What is Information Retrieval?
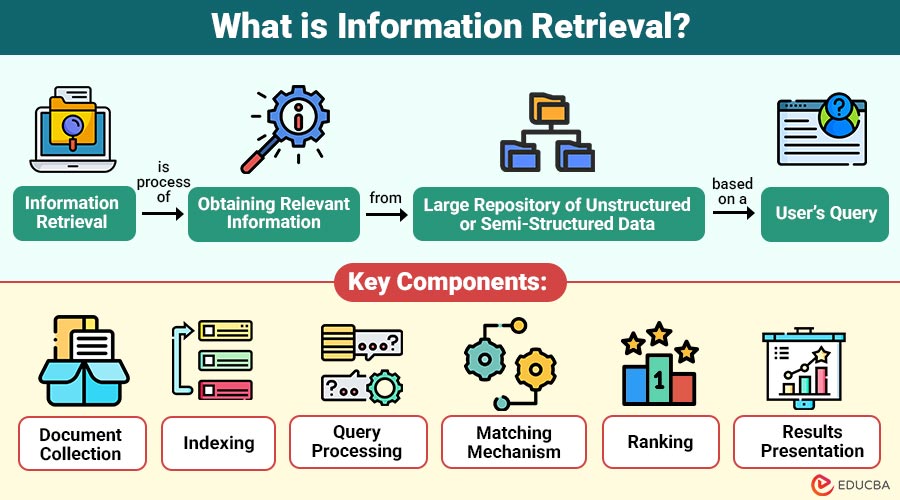
Information Retrieval (IR) is process of obtaining relevant information from a large repository of unstructured or semi-structured data based on a user’s query.
Unlike database systems, which retrieve exact matches from structured data, IR systems primarily handle unstructured content such as text documents, images, audio, and other media. The goal is not just to retrieve data but to retrieve the most relevant data.
Table of Contents:
- Meaning
- Key Components
- Process
- Models
- Techniques
- Real-World Examples
- Evaluation Metrics
- Advantages
- Limitations
- Modern Trends
Key Takeaways:
- Information retrieval efficiently finds relevant data from unstructured sources, prioritizing user queries for meaningful results.
- Core components include document collection, indexing, query processing, matching mechanisms, ranking, and effective results presentation.
- IR systems use boolean, vector space, probabilistic, and language models to rank document relevance accurately.
- Modern IR leverages AI, semantic search, personalization, and neural networks for improved accuracy and user satisfaction.
Key Components of Information Retrieval Systems
An effective IR system consists of the following core components:
1. Document Collection
A structured repository containing digital documents, web pages, articles, multimedia files, and records available for search and retrieval processes.
2. Indexing
The process of analyzing documents and storing key terms in structured indexes enables faster and more efficient information retrieval.
3. Query Processing
The system interprets, cleans, tokenizes, and transforms user queries into a format compatible with its indexing structure.
4. Matching Mechanism
The system compares processed queries with indexed documents using retrieval models to identify relevant and meaningful matches.
5. Ranking
Retrieved documents are assigned relevance scores and ordered systematically to present the most useful results first.
6. Results Presentation
Final search results are displayed clearly with titles, snippets, and links in an organized, user-friendly interface.
Information Retrieval Process
The IR process typically follows these steps:
Step 1: Document Acquisition
Documents are collected from websites, databases, repositories, and internal storage systems for further indexing and retrieval.
Step 2: Preprocessing
Text cleaning techniques are applied:
- Tokenization
- Stop-word removal
- Stemming
- Lemmatization
Step 3: Indexing
An inverted index structure maps important terms to documents, enabling faster and more efficient search operations.
Step 4: Query Input
The user submits a search query that expresses information needs using keywords or natural language.
Step 5: Query Processing
The query undergoes preprocessing steps similar to those of documents to ensure consistent comparison and matching.
Step 6: Matching and Ranking
The system compares processed queries with indexed documents and assigns relevance scores to rank the results appropriately.
Step 7: Display Results
Top-ranked documents are presented clearly with titles, snippets, and links for user evaluation and selection.
Models of Information Retrieval
Different models define how documents are matched with queries.
1. Boolean Model
Uses logical operators AND, OR, and NOT to match documents with queries, retrieving exact matches without ranking results.
2. Vector Space Model
Represents documents and queries as numerical vectors, using cosine similarity to calculate relevance and rank results accordingly.
3. Probabilistic Model
Estimates the probability that a document satisfies a user query, ranking results based on statistical relevance calculations like BM25.
4. Language Model
Applies probabilistic language modeling techniques to predict the likelihood that a document generates the given query terms.
Techniques Used in Information Retrieval
IR systems rely on several important techniques:
1. Term Frequency–Inverse Document Frequency (TF-IDF)
Calculates word importance by comparing its frequency in a document against its rarity across the entire collection.
2. Inverted Index
Data structure mapping terms to document locations, enabling fast keyword-based searching and efficient retrieval operations.
3. Page Ranking Algorithms
Algorithms rank web pages based on authority, relevance, and link structure, such as Google’s PageRank algorithm.
4. Natural Language Processing (NLP)
Enhances query understanding through linguistic analysis, enabling semantic search, context awareness, and improved retrieval accuracy.
