Updated March 16, 2023

Introduction to Scikit Learn Classification
Scikit learn classification is an algorithm that was used in python, this is an essential part of other libraries of python like scipy, numpy, and matplotlib. Scikit learn is a learning library and an open source and it provides the classification and algorithms. The regressor contains the classifier, the classifier first converts the binary targets into -1 and 1 then we are treating this as a regression task problem.
Key Takeaways
- Basically, it is a library of python which includes the classification and regression methods. We are using various classification and regression methods in python.
- The k-nearest neighbor is a very useful method at the time of working with the model into the python.
Overview
The classifier comparison will specify the synthetic datasets. It illustrates the nature of the decision boundaries for the different classifiers, it is taken by using grain salt as conveyed by intuition. In space of high dimensional data is more easily separated and simply classifies by using naïve bayes and SVM generalization by using other classifiers.
Scikit learn is providing easy access to the classification algorithm by using different classifiers. The decision classifier function is breaking down the dataset into smaller subsets by using different criteria. This sorting criterion is used to divide the dataset by using a number of examples with smaller divisions. While the network is divided into data the example will be put into the class which corresponds to the key.
Scikit Learn Classification Model
In it, the response is a class label that was mutually exclusive to credit card transactions. If the number of classes is equal then we can call it a problem of binary classification. Suppose we have more than two classes then we can call the same the problem of multiclass classification. In the below example, we are assuming binary classification because it contains the more general and it will represent the problem of a sequence of multiclass which was representing the binary classification.
Below is the algorithm. It will define different types of algorithms as follows:
- K-nearest neighbors
- Logistic regression
- Naive Bayes
- Support vector machines
- Linear discriminant machines
- Random forests or decision tree classifiers
We are considering estimation of the classification function where the function will estimate the two classes.
Code:
import pandas as pd
import numpy as np
cls = pd.read_csv(‘’, index_col = 0)
indx = np.where(cls.default == 'No')[0]
scikit = np.random.RandomState(13)
scikit.shuffle(indx)
learn = (cls.default == 'Yes').sum()
cls = cls.drop(cls.index [indx[learn:]])
cls.head()Output:

Different classification techniques are compared by using decision surface. The surface of the decision is described using predictors which model changes its predictions also it will contain the different shapes. In below example shows classification techniques as follows.
Code:
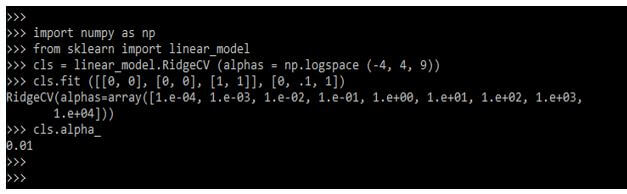
import numpy as np
from sklearn import linear_model
cls = linear_model.RidgeCV (alphas = np.logspace (-4, 4, 9))
cls.fit ()
cls.alpha_Output:
Scikit Learn Classification Methods
Below are the different classifier methods in scikit learn. K-nearest neighbor is an important method in classification.
1. K-Nearest Neighbor
This model calculates the class membership for the dependent variable which was calculating the distance of k nearest neighbors. KNN model is intensive and compute. The below example shows scikit learn k-nearest neighbors as follows.
Code:
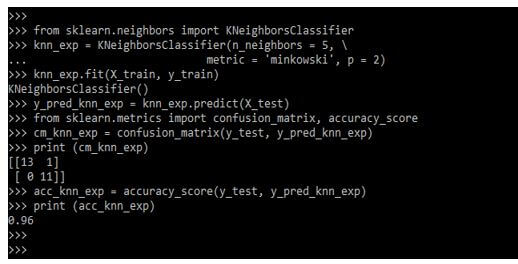
from sklearn.neighbors import KNeighborsClassifier
knn_exp = KNeighborsClassifier(n_neighbors = 5, \
metric = 'minkowski', p = 2)
knn_exp.fit (X_train, y_train)
y_pred_knn_exp = knn_exp.predict (X_test)
from sklearn.metrics import confusion_matrix, accuracy_score
cm_knn_exp = confusion_matrix(y_test, y_pred_knn_exp)
print (cm_knn_exp)
acc_knn_exp = accuracy_score (y_test, y_pred_knn_exp)
print (acc_knn_exp)Output:
2. Support Vector Classifier
This method is returning hyper plane which was dividing the data as follows.
Code:
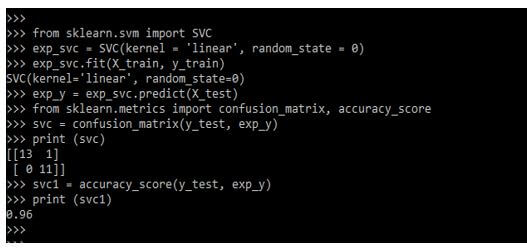
from sklearn.svm import SVC
exp_svc = SVC(kernel = 'linear', random_state = 0)
exp_svc.fit(X_train, y_train)
exp_y = exp_svc.predict(X_test)
from sklearn.metrics import confusion_matrix, accuracy_score
svc = confusion_matrix(y_test, exp_y)
print (svc)
svc1 = accuracy_score(y_test, exp_y)
print (svc1)Output:
3. Kernel SVM
We can use the support vector machine function in this classifier as follows.
