Updated March 16, 2023

Introduction to Scikit Learn Cross-Validation
Scikit learn cross-validation is the technique that was used to validate the performance of our model. This technique is evaluating the models into a number of chunks for the data set for the set of validation. By using scikit learn cross-validation we are dividing our data sets into k-folds. In this k will represent the number of folds from which we want to split our cross-validation data.
Key Takeaways
- The k-fold cross validation is a popular technique in scikit learn. Class is configured by using a number of folds then we are calling split function by passing the dataset.
- The split function result will be enumerated by the given row indexes for the test and train set of each fold.
Overview of Scikit Learn Cross Validation
The model which was repeating the labels for the samples is a perfect score but it will fail to predict anything on to the unseen data, this situation in scikit learn is called overfitting. To avoid this situation the best common practice at the time of performing machine learning we need to hold the part of data into the test set.
At the time of evaluating the different types of setting for the estimators such as a C then we need to manually set the SVM. At the time of partitioning the data which was available in three sets. We can reduce the number of samples which was used for learning the model and the same result depends on the random choice for the set of pairs.
The measure of performance is reported by using k-fold cross validation after it will average the values which were computed into the loop, this approach is computationally expensive but it is not wasting the data, it is a major advantage for the problems such as an inference where samples are small.
Scikit Learn Cross Validation Performance
Setting the data set for testing and training is an essential and basic task when we are getting the model of machine learning. For determining whether our model is overfitting or not then we need to test the data which was unseen. If suppose the given model is not performing well then the validation set is not performing well at the time of dealing with the real data. This notion will make cross-validation the most important concept which will ensure the model stability.
We are using the automatic configuration method instead of using a specific configuration. There is a final model which is the best configuration model found by using the procedure.
Below example shows scikit learn cross-validation performance as follows:
Code:
from sklearn import metrics
from sklearn import svm
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn import datasets
X, y = datasets.load_iris (return_X_y = True)
X.shape, y.shapeOutput:
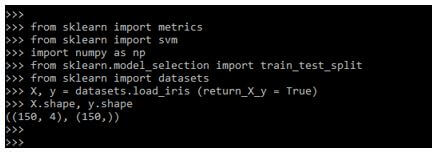
In the below example, we are defining the array condition of a specified number as follows. We are validating the performance as follows.
Code:
from sklearn import metrics
from sklearn import svm
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn import datasets
from sklearn.model_selection import cross_val_score
learn = svm.SVC (kernel='linear', C = 3, random_state = 48)
scikit = cross_val_score(learn, X, y, cv = 7)
scikitOutput:
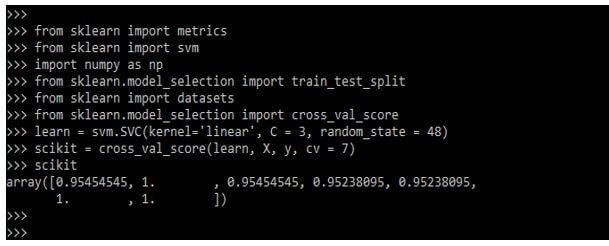
Scikit Learn Cross Validation Metrics
The very simple way to use cross-validation is to call the cross_val_score helper function onto the dataset and estimator. In the following example, we can see how we are estimating the accuracy of kernel support which was linear in a vector machine onto the dataset which is iris by using consecutive time as 10.
Code:
from sklearn import metrics
from sklearn import svm
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn import datasets
from sklearn.model_selection import cross_val_score
cross = svm.SVC(kernel='linear', C = 2, random_state = 52)
metrics = cross_val_score(cross, X, y, cv = 10)
metricsOutput:
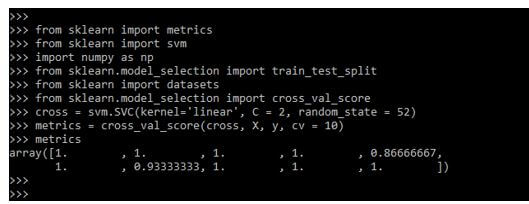
In the below example, we are printing the scikit learn cross-validation metrics accuracy as follows.
