Updated April 20, 2023

Introduction to Pandas cut()
Pandas cut() function is utilized to isolate exhibit components into independent receptacles. The cut() function works just on one-dimensional array like articles. The cut() function in Pandas is useful when there are large amounts of data which has to be organized in a statistical format.
For example, let us say we have numbers from 1 to 10. Here, we categorize these values and differentiate them as 2 groups. These groups are termed as bins. Hence, we differentiate these set of values are bin 1 = 1 to 5 and bin 2 = 5 to 10. Now, once we have these two bins, we decide which values are greater and which are smaller. So, the numbers from 1 to 5 are smaller than the numbers from 5 to 10. Hence, these smaller numbers are termed as ‘Lows’ and the greater numbers are termed as ‘Highs’.
This method is called labelling the values using Pandas cut() function. Use cut once you have to be compelled to section and type information values into bins. This operate is additionally helpful for going from an eternal variable to a categorical variable. As an example, cut may convert ages to teams getting on supports binning into associate degree equal variety of bins, or a pre-specified array of bins.
Syntax of Pandas cut()
Given below is the syntax of Pandas cut():
Pandas.cut(x, duplicates='raise', include_lowest = false, precision = 3, retbins = false, labels = none, right = true, bins)Parameters of above syntax:
- ‘x’ represents any one dimensional array which has to be put into bin.
- duplicates represents the edges in the bin which are not unique values and thus returns a value error if not assigned as raise or drop.
- include_lowest represents the values which have to be included as lowest values.
- precision parameter is always represented as an integer values as it is the exact value which has to be displayed and stored by the bin numbers.
- retbins are always represented as Boolean values and these are the parameters which help the user to choose which are the useful bins.
- labels just helps to represent and categorize the bins as highs or lows. They can be Boolean or arrays.
- right parameter checks if the bin is present in the rightmost edge or not and they are represented as Boolean values and assigned to either true or false.
- bins just help to categorize the data and if it is an integer then the range for all values is defined as ‘a’ and this ‘a’ describes the minimum and maximum values. If the bin values are a series of scalar arrays then, the bins are not formed in a sequential format and finally the interval index defines whether the bins are overlapping or falling on one another or they are produced in a proper format in the output.
How cut() Function works in Pandas?
Given below shows how cut() function works in Pandas:
Example #1
Utilizing Pandas Cut() function to segment the numbers into bins.
Code:
import numpy as np
import pandas as pd
df_num1 = pd.DataFrame({'num': np.random.randint(1, 30, 20)})
print(df_num1)
df_num1['num_bins'] = pd.cut(x=df_num1['num'], bins=[1, 5, 10, 15, 30])
print(df_num1)
print(df_num1['num_bins'].unique())Output:
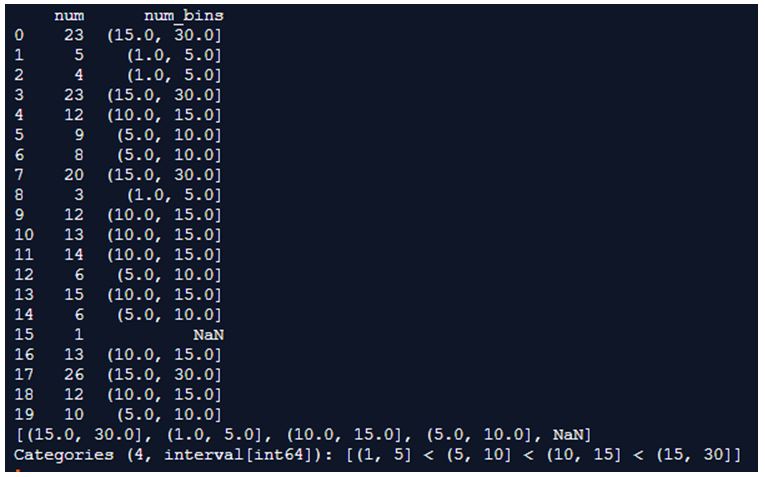
In the above program, we see how to categorize the values into different bins. First we import numpy and pandas and then define the different integer values and finally add pandas.cut() function to categorize these values as bins and finally print them as a separate column and also print the unique values in the bins and thus the output is generated.
Example #2
Utilizing Pandas cut() function to label the bins.
Code:
import numpy as np
import pandas as pd
df_num1 = pd.DataFrame({'number': np.random.randint(1, 50, 30)})
print(df_num1)
df_num1['numbers_labels'] = pd.cut(x=df_num1['number'], bins=[1, 25, 50], labels=['Lows', 'Highs'], right=False)
print(df_num1)
print(df_num1['numbers_labels'].unique())Output:
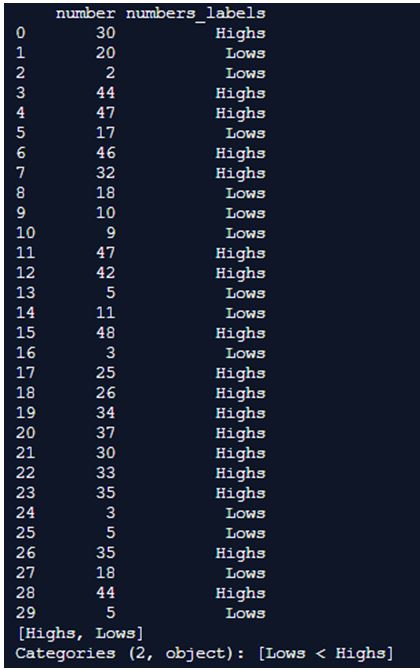
Here, we do the same as previous but along with categorizing into bins, we also categorize these bins ad label them as highs and lows. We first import pandas and numpy packages in python. We later assign the values for the bins and by making use of pandas.cut() function, we differentiate the numerical values into bins and finally see which numbers are greater and which are smaller. So, the greater numbers are termed as highs and the smaller numbers are termed as lows.
Conclusion
Use cut after you rephased the sorted values into bins. This operation is additionally helpful for going from endless variable to a categorical variable. For instance, cut might convert ages to teams old-time ranges. Supports binning into Associate in Nursing equal variety of bins, or a pre-specified array of bins. The specific bins are solely go back only when the parameter retbins = true. Hence, for sequence bins which consist of scalar arrays, this will end up as the last array of the present bin. So, when duplicates=drop, the bins drop out the array which are non-unique and hence ends up offering adequate number of bins.
Recommended Articles
We hope that this EDUCBA information on “Pandas cut()” was beneficial to you. You can view EDUCBA’s recommended articles for more information.

