Updated May 29, 2023

Introduction to PostgreSQL Architecture
As we know that PostgreSQL is the most advanced relational database management system. PostgreSQL architecture uses two models.
- Client
- Server
The client sends a request to the PostgreSQL server, and the PostgreSQL server responds to the client’s request. In typical application client and server is on a different host in that scenario, they will communicate through TCP/IP network connection. PostgreSQL server handling multiple concurrent sessions from the client. To achieve this by, starting a new process for each connection. From that point, the new server process and the client will communicate without another process intervention. PostgreSQL has its own background processes to manage the PostgreSQL server.
Architecture of PostgreSQL
The physical structure of PostgreSQL is straightforward; it consists of the following components:
- Shared Memory
- Background processes
- Data directory structure / Data files
The below figure shows the PostgreSQL Architecture.
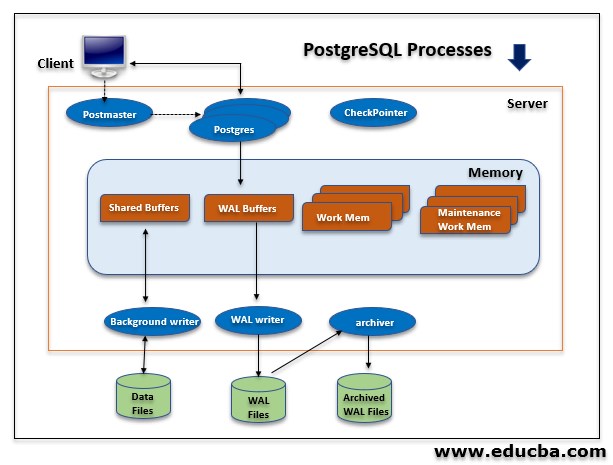
1. Shared Memory
Shared memory refers to the memory reserved for transactional and another log catches. It consists of the following components:
Shared Buffers
- We need to set some amount of memory to a database server for the use of shared buffers. The default value of shared buffers in 9.2 and the older version is 32 megabytes (32 MB) from 9.3, and the later default value of shared buffers is 128 megabytes (128 MB).
- For a dedicated server hosting PostgreSQL, a reasonable initial value to set for shared buffers is 25% of the total memory. The purpose of shared buffers is to minimize server DISK IO.
WAL Buffers
- WAL buffers serve the purpose of temporarily storing changes in the database. The WAL buffers write the changes to the WAL file at a predetermined time. WAL buffers and WAL files are significant to recover the data at some peak of time during backup and recovery.
- The minimum value of shared buffers is 32 KB. If we set this parameter as wal_buffers = -1, it will be set based on shared_buffers.
Work Memory
- To allocate a specific amount of memory per client connection for internal sort operations and hash tables used in writing data into temporary disk files.
- The default value of work memory in 9.3 and the older version is 1 megabyte (1 MB) from 9.4, and the later default value of work memory is 4 megabytes (4 MB).
Maintenance Work Memory
- We need to specify the maximum amount of memory for database maintenance operations such as VACUUM, ANALYZE, ALTER TABLE, CREATE INDEX, ADD FOREIGN KEY, etc.
- The default value of maintenance work memory in 9.3 and the older version is 16 megabytes (16 MB) from 9.4, and the later default value of maintenance work memory is 64 megabytes (64 MB).
- It is safe to set maintenance work memory is large as compared to work memory. Larger settings will improve maintenance performance (VACUUM, ANALYZE, ALTER TABLE, CREATE INDEX, and ADD FOREIGN KEY, etc.) operations.
2. Background Processes
Below are the background processes of PostgreSQL. Each process has its individual features and PostgreSQL internals. Each process details will be described as follows:
Background Writer process: In PostgreSQL 9.1 version background writer regularly does the checkpoint processing. The separation of the checkpointer process and the background writer process occurred in the PostgreSQL 9.2 version. It will keep logs and backup information up to date.
WAL Writer: This process periodically writes and flushes the WAL data on the WAL buffer to persistent storage.
Logging Collector: This process is also called a logger. It will write a WAL buffer to the WAL file.
autovacuum Launcher: When autovacuum is enabled, this process has the autovacuum daemon’s responsibility to carry vacuum operations on bloated tables. This process relies on the stats collector process for perfect table analysis.
Archiver: If we enable archive mode, this process has the responsibility to copy the WAL log files to a specified directory.
Stats Collector: In this process, Statistics information like pg_stat_activity and for pg_stat_database is collected. Information is passed from the stats collector via temporary files to requesting processes.
Checkpointer Process: In PostgreSQL 9.2 and later versions checkpoint process is performed. This process’s actual work is when a checkpoint occurs, it will write a dirty buffer into a file.
Checkpointer: Checkpointer will write all dirty pages from memory to disk and clean the shared buffer area. If the PostgreSQL database is crashed, we can measure data loss between the last checkpoint time, and PostgreSQL stopped time. Executing the checkpoint command manually triggers an immediate checkpoint. Only database superusers can call checkpoint.
The checkpoint will occur in the following scenarios:
- The pages are dirty.
- Starting and restarting the DB server (pg_ctl STOP | RESTART).
- Issue of the commit.
- Starting the database backup (pg_start_backup).
- Stopping the database backup (pg_stop_backup).
- Creation of the database.
3. Data Files / Data Directory Structure
- PostgreSQL consists of multiple databases; this is called a database cluster. Template0, template1, and Postgres databases are created when we initialize the PostgreSQL database.
- Template0 and template1 are template databases for new database creation of user it contains the system catalog tables.
- The user database will be created by cloning the template1 database.
PGDATA directory contains several subdirectories, and control files are as follows.
- pg_version: It contains database version information.
- Base: Containing database subdirectories.
- Global: Containing cluster wise tables such as pg_user.
- pg_clog: Containing transaction commits status data.
- pg_multixact: Containing multi transaction status data (used for shared row locks).
- pg_notify: Containing LISTEN/NOTIFY status data.
- pg_serial: Containing information about committed serializable transactions.
- pg_snapshots: Containing exported snapshots.
- pg_stat_tmp: Containing temporary files for the statistics subsystem.
- pg_subtrans: Containing sub-transaction status data.
- pg_tblspc: Containing symbolic links to tablespaces.
- pg_twophase: Containing state files for prepared transactions.
- pg_xlog: Containing WAL (Write Ahead Log) files.
- pid: This file containing the current postmaster process ID (PID).
Conclusion
PostgreSQL architecture mainly divided into two models client and server. The client sends a request to the server; the PostgreSQL server process the data using shared buffers and background processes and send a response back to the client. The data directory contains the physical file of the PostgreSQL database server.
Recommended Articles
We hope that this EDUCBA information on “PostgreSQL Architecture” was beneficial to you. You can view EDUCBA’s recommended articles for more information.
