Updated April 1, 2023

Introduction to PySpark kmeans
PySpark kmeans is a method and function used in the PySpark Machine learning model that is a type of unsupervised learning where the data is without categories or groups. Instead, it groups up the data together and assigns data points to them. This model approach is used for prediction or machine learning analysis of data in the PySpark machine learning model. We have a various model in PySpark that is used to import the data elements and to apply the kmeans algorithm logic to it. Furthermore, the data can be used further for prediction by applying the vector assembler that is a part of the PySpark kmeans data model. Here we will analyze the various method used in kmeans with the data in PySpark.
Syntax of PySpark kmeans
Given below is the syntax mentioned:
from pyspark.ml.clustering import KMeans
kmeans_val = KMeans(k=2, seed=1)
model = kmeans_val.fit(b.select('features'))- .Import statement that is used.
- kmeans_val: Using the kmeans library to define the clusters and seed.
- Model: Uses the algorithm to introduce the kmean algorithm there.
ScreenShot:

Working of kmeans in PySpark
Given below shows how kmeans operation works in PySpark:
- The kmean algorithm is based on clustering of data based on data points needed. The data is divided into smaller and bigger groups of data based on the number of clusters provided. The cluster works on centroid, which is apparently equal to the number of clusters provided.
- Once the clusters are assigned, the centroid values are again recalculated, and the convergence criterion is tired to be achieved. This convergence criteria measures the stability of the cluster. The data to be used are first passed to a Vector assembler that converts a set of features into a single vector. Post this; only the method can be used for transformation purposes.
- The parameters used by kmeans is k for the number of clusters provided by the user that decides the chunk in which the data needs to be put on.
- We can also give the values like maximum iteration, initial value, seed value and then can apply kmean algorithm over the data.
Example of PySpark kmeans
Given below is the example of PySpark kmeans:
Let’s start by creating a simple data frame in PySpark on which we can use the kmeans.
Code:
df = spark.createDataFrame([[0, 35.3, 37.5],
[1, 41.4, -23.5],
[2, 28.3, -13.3],
[3, 09.5, -9.0],
[4, 62.8, -18.23],
[5, 63.8, -18.33],
[6, 82.8, -17.23],
[7, 52.8, -13.43],
[8, 72.8, 48.23],
[9, 65.8, 15.43],
[10, 42.8, -13.23]
],
["ID","Att_1", "Att_2"])
df.show()Output:
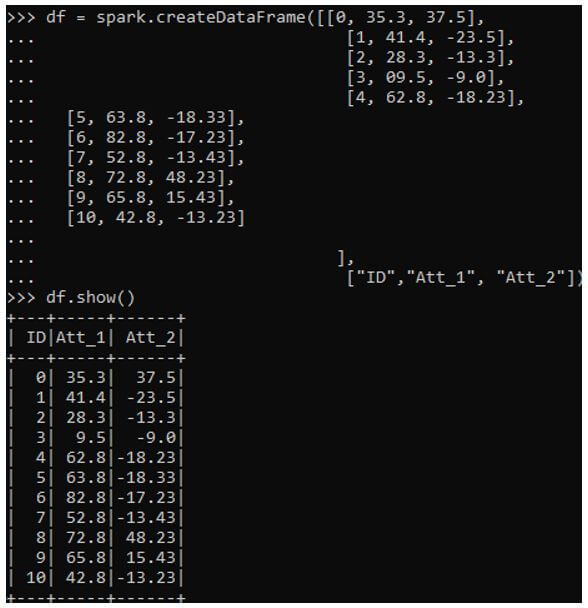
The vector assemble is used to convert the elements needed for this model into features. It is a transformer converting it into an array of features. The un used columns are first extracted from data, and the rest is then used for transformation.
Code:
vecAssembler = VectorAssembler(inputCols=["Att_1", "Att_2"], outputCol="features")The attributes are then transformed in to single vector column, i.e. features.
Code:
new_df = vecAssembler.transform(df)
new_df.show()Output:
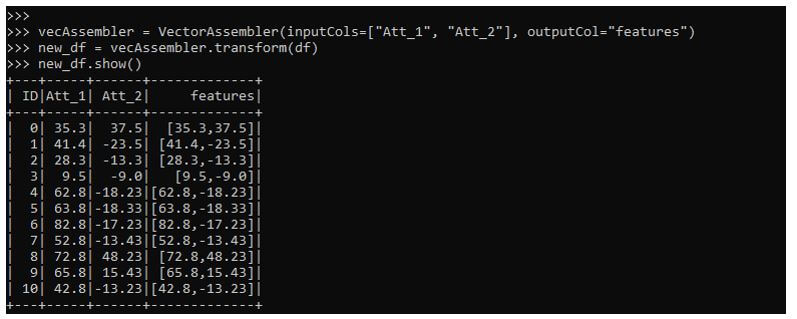
The necessary import needed from the pysaprk.ml clustering is imported, which has the Kmeans method in it. The cluster size is provided, and the data model is fit with the new transformed data frame.
Code:
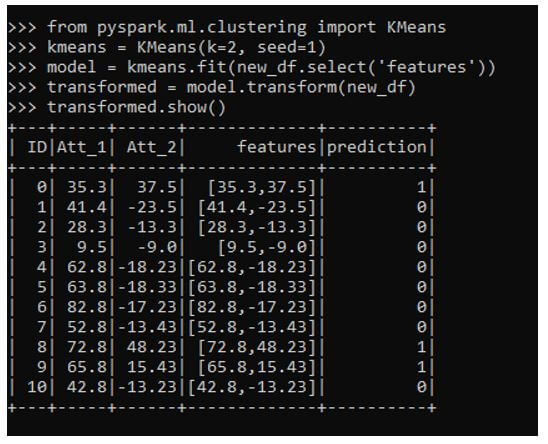
from pyspark.ml.clustering import KMeans
kmeans = KMeans(k=2, seed=1)
model = kmeans.fit(new_df.select('features'))
transformed = model.transform(new_df)
transformed.show()This comes up with the prediction column that defines the prediction that shows which attribute qualifies for which category.
Output:
Conclusion
From the above article, we saw the working of kmean in PySpark. Then, from various examples and classification, we tried to understand how this kmean operation happens in PySpark and what is used at the programming level. We also saw the internal working and the advantages of kmean in PySpark Data Frame and its usage in various programming purposes. Also, the syntax and examples helped us to understand much precisely over the function.
Recommended Articles
This is a guide to PySpark kmeans. Here we discuss the introduction, working of kmeans in PySpark, and examples, respectively. You may also have a look at the following articles to learn more –

