Updated March 20, 2023
Introduction to Machine Learning Models
A machine learning model is the output of the training process and is defined as the mathematical representation of the real-world process. The machine learning algorithms find the patterns in the training dataset, which is used to approximate the target function and is responsible for mapping the inputs to the outputs from the available dataset. These machine learning methods depend upon the type of task and are classified as Classification models, Regression models, Clustering, Dimensionality Reductions, Principal Component Analysis, etc.
Types of Machine Learning Models
Based on the type of tasks, we can classify machine learning models into the following types:
- Classification Models
- Regression Models
- Clustering
- Dimensionality Reduction
- Deep Learning etc.
1) Classification
With respect to machine learning, classification is the task of predicting the type or class of an object within a finite number of options. The output variable for classification is always a categorical variable. For example, predicting an email is spam or not is a standard binary classification task. Now let’s note down some important models for classification problems.
- K-Nearest neighbors algorithm – simple but computationally exhaustive.
- Naive Bayes – Based on Bayes theorem.
- Logistic Regression – Linear model for binary classification.
- SVM – can be used for binary/multiclass classifications.
- Decision Tree – ‘If Else’ based classifier, more robust to outliers.
- Ensembles – Combination of multiple machine learning models clubbed together to get better results.
2) Regression
In the machine, learning regression is a set of problems where the output variable can take continuous values. For example, predicting the airline price can be considered as a standard regression task. Let’s note down some important regression models used in practice.
- Linear Regression – Simplest baseline model for regression task, works well only when data is linearly separable and very less or no multicollinearity is present.
- Lasso Regression – Linear regression with L2 regularization.
- Ridge Regression – Linear regression with L1 regularization.
- SVM regression
- Decision Tree Regression etc.
3) Clustering
In simple words, clustering is the task of grouping similar objects together. It helps to identify similar objects automatically without manual intervention. We can not build effective supervised machine learning models (models that need to be trained with manually curated or labeled data) without homogeneous data. Clustering helps us achieve this in a smarter way. Following are some of the widely used clustering models:
- K means – Simple but suffers from high variance.
- K means++ – Modified version of K means.
- K medoids.
- Agglomerative clustering – A hierarchical clustering model.
- DBSCAN – Density-based clustering algorithm etc.
4) Dimensionality Reduction
Dimensionality is the number of predictor variables used to predict the independent variable or target.often, in real-world datasets, the number of variables is too high. Too many variables also bring the curse of overfitting to the models. In practice, among these large numbers of variables, not all variables contribute equally towards the goal, and in a large number of cases, we can actually preserve variances with a lesser number of variables. Let’s list out some commonly used models for dimensionality reduction.
- PCA – It creates lesser numbers of new variables out of a large number of predictors. The new variables are independent of each other but less interpretable.
- TSNE – Provides lower dimensional embedding of higher-dimensional data points.
- SVD – Singular value decomposition is used to decompose the matrix into smaller parts to efficiently calculate.
5) Deep Learning
Deep learning is a subset of machine learning which deals with neural networks. Based on the architecture of neural networks, let’s list down important deep learning models:
- Multi-Layer perceptron
- Convolution Neural Networks
- Recurrent Neural Networks
- Boltzmann machine
- Autoencoders etc.
Which Model is the Best?
Above we took ideas about lots of machine learning models. Now an obvious question comes to our mind ‘Which is the best model among them?’ It depends on the problem at hand and other associated attributes like outliers, the volume of available data, quality of data, feature engineering, etc. In practice, it is always preferable to start with the simplest model applicable to the problem and increase the complexity gradually by proper parameter tuning and cross-validation. There is a proverb in the world of data science – ‘Cross-validation is more trustworthy than domain knowledge.
How to Build a Model?
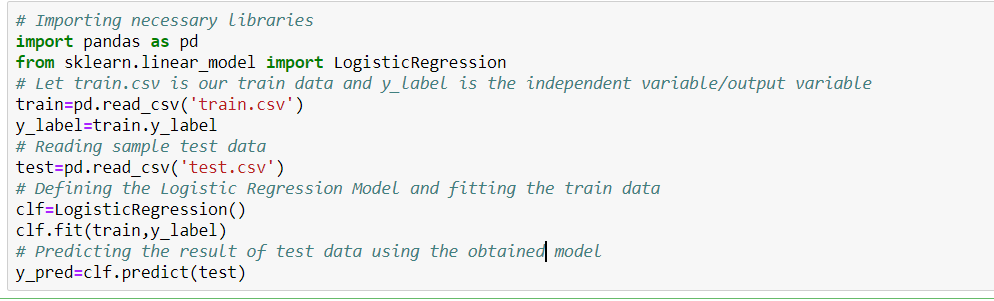
Let’s see how to build a simple logistic regression model using the Scikit Learn library of python. For simplicity, we are assuming the problem is a standard classification model, and ‘train.csv’ is the train, and ‘test.csv’ is the train and test data, respectively.
Conclusion
This article discussed the important machine learning models used for practical purposes and how to build a simple model in python. Choosing a proper model for a particular use case is very important to obtain the proper result of a machine learning task. To compare the performance between various models, evaluation metrics or KPIs are defined for particular business problems, and the best model is chosen for production after applying the statistical performance checking.
Recommended Articles
This is a guide to Machine Learning Models. Here we discuss the basic concept with the Top 5 Types of Machine Learning Models and how to built it in detail. You can also go through our other suggested articles to learn more –