Code:
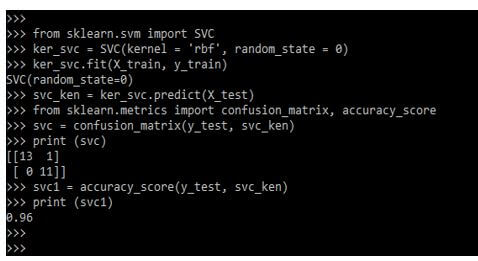
from sklearn.svm import SVC
ker_svc = SVC(kernel = 'rbf', random_state = 0)
ker_svc.fit(X_train, y_train)
svc_ken = ker_svc.predict(X_test)
from sklearn.metrics import confusion_matrix, accuracy_score
svc = confusion_matrix(y_test, svc_ken)
print (svc)
svc1 = accuracy_score(y_test, svc_ken)
print (svc1)Output:
4. Naive Bayes
The naive bayes classifier method is a collection of algo which was based on bayes as follows.
Code:
from sklearn.naive_bayes import GaussianNB
sk_nb = GaussianNB()
sk_nb.fit(X_train, y_train)
naive = sk_nb.predict (X_test)
from sklearn.metrics import confusion_matrix, accuracy_score
bayee = confusion_matrix(y_test, naive)
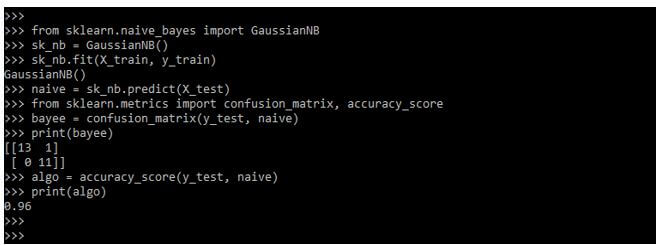
print(bayee)
algo = accuracy_score(y_test, naive)
print(algo)Output:
5. Decision Tree
The decision tree is a series of if-else rules which was learned from data classification as follows.
Code:
from sklearn.tree import DecisionTreeClassifier
ds = DecisionTreeClassifier(criterion = 'entropy', random_state = 0)
ds.fit (X_train, y_train)
tree = ds.predict(X_test)
from sklearn.metrics import confusion_matrix, accuracy_score
ds_tree = confusion_matrix(y_test, tree)
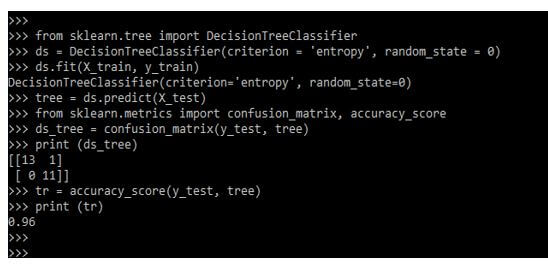
print (ds_tree)
tr = accuracy_score(y_test, tree)
print (tr)Output:
6. AdaBoost Classifier
It is used in conjunction with other types as follows.
Code:
from sklearn.ensemble import AdaBoostClassifier
ada = AdaBoostClassifier()
ada.fit(X_train, y_train)
boost = ada.predict(X_test)
from sklearn.metrics import confusion_matrix, accuracy_score
cl = confusion_matrix(y_test, boost)
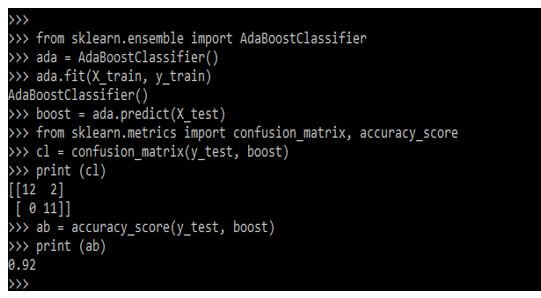
print (cl)
ab = accuracy_score(y_test, boost)
print (ab)Output:
7. MLP Classifier
We are training the classifier model into a training set as follows.
Code:
from sklearn.neural_network import MLPClassifier
exp_mlp = MLPClassifier(alpha=1, max_iter=1000)
exp_mlp.fit (X_train, y_train)
exp_pred = exp_mlp.predict(X_test)
from sklearn.metrics import confusion_matrix, accuracy_score
ml = confusion_matrix(y_test, exp_pred)
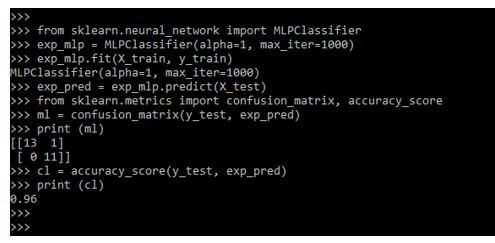
print (ml)
cl = accuracy_score(y_test, exp_pred)
print (cl)Output:
Scikit Learn Classification Regression
Python is providing multiple tools to implement classification and regression. Scikit is performing classification and regression in very simple terms.