5. Relevance Feedback
Refines search results by incorporating user feedback, improving ranking accuracy, and aligning outputs with user intent.
Applications of Information Retrieval
Information retrieval is widely used across industries:
1. Web Search Engines
Search engines like Google and Bing use IR techniques to retrieve relevant web pages for user queries instantly.
2. Digital Libraries
Academic databases and institutional repositories apply IR systems to locate scholarly articles, research papers, and publications.
3. E-Commerce Platforms
Platforms like Amazon use IR algorithms to recommend products based on user searches and browsing behavior.
4. Multimedia Retrieval
IR systems enable efficient retrieval of images, videos, and audio files from extensive multimedia datasets.
5. Enterprise Search
Organizations implement internal IR systems to quickly retrieve documents, reports, emails, and knowledge resources.
6. Healthcare Systems
Medical databases use IR techniques to access patient records, clinical reports, and relevant research studies.
7. Legal Research
Law firms rely on IR systems to efficiently search case histories, statutes, precedents, and legal documents.
Real-World Examples
Here are some practical examples showing how information retrieval works in everyday applications:
1. Web Search
When a user searches for “Best machine learning courses,” the search engine retrieves millions of web pages and ranks them by relevance.
2. Streaming Platforms
Platforms like Netflix retrieve movies and shows based on user preferences and search history.
3. Academic Research
Google Scholar retrieves scholarly articles based on research queries.
Evaluation Metrics in Information Retrieval
Performance of IR systems is measured using:
1. Precision
The percentage of papers that are truly pertinent to the user’s information requirement is measured by precision.
2. Recall
The percentage of all pertinent documents that the system successfully retrieves in response to a query is known as recall.
3. F-Measure
The F-measure calculates the harmonic mean of precision and recall, balancing both metrics into a single performance value.
4. Mean Average Precision
Mean Average Precision evaluates ranking quality by systematically averaging precision scores across multiple queries.
5. Normalized Discounted Cumulative Gain
Normalized Discounted Cumulative Gain measures ranking effectiveness by considering relevance scores and document positions in results.
Advantages of Information Retrieval
Here are the advantages of using information retrieval systems in various applications:
1. Efficient Handling of Large Data Volumes
IR systems efficiently process and manage massive amounts of data, enabling quick access to and retrieval of relevant information from extensive collections.
2. Faster Search Performance
By using indexing and optimized retrieval algorithms, IR systems provide rapid query responses, significantly reducing search time for users.
3. Ranked Results for Better Usability
IR systems rank retrieved documents by relevance, helping users quickly find the most useful information without manually filtering large results.
4. Supports Unstructured Data
Information retrieval can handle unstructured text, multimedia, and diverse content formats, making it versatile across different data types and applications.
5. Enhances Decision-Making
By providing accurate, relevant, and timely information, IR systems support informed decision-making in business, healthcare, research, and other domains.
Limitations of Information Retrieval
While powerful, IR systems also face certain challenges that can affect accuracy and user satisfaction:
1. May Retrieve Irrelevant Results
IR systems can return documents that do not meet user needs, leading to lower accuracy and potential user frustration.
2. Ranking May Not Always Reflect User Intent
Even highly ranked documents may not satisfy specific user requirements, as relevance scoring cannot perfectly capture intent or context.
3. Performance Depends on Indexing Quality
The effectiveness of an IR system relies heavily on accurate, comprehensive indexing; poor indexes reduce retrieval speed and accuracy.
4. Handling Ambiguous Queries Can Be Challenging
Queries with unclear or multiple meanings can confuse IR systems, leading to irrelevant or suboptimal retrieval results for users.
Modern Trends in Information Retrieval
Emerging technologies and techniques are transforming how information retrieval systems deliver accurate and relevant results:
1. Semantic Search
Semantic search improves retrieval by understanding query context, intent, and meaning, going beyond simple keyword matching to deliver more accurate results.
2. AI-Powered Search
Artificial intelligence and machine learning models enhance search accuracy, relevance, and ranking by learning patterns from user queries and documents.
3. Voice Search
Voice-activated search allows users to retrieve information through speech, leveraging speech recognition and natural language understanding technologies.
4. Personalized Search
Personalized search tailors results according to individual user behavior, preferences, and history, improving relevance and user satisfaction.
5. Neural Information Retrieval
Neural IR applies deep learning models to capture semantic relationships and contextual meaning for more precise document matching.
Final Thoughts
Information Retrieval (IR) powers modern digital experiences, enabling fast, efficient access to relevant information across web searches, research, streaming, and enterprise systems. As data grows exponentially, advanced techniques integrating artificial intelligence, machine learning, and semantic analysis enhance search accuracy and relevance. IR transforms vast data repositories into meaningful, accessible knowledge, supporting smarter decisions and improved user experiences.
Frequently Asked Questions (FAQs)
Q1. What are the main models of IR?
Answer: Boolean, Vector Space, Probabilistic, and Language models.
Q2. Where is information retrieval used?
Answer: Search engines, e-commerce platforms, digital libraries, enterprise systems, and multimedia platforms.
Q3. What is TF-IDF?
Answer: A statistical measure used to evaluate the importance of word in a document relative to a collection.
Recommended Articles
We hope that this EDUCBA information on “Information Retrieval” was beneficial to you. You can view EDUCBA’s recommended articles for more information.

