Updated March 8, 2023

Difference Between Random Forest vs XGBoost
The following article provides an outline for Random Forest vs XGBoost. A machine learning technique where regression and classification problems are solved with the help of different classifiers combinations so that decisions are based on the outcomes of the decision trees is called the Random Forest algorithm. Average of the output is considered so that if the decision trees are more, the accuracy will be higher. Extreme Gradient Boosting or XGBoost is a machine learning algorithm where several optimization techniques are combined to get perfect results within a short span of time. Overfitting is avoided with the help of regularization and missing data is handled perfectly well along with cross-validation of facts and figures.
Head to Head Comparison Between Random Forest vs XGBoost (Infographics)
Below are the top 5 differences between Random Forest vs XGBoost:
Key Difference Between Random Forest vs XGBoost
Let us discuss some of the major key differences between Random Forest vs XGBoost:
- Random Forest and XGBoost are decision tree algorithms where the training data is taken in a different manner. XGBoost trains specifically the gradient boost data and gradient boost decision trees. The training methods used by both algorithms is different. We can use XGBoost to train the Random Forest algorithm if it has high gradient data or we can use Random Forest algorithm to train XGBoost for its specific decision trees. Also, we can take samples of data if the training data is huge and if the data is very less, we can use the entire training data to know the gradient of the same.
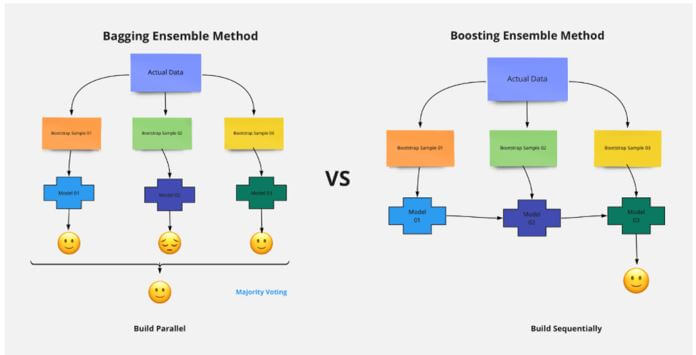
- XGBoost helps in numerical optimization where the loss function of the data is minimized with the help of weak learners so that iteration happens in the local function in a differentiable manner. Sample is not modified here but different levels of importance are given to each feature in the data. Random Forest is mostly a bagging technique where various subsets are considered and an average of each subset is calculated. Either random subset of features or bootstrap samples of data is taken for each experiment in the data.
- Random subsamples of data are selected for Random Forest where the growing happens in parallel and overfitting is reduced with the combination of several underfitting features in the algorithm. Only a random subset of features is selected always that are included in the decision tree so that the result is not dependent on any subset of data. Overfitting is reduced with the help of regularization parameters in XGBoost that helps to select features based on weak and strong features in the decision tree. Algorithm is the combination of sequential growth by combining all the previous iterations in the decision trees. Optimal values of each leaf are calculated and hence the overall gradient of the tree is given as the output.
- Several hyperparameters are involved while calculating the result using XGBoost. Some include regularization rate, subsample, minimum weights, maximum depths, and learning rates. Though XGBoost is noted for better performance and high speed, these hyperparameters always stop developers from looking into this algorithm. Hyperparameters are not needed in Random Forest and developers can easily understand and visualize Random Forest algorithm with few parameters present in the data.
Random Forest vs XGBoost Comparison Table
Let’s discuss the top comparison between Random Forest vs XGBoost:
| Random Forest |
XGBoost |
| In Random Forest, the decision trees are built independently so that if there are five trees in an algorithm, all the trees are built at a time but with different features and data present in the algorithm. This makes developers look into the trees and model them in parallel. | XGBoost builds one tree at a time so that each data pertaining to the decision tree is taken into account and the data is filled if there are any missing data. This helps developers to work with gradient algorithms along with the decision tree algorithm for better results. |
| Once all the decision trees are built, the results are calculated by taking the average of all the decision tree values. This makes the developers to wait for building all the decision trees to the end and the cumulative results are taken into account. | While developers are building the decision trees, the results are calculated and added up for the next tree and hence the gradient of the results is considered. This helps developers to get an idea of the results even if the decision trees take time. |
| The calculation takes time and it is not accurate when compared to XGBoost. So, developers do not completely depend on Random Forest if there are other algorithms available. But, this is easy to do calculations even for beginners. | Since gradient of the data is considered for each tree, the calculation is faster and the precision is accurate than Random Forest. This makes developers to depend on XGBoost than Random Forest. XGBoost is complex than any other decision tree algorithms. |
| If the field of study is bioinformatics or multiclass object detection, Random Forest is the best choice as it is easy to tune and works well even if there are lots of missing data and more noise. Overfitting will not happen easily. | With accurate results, XGBoost is hard to work with if there are lots of noise. Also, it is hard to tune as well. If the data is real-time so the data is unbalanced, we can use XGBoost where it performs exceptionally well. |
| Random Forest has many trees with leaves of equal weight so that high accuracy and precision can be obtained easily with the available data. This makes the developers add more features to the data and look at how it performs for all the data given to the algorithm. | XGBoost does not account for the number of leaves present in the algorithm. If the model predictability is not good, the algorithm performs better with more leaves in the decision tree. This improves the bias and the results completely depends on the data present in the algorithm. |
Conclusion
It is important to have knowledge of both algorithms to decide which one to use for our data. If the dataset has no many differentiations and we are new to decision tree algorithms, it is better to use Random Forest as it provides a visualized form of the data as well. If we want to explore more about decision trees and gradients, XGBoost is good option.
Recommended Articles
This is a guide to Random Forest vs XGBoost. Here we discuss key differences with infographics and comparison table respectively. You may also have a look at the following articles to learn more –