The below steps show how we can perform classification and regression in scikit learn as follows.
- Load the libraries
- Load the dataset
- Train model
- Evaluate model
The below example shows how we can implement the classification and regression as follows.
Code:
import numpy as np
import pandas as pd
from sklearn.metrics import f1_score,accuracy_score
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
X, y = make_classification ()
ref = LinearDiscriminantAnalysis ()
reg_mod = RepeatedStratifiedKFold ()
reg = cross_val_score()
print ('Accuracy: (reg)))Output:
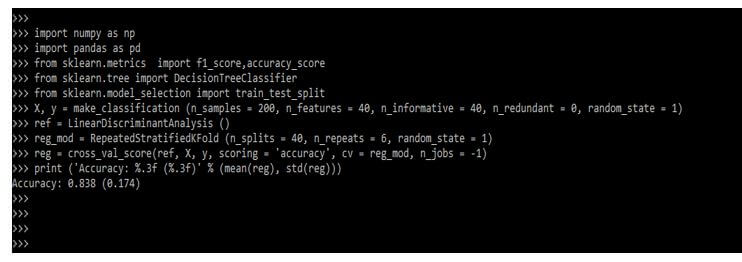
Examples of Scikit Learn Classification
Given below are the examples mentioned:
Example #1
Here we are defining the KNN classifier.
Code:
from sklearn.neighbors import KNeighborsClassifier
class_knn = KNeighborsClassifier(n_neighbors = 7, \
metric = 'minkowski', p = 4)
class_knn.fit(X_train, y_train)
knn_y = class_knn.predict (X_test)
from sklearn.metrics import confusion_matrix, accuracy_score
knn_cm = confusion_matrix(y_test, knn_y)
print (knn_cm)
cm = accuracy_score(y_test, knn_y)
print (cm)Output:
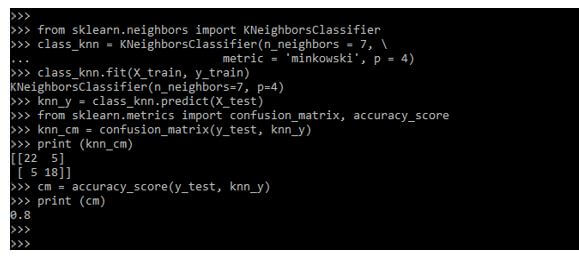
Example #2
In the below example, we are defining the decision tree classifier.
Code:
from sklearn.tree import DecisionTreeClassifier
ds_exp = DecisionTreeClassifier(criterion = 'entropy', random_state = 0)
ds_exp.fit (X_train, y_train)
tree_exp = ds_exp.predict (X_test)
from sklearn.metrics import confusion_matrix, accuracy_score
ds_class = confusion_matrix(y_test, tree_exp)
print (ds_class)
dt = accuracy_score(y_test, tree_exp)
print (dt)Output:
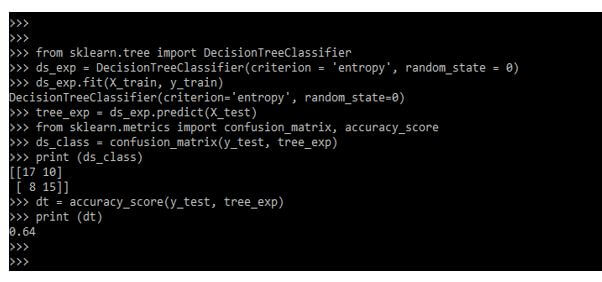
FAQ
Given below are the FAQs mentioned:
Q1. Why do we use regression and classification in python?
Answer:
We are using scikit learn to perform the classification and regression by using algorithms of classification, we are using regression in python.
Q2. What are the types of classification available in scikit learn python?
Answer:
Basically, there are two types of classification available in scikit learn i.e. multi-class classification and binary classification. Binary classification is storing the data on this basic of non-continuous values.
Q3. How do we use classification in scikit learn?
Answer:
We use multiple classification methods to do the classification in scikit learn python like KNN and decision tree.
Conclusion
The scikit learn classifier illustrates the nature of the decision boundaries for different classifiers, it is taken by using grain salt as conveyed by intuition. The regressor contains the classifier, the classifier first converting the binary targets into -1 and 1 then we are treating this as a regression task problem.
Recommended Articles
This is a guide to Scikit Learn Classification. Here we discuss the introduction to scikit learn classification, methods, regression, examples, and FAQ respectively. You may also have a look at the following articles to learn more –
