Updated September 15, 2023
Difference Between Pandas vs NumPy
Python for Data Analysis: Using NumPy and Pandas” is your gateway to a world of data-driven insights to empower data enthusiasts, analysts, and scientists with the essential skills needed to effectively manipulate, analyze, and draw insights from data using the Python programming language. This article serves as a foundational resource for anyone seeking to harness the power of two fundamental libraries—NumPy and Pandas—to navigate the intricate landscape of data analysis. This guide equips readers with the essential skills to navigate the complexities of data analysis, enabling them to uncover patterns, trends, and correlations within data, thus facilitating informed decision-making across various domains and industries.
NumPy
NumPy, short for “Numerical Python,” is a powerful open-source Python library for numerical computing. This software allows users to work with vast arrays and matrices in various dimensions. The software offers multiple mathematical functions that can efficiently operate on the data, making the entire process much more manageable and efficient. NumPy is a fundamental library in the Python scientific computing ecosystem and serves as a building block for various other libraries and applications.
Importing NumPy in Python Notebooks: The np Alias Convention
NumPy can be imported into a Python notebook using the import statement as follows:
import numpy as npKey Features
- Multidimensional Arrays: NumPy introduces the ndarray class, allowing you to create and manipulate arrays of various dimensions efficiently.
- Broadcasting: NumPy enables broadcasting, which allows operations on arrays of different shapes without explicitly looping over them.
- Vectorized Operations: NumPy functions and operations operate on entire arrays, resulting in faster and more concise code.
- Mathematical Functions: NumPy provides various mathematical functions for array manipulation, including linear algebra, Fourier transforms, and random number generation.
- Indexing and Slicing: NumPy supports advanced indexing and slicing techniques for accessing and modifying array elements.
Important Attributes of a NumPy Array
- Shape: The shape of a NumPy array is a tuple that specifies the array’s dimensionality. For instance, a 1-dimensional array containing 5 elements will have a shape of (5,). The shape of a 2-dimensional array with 3 rows and 4 columns is denoted as (3, 4).
- dtype: The dtype attribute indicates the data type of the elements stored in the NumPy array. NumPy assists many data types, including integers, floats, complex numbers, and more specialized types like strings or datetime objects.
- ndim: The ndim attribute gives the number of dimensions or axes of the array. For example, a 1-dimensional array has an ndim of 1, a 2-dimensional array has an ndim of 2, and so on.
- size: The size attribute returns the total number of elements in the NumPy array. It is equal to the product of all the elements in the shape tuple.
- itemsize: The item size attribute represents the size in bytes of each element in the NumPy array.
- nbytes: The nbytes attribute returns the total memory size occupied by the array in bytes. To calculate it, multiply the item size by the array size.
- data: The data attribute provides a buffer that points to the start of the array’s data. It is rarely used directly but can be useful for interfacing with other libraries or performing low-level operations.
- flags: The flags attribute is a dictionary containing information about the memory layout of the array, such as whether it is read-only, C-contiguous, or Fortran-contiguous.
| Command | Definition | Examples |
| np.array() | Create an array using the np.array() function from an existing Python list or tuple. |
Output:
|
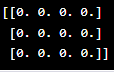
| np.zeros() | Create an array filled with zeros. |
Output:
|
| np.ones() | Create an array filled with ones. |
|
| np.full() | Create an array filled with a specific value. |
Output:
|
| np.arange() | Create an array with a range of values. |
Output:
|
| np.linspace() | Create an array with evenly spaced values over a specified range. |
Output:
|
| np.eye() | Create an identity matrix (a square matrix with ones on the main diagonal and zeros elsewhere). |
Output:
|
| np.random.rand() | Create an array with random values from a uniform distribution between 0 and 1. |
Output:
|
| np.random.randint() | Create an array with random integer values within a specified range. |
Output:
|
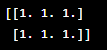
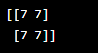
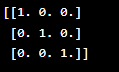
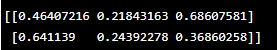
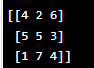
Pandas
Pandas is a popular open-source Python library for data manipulation and analysis. It provides the data structures and functions needed to work efficiently with structured data, making it a powerful tool for data wrangling, cleaning, exploration, and analysis.
Pandas can be imported into a Python notebook using the import statement as follows:
import pandas as pdKey Features of Pandas
- DataFrame: The DataFrame is a central data structure in Pandas, resembling a table with rows and columns. It allows easy storage and manipulation of heterogeneous, labeled data.
- Series: A Series resembles a one-dimensional labeled array, much like a column in a spreadsheet, and people often use it to represent a single column of data.
- Data Alignment: Pandas automatically aligns data based on labels, making working with data from different sources easy.
- Missing Data Handling: Pandas provides methods for handling missing data, allowing you to fill, drop, or interpolate missing values.
- Grouping and Aggregation: Pandas supports powerful grouping and aggregation operations, enabling you to summarize and analyze data efficiently.
