Updated March 16, 2023
Introduction to Scikit Learn Decision Tree
This is an outline of Scikit learn decision tree. Basically, decision tree comes under the supervised learning method or we can say that the non-parametric method is used for the regression and classification of the data. The main purpose of the decision tree is to create the model for the prediction of target datasets by applying simple decision rules. Normally there are two main entities inside the decision tree such as root and child or we can say that leaves where we got the end result which we want.
Overview of Scikit Learn Decision Tree
A decision tree is one of the most often and generally utilized directed AI calculations that can perform both relapse and grouping undertakings. The instinct behind the choice tree calculation is straightforward, yet likewise extremely strong.
For each quality in the dataset, the choice tree calculation frames a hub, where the main trait is set at the root hub. For assessment, we start at the root hub and work our direction down the tree by following the comparing hub that meets our condition or “choice”. This cycle goes on until a leaf hub is reached, which contains the forecast or the result of the choice tree.
This might sound like a piece muddled from the beginning, yet what you presumably don’t understand is that you have been utilizing choice trees to settle on choices your whole existence without knowing it. Consider a situation where an individual requests that you loan them your vehicle for a day, and you need to settle on a choice about whether to loan them the vehicle. There are a few factors that assist with deciding your choice, some of which have been recorded underneath:
- Is this individual a dear companion or simply a colleague? If the individual is only an associate, decline the solicitation; on the off chance that the individual is a companion, move to the subsequent stage.
- Is the individual requesting the vehicle interesting? Assuming this is the case, loan them the vehicle, any other way to move to the next
- Was the vehicle harmed the last time they returned the vehicle? If indeed, decline the solicitation; if no, loan them the vehicle.
Key Takeaways
- By using a decision tree we can make the prediction for classification and regression.
- It required very less time to train the algorithm
- The decision tree is very fast and efficient to implement as compared to the other classification algorithms.
- It also helps us to classify the non-linearly data as per our requirement.
Scikit Learn Decision Tree with Classification
A decision tree is capable of executing the multi-class classification so we need to use the DecisionTreeClassifier. Basically, this classifier receives the input from two different arrays, for example, A and B, here array A is nothing but the sparse shape used to hold the training samples and B is nothing integer value used for the class labels.
First, we need to import all the required libraries as below.
Code:
from sklearn.datasets import load_iris
from sklearn import treeAfter that we need to import or load the dataset as per our requirement, here we load the Iris dataset. Next, we need to make the analysis of the data with the help of the dataset.shape
Example:
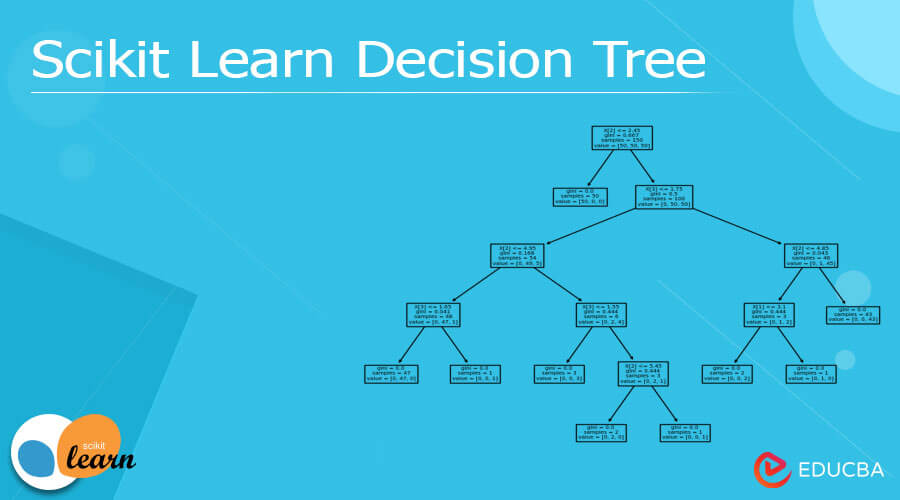
Let’s consider an example of the iris dataset, here we try to construct the tree from the Iris dataset as below.
