Updated February 22, 2023

Introduction to PySpark MLlib
PySpark is nothing but Spark’s machine learning library; it provides different features to the users. For example, with the help of pyspark MLlib, we can create a machine learning algorithm with a scalable and easy mode. In other words, we can say that it provides the different common machine learning algorithms such as regression, clustering, filtering, classification, etc. Normally Apache Spark provides the Machine learning algorithm API we implemented in Python as per our requirement.
Key Takeaways
- It provides a simple and easy implementation.
- It supports R and Python programming, which means data scientists.
- It is scalable, and we can easily scale.
- Synchronization, as well as error handling, is easy.
- Mllib provides many useful algorithms that we can easily implement.
What is PySpark MLlib?
We know that PySpark Mllib is a machine learning library, it is a single-source platform to analyze the data using different machine learning algorithms over the distributed and scalable platform with different types of algorithms as follows:
- mllib.classification: The mllib packages support the different types of regression analysis and multiclass classification methods. Many different classification algorithms exist, such as Random Forest, Naïve Bayes, Decision Tree, etc.
- mllib.clustering: This is an unsupervised learning problem; here, we need to group subsets of entities based on another class.
- mllib.fpm: Pattern matching is one of the frequent mining items, subsets, or we can say that substructure. This is the first step toward the analysis of the large-scale dataset.
- mllib.linalg: We can also use millib to resolve the linear algebra problems.
- mllib.recommendation: Collaborative filtering is one of the most used techniques in mllib, and it is a recommender algorithm. By using this technique, we can easily identify missing entries.
- mllib.spark: It supports collaborative filtering, using a small set of data from the user and product side to identify the missing entries. Normally it uses the Alternating Least Squares algorithm.
- mllib.regression: By using linear regression, we can find the relationship between the dependencies of variables, which is similar to logistic regression. There are many other algorithms, classes, and functions to implement the pyspark.mllib.
PySpark MLlib Finding Hackers
Let’s assume organization data was hacked, and it accesses a lot of information, and hackers used that information to access the metadata. There are three types of hackers. Normally general practice is that tradeoff of the job; let’s see an example of clustering as follows.
First, we need to initialize the Spark session as follows:
Code:
from pyspark.sql import SparkSession
spark_variable = SparkSession.builder.appName('find_hacker').getOrCreate()We must import the KMeans Library and load the dataset in the second step. Here we use K Means Algorithm to do the analysis, so we first need to import the Kmeans Library and load the dataset with spark.read method.
Code:
from pyspark.ml.clustering import KMeans
dataset = spark.read.csv("specified path of file", header, inferSchema)Now we need to retrieve data, so print the dataSchema(). The result is shown in the below screenshot as follows.
Output:

PySpark MLlib Algorithm and API
Let’s see what algorithms and API is available in mllib as follows:
- ML Algorithm: Machine Learning is a core algorithm of Mllib; it includes the command and basic algorithm of mllib, such as clustering, classification, regression, etc.
- Transformer: This is another type of algorithm used to transform one data frame to another frame, and it uses a transformer().
- Estimator: With the help of this algorithm, we can generate the Transformer, and it uses method fit().
- Featurization: It is used for feature extraction such as transformation, selection, dimensionality, etc. In other words, we can say that it is used to extract the required data from raw data.
- Pipelines: A Pipeline chains numerous Transformers and Estimators together to determine an ML work process. It likewise gives apparatuses to building, assessing, and tuning ML Pipelines.
- Persistence: It is used to save and load the algorithm Pipelines and models. By using this algorithm, we can reduce time and effort.
- Utilities: By using this algorithm, we can implement statistics, algebra, and data handling.
There are two find APIs as follows:
Spark.ml is the essential ML library in Spark. spark.mllib is in upkeep mode. This implies that it tends to be utilized and will have bug fixes yet won’t have any new highlights.
As of Spark 2.0, the RDD-based APIs in the Spark.mllib bundle has entered upkeep mode. The essential Machine Learning API for Spark is currently the DataFrame-based API in Spark.ml bundle.
DataFrames give an additional easy-to-use API than RDDs. The many advantages of DataFrames incorporate Spark Data Sources, SQL/DataFrame questions, Tungsten and Catalyst improvements, and uniform APIs across dialects.
PySpark MLlib Lifecycle
Let’s see the lifecycle of mllib as follows. Basically, there are two major parts, as shown in the below screenshot as follows:
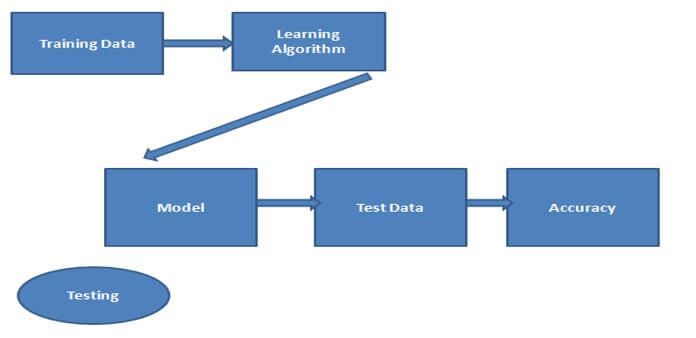
- Training
- Testing
We know that in ML, we create a model to predict raw data, so we use training data and test that data. After that, models generate the prediction result, which we call the test set that we will divide into the two sets as follows.
- Training Set: This is a training dataset used to extract data from whatever we require.
- Testing Set: After the generation of a model, we can predict the result through the training set.
PySpark MLlib Package
Let’s describe the packages we require as follows:
- class pyspark.ml.Transformer: It is used to transform the dataset into another dataset, and this is nothing but the abstract class.
- class pyspark.ml.UnaryTransformer: This is also an abstract class and is used to apply a transformation on a single input column into the new column as a result.
- class pyspark.ml.Estimator: It is used to fit data to the model.
We also required different packages as follows:
class pyspark.ml.Model, class pyspark.ml.Pipeline, class pyspark.ml.PipelineModel etc. As well as we also required pysark.ml.param module
FAQ
Given below are the FAQ mentioned:
Q1. There is any difference between spark ml and spark MLlib?
Answer:
Yes, basically, spark ml includes the high-level API, and spark MLlib contains two APIs.
Q2. Spark MLlib deprecated?
Answer:
No, basically, it includes the RDD and DataFrame-based API.
Q3. What different types of tools are available?
Answer:
It has different tools such as Featurization, Pipelines, Utilities, etc.
Conclusion
In this article, we are trying to explore PySpark MLlib. We saw different types of PySpark MLlib and the uses and features of these PySpark MLlib. Another point from the article is how we can perform and set up the PySpark MLlib.
Recommended Articles
This is a guide to PySpark MLlib. Here we discuss the introduction, PySpark MLlib finding hackers, algorithm and API, lifecycle and package. You may also have a look at the following articles to learn more –