- Data Input and Output: Pandas can read and write data in various formats, such as CSV, Excel, SQL databases, and more.
- Time Series Handling: Pandas offers tools for working with time series data, including date/time indexing and frequency conversion.
Pandas data structures
Pandas provides two main data structures: DataFrame and Series. These data structures are the building blocks for data manipulation and analysis in Pandas.
1. DataFrame:
- A DataFrame is a two-dimensional tabular data structure with labeled axes (rows and columns). It is similar to a spreadsheet or SQL table.
- Each column in a DataFrame represents a variable, and each row represents an observation or data point.
- DataFrame supports heterogeneous data types for its columns.
- You can create a DataFrame from various data sources, including dictionaries, lists, NumPy arrays, CSV files, Excel files, SQL databases, and more.
- DataFrame is highly efficient for manipulating, filtering, grouping, merging, and aggregating data.
- You can easily handle missing data, perform mathematical operations on columns, and apply functions to the data.
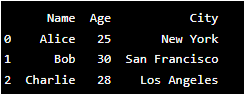
Example:
import pandas as pd
# Creating a DataFrame
data = {'Name': ['Alice', 'Bob', 'Charlie'],
'Age': [25, 30, 28],
'City': ['New York', 'San Francisco', 'Los Angeles']}
df = pd.DataFrame(data)
print(df)Output:
2. Series:
- A Series is a one-dimensional labeled array, a single column of data in a DataFrame.
- It is similar to a NumPy array but with additional features like labeled indices, making data alignment effortless.
- Series can hold data of any data type, including numeric, string, datetime, and more.
- Each element in a Series has an associated index, which allows for efficient data retrieval and alignment.
- Series represent time-series data, a single variable, or a column from a DataFrame.
- You can create a Series from lists, NumPy arrays, dictionaries, and more.
For example
import pandas as pd
# Creating a Series
ages = pd.Series([25, 30, 28], name='Age')
print(ages)Output:
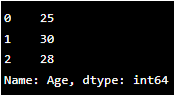
In the example above, we create a DataFrame named df with three columns: ‘Name’, ‘Age’, and ‘City’. We also create a series named Ages containing the ages of individuals. These data structures form Pandas’ foundation for data analysis and provide powerful tools for working with structured data.
Head to Head Comparison Between Pandas vs NumPy (Infographics)
Below are the top 7 differences between Pandas and NumPy:
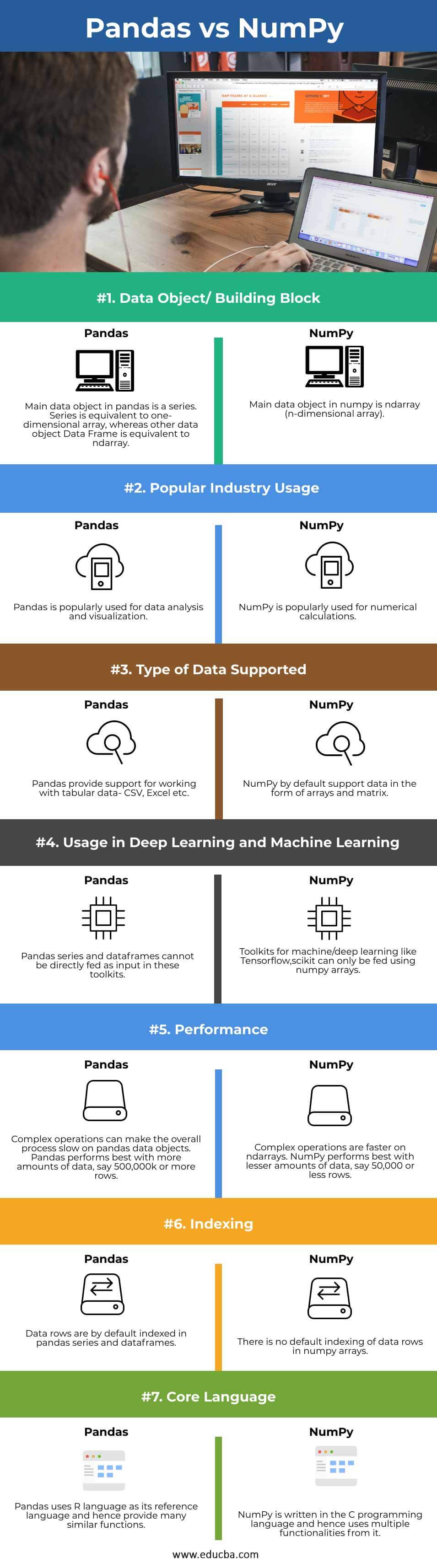
Key Difference Between Pandas vs NumPy
Let us discuss some of the major key differences between Pandas and NumPy:
- Data objects in NumPy and Pandas: The main data object in NumPy is an array, more particularly ndarray. It is basically an N-dimensional array that supports a wide variety of calculations and computations. These ndarrays are much faster than the Python list-based arrays as they do not involve any kind of looping. While the main data object in Pandas is a series. A series is basically a one-dimensional indexed array. By combining series objects, you can build another popular data object in pandas called DataFrames. DataFrames are n-dimensional indexed arrays. Very close to ndarrays in numpy but indexed.
