains the probability which was higher; also, it will give the class of higher probability.
The below example shows how we can calculate the probability of playing as follows. We are using the variable as A.
A(Yes | play) = A (play | Yes) A (Yes) / A (play)
The below example shows how we can calculate the probability of playing as follows. We are using variable as A.
A (No | cast) = A (cast | No) A (No) / A (cast)
In the below example we are importing the numpy modules.
Code:
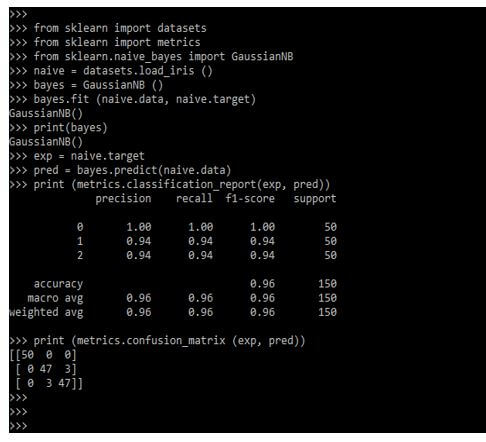
from sklearn import datasets
from sklearn import metrics
from sklearn.naive_bayes import GaussianNB
naive = datasets.load_iris()
bayes = GaussianNB()
bayes.fit (naive.data, naive.target)
print(bayes)
exp = naive.target
pred = bayes.predict (naive.data)
print (metrics.classification_report (exp, pred))
print (metrics.confusion_matrix (exp, pred))Output:
The below example shows how we can calculate the probability of playing as follows. We are using variable as A.
A (temp = ok, play | Yes) = A (play | No) A (No) A (play | yes)
Scikit Learn Naive Bayes Algorithms
It is a basic algorithm, but this is a very effective classification model probabilistic in machine learning which was drawing the influence from the Bayes theorem of bayes. Bayes theorem contains the formula offering the conditional probability of an event happening in a specified event.
Formula for algorithm is as follows:
P (M/N) = P (N/M).P (M) / P (N)
In the above formula, M and N are events defined in the formula. The P (M/N) is an event probability of M, provided in the event in N. The P (N/M) is an event probability of N, which was provided in the event which happened in M. P (M) is the independent probability of M. P (N) is the independent probability of N. The bayes theorem is used to generate the classification model as follows.
P (Q/R) = P (R/Q).P (Q) / P (R)
Below are the types of the naive bayes algorithm classifier as follows.
It is divided into three categories:
- Gaussian naive bayes
- Bernoulli naive bayes
- Multinomial naive bayes.
In the below example, we are using Gaussian naive bayes.
Code:
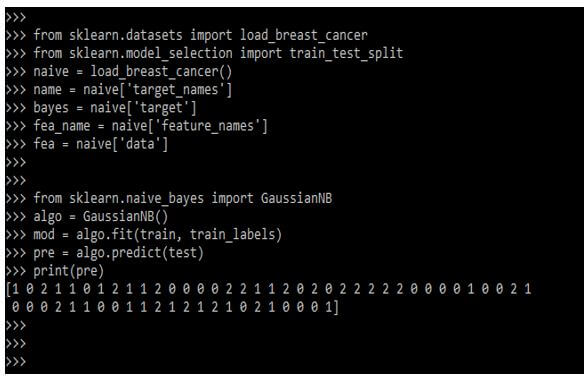
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
naive = load_breast_cancer()
name = naive['target_names']
bayes = naive['target']
fea_name = naïve ['feature_names']
fea = naive['data']
from sklearn.naive_bayes import GaussianNB
algo = GaussianNB()
mod = algo.fit (train, train_labels)
pre = algo.predict (test)
print (pre)Output:
Examples of Scikit Learn Naive Bayes
Given below are the examples mentioned:
Example #1
In the below example, we are defining the Gaussian naive bayes. We are importing the predicted values.
Code:
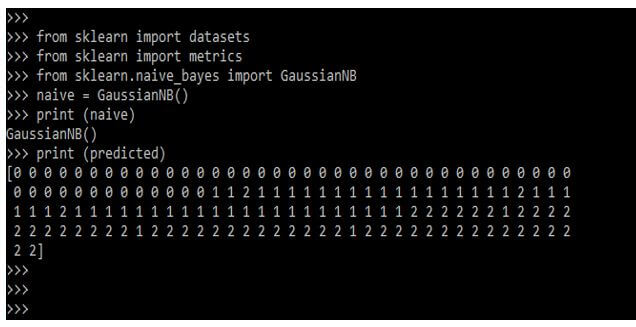
from sklearn import datasets
from sklearn import metrics
from sklearn.naive_bayes import GaussianNB
naive = GaussianNB()
print (naive)
print (predicted)Output:
Example #2
In the below example, we are importing the datasets.
Code:
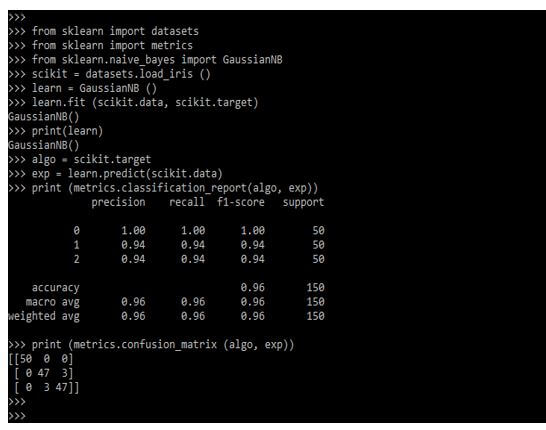
from sklearn import datasets
from sklearn import metrics
from sklearn.naive_bayes import GaussianNB
scikit = datasets.load_iris ()
learn = GaussianNB ()
learn.fit (scikit.data, scikit.target)
print (learn)
algo = scikit.target
exp = learn.predict(scikit.data)
print (metrics.classification_report(algo, exp))
print (metrics.confusion_matrix (algo, exp))Output:
FAQ
Given below are the FAQs mentioned:
Q1. Why do we use scikit learn naive bayes algorithms in python?
Answer: Naive bayes is very simple and fast it also provides good results. It’s very easy to implement in production, it is suited to the training set.
Q2. What is scikit learn naive bayes classifier?
Answer: The classifier is used in bayes theorem. The classifier is a simple algorithm used in scikit learn, this will contain high accuracy.
Q3. How can we build the classifier in scikit learn naive bayes?
Answer: We can use a dummy dataset to build the classifier we can also use the default dataset from scikit learn.
Conclusion
It is a fast and most straightforward classification algorithm which was suitable for chunks of data. Bayes theorem is stating the relationship between class variables. It also performs online updates for model parameters while using partial fit.
Recommended Articles
This is a guide to Scikit Learn Naive Bayes. Here we discuss the introduction, classifier work, algorithms, examples, and FAQ. You may also have a look at the following articles to learn more –
