Updated May 15, 2023

Introduction to Redshift with
Redshift with clause is used on an optional basis along with the SELECT statement specified just after the with. This is mostly used for defining the temporary table which is created by the specification of one or more common table expressions also referred to as (CTE). This temporary table can be referenced inside the FROM clause one or more than one time in the same query statement where we have used the with a clause to define it.
The temporary tables work just kind of a view definition with a scope limited to that query only. The common table expression contains the name of the table or tables, the name of the columns whose value needs to be stored, and the expressions whose values can be evaluated to the select statement which is used. The common table expression works in a recursive manner if we refer to the same temporary table created by it in from clause of the same common table expression.
In this article, we will study the syntax of with clause in redshift, how it works, and how it can be implemented with the help of certain examples.
Syntax:
The syntax of the Redshift with a clause in Amazon is as shown below containing the two possibilities of its usage –
[WITH [RECURSIVE] common table expression [, any number of common table expressions, …] ]
The common table expression can be used in the above syntax in either of the two ways which are recursive and non-recursive. Each one of them has a different syntax. The below syntax is for the use of non-recursive common table expression –
Name of the CTE table [(name of the column [, …])] AS query statement
Another way of using the common table expressions in a way which will be called recursively is as shown in the below syntax –
Name of the CTE table (name of the column [, …]) AS (query which is recursive in nature)
Let us discuss in detail the terminologies used in the above syntaxes –
RECURSIVE – This keyword is used in the WITH clause when the common table expression will contain a recursive query. It is a required parameter in case if the CTE is recursive in nature. The specification of the RECURSIVE keyword can be done only once after the WITH clause even if we specify multiple common table expressions which are recursive in nature after with. The execution of common table expression in a recursive manner is generally treated as the UNION ALL subquery of the specified two parts of the query.
Common table expression – The specification of the CTE helps in creating a temporary table that can be referenced inside the FROM clause of the query statement once or multiple times. This reference can only be done when the reference is made in the same query to which it belongs and only during the execution of that query statement.
Name of the column – This is the list of the values of the columns for creating the temporary table in clause subquery which is a comma-separated list. The number of the specified columns in the list has a restriction that the number should be less than or equal to the one specified in the subquery columns. The specification of the name of columns is required while using recursive common table expression while optional in the case of non-recursive common table expression.
Query statement or the one which is recursive in nature. – This can be any valid SELECT query statement in Amazon Redshift or when the recursive query is made then it should contain a query containing UNION ALL clause containing two subqueries.
In the case of a recursive query, the first query statement does not have the reference in recursive format to the same CTE table as it is referred to as the seed member or initial member. The second part of the recursive query is the one that takes the initial seed of the recursion created by the first select subquery and refers to the same subquery in recursive format. The second subquery is called a recursive member. This part contains the WHERE clause that ends the query statement used for recursion.
How does Redshift With works?
The temporary tables created by using the with clause can be used any number of times throughout the query in a very effective and efficient way. It becomes very easy and simple to write and read the queries and the subqueries by using with even though the other methods give the same performance and results. The optimization of with clause to common subexpressions is done when it contains the subqueries that refer to the common table expression multiple times and is possible to do. Because of this optimization, the evaluation of the temporary table of with is done only once and can be used as many times as required inside that query statement. We can make use of the WITH clause along with the following SQL statements – CREATE TABLE AS, SELECT, DECLARE, SELECT INTO, CREATE VIEW, EXPLAIN, PREPARE, INSERT INTO SELECT, DELETE and UPDATE.
Examples
Let us consider one example where we have a table named educba_articles whose contents can be seen by executing the below query.
SELECT * FROM [educba_articles];
The output is as shown below –
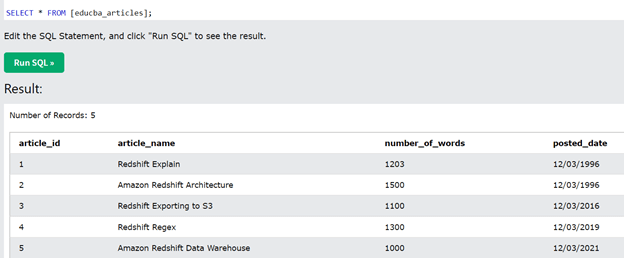
Now, we will write a query which uses with a clause in the simplest format to retrieve all the data from the table having article id less than 3 and then creating the temporary table of it which can be further referred and we will display the data in order keeping the maximum limit of rows retrieved as 10. Our query statement will become as shown below –
WITH written_articles AS
(
SELECT *
FROM educba_articles
WHERE article_id <3)
SELECT *
FROM written_articles
ORDER BY 1 limit 10;
The output of the execution of the above query is as shown below –

Conclusion
The use of WITH clause in Amazon redshift can be done to create a common table expression which will, in turn, create a temporary table whose data can be referred to once or multiple times inside the same query where it is created.
Recommended Articles
This is a guide to Redshift with. Here we discuss the syntax of with clause in redshift, how it works and how it can be implemented with the help of certain examples. You may also have a look at the following articles to learn more –