- Type of data supported in NumPy and Pandas: NumPy library is mainly used for performing numerical computations and computations. We can perform complex calculations on arrays fastly and easily with a range of functions provided in this module. Whereas the pandas’ library is primarily used for data analysis, allowing us to work with CSV, Excel, SQL, etc. It even has some inbuilt functions for data plotting and visualization.
- Usage in deep learning and machine learning: NumPy is one of the basic modules on top of which most of the other Python modules are built. The most popular machine learning tool scikit learn’s modules can be fed (accept input as) with NumPy arrays only. The same is the case with complex deep learning tools such as TensorFlow. It also accepts NumPy arrays as input and gives arrays as output. Pandas data objects cannot be directly used as input for machine learning and deep learning tools. We have to run them through several steps of preprocessing before feeding them to a machine-learning module.
- Performance with complex operations: NumPy performs best when it comes to complex mathematical calculations on multidimensional arrays. It is insanely faster than pandas when it comes to calculations such as solving linear algebra, finding gradient descent, matrix multiplications, and vectorization of data, etc. It is really tedious and tough to perform these calculations on data frames and series objects in pandas. However, one should note that NumPy performs best with 50,000 or less number of rows in the dataset, while pandas perform best with 500,000 rows or more when it comes to data manipulation.
- Indexing in Pandas and NumPy: The data rows are not indexed by default in NumPy arrays. However, this is not the case with pandas. The data rows are indexed or labelled by default. You can play with the indexes and manipulate it. You can use a column as the index or change the name of labels etc. in the indexes. This is quite not possible in NumPy.
Pandas vs NumPy Comparison Table
Let’s discuss the top comparison between Pandas vs NumPy:
| Point of Comparison | Pandas | NumPy |
| Data Object/ Building Block | The main data object in pandas is a series. Series is equivalent to the one-dimensional array, whereas other data object Data Frame is equivalent to ndarray. | The main data object in numpy is ndarray (n-dimensional array). |
| Popular Industry Usage | Pandas are popularly used for data analysis and visualization. | NumPy is popularly used for numerical calculations. |
| Type of Data Supported | Pandas provide support for working with tabular data- CSV, Excel etc. | NumPy by default support data in the form of arrays and matrix. |
| Usage in Deep Learning and Machine Learning | Pandas series and dataframes cannot be directly fed as input in these toolkits. | Toolkits for machine/deep learning like Tensorflow,scikit can only be fed using NumPy arrays. |
| Performance | Complex operations can make the overall process slow on pandas’ data objects. Pandas perform best with more amounts of data, say 500,000k or more rows. | Complex operations are faster on ndarrays. NumPy performs best with lesser amounts of data, say 50,000 or less rows. |
| Indexing | Data rows are by default indexed in pandas series and dataframes. | There is no default indexing of data rows in NumPy arrays. |
| Core Language | Pandas uses R language as its reference language and hence provides many similar functions. | NumPy is written in the C programming language and hence uses multiple functionalities from it. |
Conclusion
Python users rely on two essential libraries for data manipulation, analysis, and computation – NumPy and Pandas. NumPy efficiently handles array operations and mathematical functions, while Pandas provides versatile data structures such as DataFrames for intuitive data handling and transformation. These libraries have become foundational tools for data scientists and analysts, streamlining workflows and facilitating insightful insights from diverse datasets.
Frequently Asked Questions (FAQs)
1. Can I use NumPy and Pandas for machine-learning tasks?
Answer: Absolutely, both libraries are extensively used in machine learning pipelines for data preprocessing, feature engineering, and data exploration.
2. Can I install NumPy and Pandas on my system?
Answer: Yes, you can install both libraries using Python’s package manager, pip, with commands like pip install numpy and pip install pandas.
3. How do I create a NumPy array?
Answer: You can create a NumPy array from existing Python lists or use functions like np.zeros(), np.ones(), and np.arange().
4. How can I handle missing data in Pandas?
Answer: Pandas provide methods like dropna(), fillna(), and interpolation techniques to handle missing values effectively.
5. What kinds of operations can I perform on DataFrames with Pandas?
Answer: For comprehensive data analysis, you can perform operations such as indexing, slicing, filtering, grouping, aggregation, merging, and pivoting.
6. Can I visualize data using NumPy and Pandas?
Answer: While NumPy and Pandas focus on data manipulation, Data visualization can be achieved through the use of libraries such as Matplotlib and Seaborn.
7. Is knowledge of Python required to use NumPy and Pandas?
Answer: A basic understanding of Python is beneficial for effectively utilizing NumPy and Pandas for data analysis tasks.
Recommended Articles
This is a guide to Pandas vs NumPy. Here we discuss the Pandas and NumPy key differences with infographics and comparison table. You may also have a look at the following articles to learn more –