Code:
from sklearn import metrics
from sklearn import svm
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn import datasets
from sklearn.model_selection import cross_val_score
cross = svm.SVC(kernel='linear', C = 2, random_state = 52)
metrics = cross_val_score(cross, X, y, cv = 10)
metrics
print ("%0.2f accuracy %0.2f" % (metrics.mean(), metrics.std()))Output:
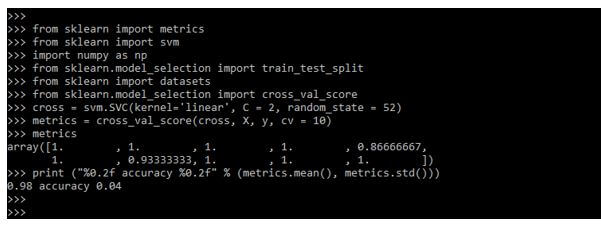
In the below example, we are defining the scikit learn cross-validation metrics of the random state as follows.
Code:
from sklearn import metrics
from sklearn import svm
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn import datasets
from sklearn.model_selection import ShuffleSplit
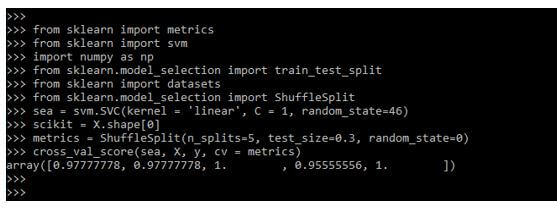
sea = svm.SVC(kernel = 'linear', C = 1, random_state=46)
scikit = X.shape[0]
metrics = ShuffleSplit (n_splits=5, test_size=0.3, random_state=0)
cross_val_score(sea, X, y, cv = metrics)Output:
Scikit Learn Cross Validation Iterators
We assume that some data is independent and is identically distributed for making the assumption to sample them from a generative process to assume the memory of past generated samples.
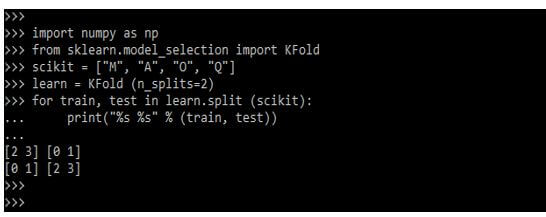
Below example shows 2 fold cross-validation of the dataset by using 4 samples as follows:
Code:
import numpy as np
from sklearn.model_selection import KFold
scikit = ["M", "A", "O", "Q"]
learn = KFold (n_splits=2)
for train, test in learn.split (scikit):
print("%s %s" % (train, test))Output:
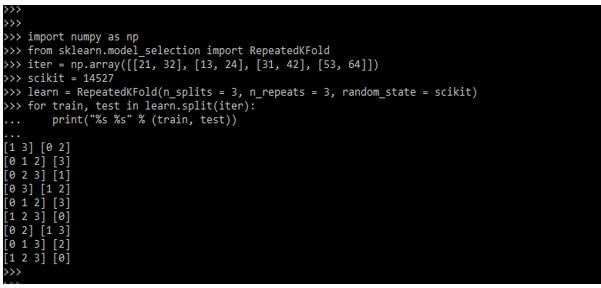
In the below example, we are using the repeated k-fold. The repeated k-fold will repeat the k-fold n times. It is used when we require to run the k-fold n number of times.