Code:
from sklearn.datasets import load_iris
from sklearn import tree
iriss = load_iris()
X, y = iriss.data, iriss.target
cl = tree.DecisionTreeClassifier()
clf = cl.fit(X, y)
print(clf)
result = tree.plot_tree(clf)
print(result)Explanation:
From the above example first, we need to import the iris dataset as well as the sklearn tree package as shown, after that we use the DecisionTreeClassifier method with plot.tree function as shown in the above code. After execution, we get the following result as shown in the below screenshot.
Scikit Learn Decision Tree Regression
Basically, decision regression highlights an item and trains a model in the construction of a tree to foresee information in the future to deliver significant nonstop results. The persistent result implies that the result isn’t discrete, i.e., it isn’t addressed just by a discrete, known set of numbers or values. For implementation, we need to follow several steps as follows.
- First, we need to import the all required libraries
- In the second step, we need to initialize the dataset and print it.
- In the third step, we need to select all the rows and columns for 1 dataset.
- In the next step, we need to select all the rows and columns for 2 datasets.
- Now fit the decision regression for the datasets.
- In the next step, we need to make the prediction of values and see the result.
Example
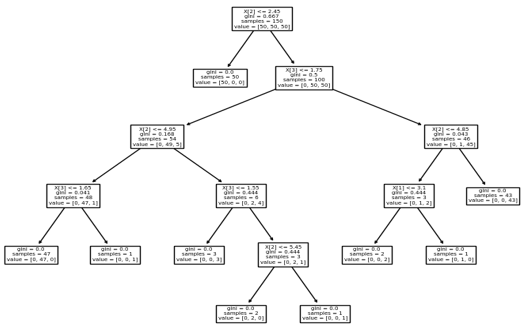
Code:
from sklearn.datasets import load_iris
from sklearn import tree
iriss = load_iris()
X, y = iriss.data, iriss.target
cl = tree.DecisionTreeRegressor()
clf = cl.fit(X, y)
print(clf)
result = tree.plot_tree(clf)
print(result)Explanation
End result is shown in the below screenshot.
Parameters
- criterion: It is used to determine the quality of split dataset
- splitter: It is used to define which strategy is best to split each node from the tree.
- max_depth: By using this parameter we can define the maximum length of the tree.
- min_samples_split: by using this parameter we can define the number of minimum samples.
- min_samples_leaf: by using this parameter we can define the number of minimum samples for the leaf node.
- max_features: When we want the best split then we can use this parameter to define the number of features.
- random_state: This parameter is used to show the random numbers which are used for shuffling data and it provides different options to the user.
It also provides different parameters such as max_leaf_nodes, min_impurity_decrease, min_impurity_split, and class_weight.
FAQ
1. Which algorithm is used to create a decision tree?
Ans: Actually it comes under the supervised learning algorithm, so basically it uses the CART algorithm on the other hand for splitting it uses the Gini and entropy.
2. What is a decision tree?
Ans: Basically tree is a machine learning algorithm based on different conditions. Normally the decision tree consists of the leaf node and root node, the leaf node we can create from the root node, and all nodes we created with help of different parameters such as Gini index, entropy, etc.
3. What are the different type’s decision tree algorithms?
Ans: Basically there are different types of decision tree algorithms such as ID3, C4.5, C5.0, and CART.
Conclusion
In this article, we are trying to explore the Scikit Learn decision tree. We have seen the basic ideas of the Scikit Learn linear decision tree as well as what are the uses, and features of these Scikit Learn linear decision trees. Another point from the article is how we can see the basic implementation of the Scikit Learn decision tree.
Recommended Articles
This is a guide to Scikit Learn Decision Tree. Here we discuss the Definition, overviews, method, parameters, examples, Key Takeaways, and FAQs. You may also have a look at the following articles to learn more –