Code:
import numpy as np
from sklearn.model_selection import RepeatedKFold
iter = np.array([[21, 32], [13, 24], [31, 42], [53, 64]])
scikit = 14527
learn = RepeatedKFold(n_splits = 3, n_repeats = 3, random_state = scikit)
for train, test in learn.split(iter):
print ("%s %s" % (train, test))Output:
Examples of Scikit Learn Cross-Validation
Given below are the examples mentioned:
Example #1
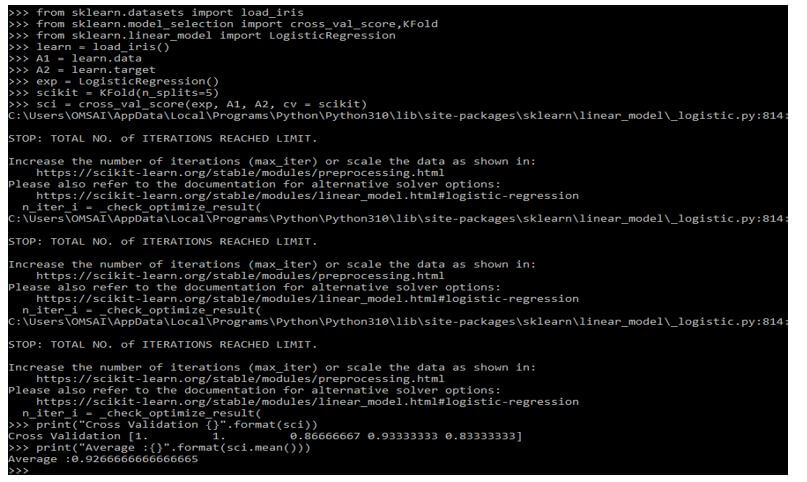
Below is the example of scikit learn cross-validation as follows. In the below example, we are defining k-fold cross validation as follows.
Code:
from sklearn.datasets import load_iris
from sklearn.model_selection import cross_val_score, KFold
from sklearn.linear_model import LogisticRegression
learn = load_iris()
A1 = learn.data
A2 = learn.target
exp = LogisticRegression()
scikit = KFold(n_splits=5)
sci = cross_val_score(exp, A1, A2, cv = scikit)
print("Cross Validation {}".format(sci))
print("Average :{}".format(sci.mean()))Output:
Example #2
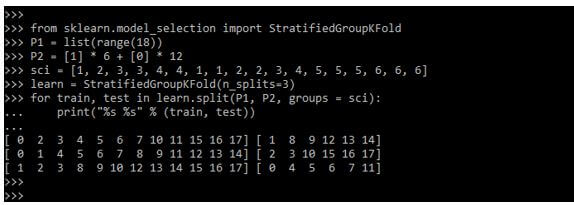
In the below example, we are defining the cross-validation scheme which combines the stratified k-fold and group k-fold as follows.
Code:
from sklearn.model_selection import StratifiedGroupKFold
P1 = list(range(18))
P2 = [1] * .. * 12
sci = []
learn = StratifiedGroupKFold(n_splits=3)
for train, test in learn.split(P1, P2, groups = sci):
print("%s %s" % (train, test))Output:
FAQ
Given below are the FAQs mentioned:
Q1. What is the use of scikit learn cross-validation in python?
Answer:
The scikit learn cross-validation is used to validate the performance of a model, it will evaluate the chunk’s performance.
Q2. Which libraries do we need to use while working with scikit learn cross-validation?
Answer:
We need to use the matplotlib, numpy, and pandas library at the time of using scikit learn cross-validation.
Q3. What is the use of time series split in scikit learn cross-validation?
Answer:
The time series split is a variation of k-fold which was returning the k-fold as a test set.
Conclusion
While evaluating the different types of setting for estimators such as C then we need to manually set the SVM. Scikit learn cross-validation is the technique that was used to validate the performance of our model. By using scikit learn cross-validation we are dividing our data sets into k-folds.
Recommended Articles
This is a guide to Scikit Learn Cross-Validation. Here we discuss the introduction, performance & metrics, iterators, examples, and FAQ. You may also have a look at the following articles to learn more –
