Updated February 28, 2023
Introduction to DNN Neural Network
Artificial Neural Network(ANN) can either be shallow or deep. When ANN has more than one hidden layer in its architecture, they are called Deep Neural Networks. These networks process complex data with the help of mathematical modelling. Deep Neural Networks (DNN) is otherwise known as Feed Forward Neural Networks(FFNNS).In this networks, data will be flowing in the forward direction and not in the backward direction, and hence node can never be accessed again. These Networks need a huge amount of data to train, and they have the ability to classify millions of data.
Structure of DNN Neural Network
Deep Neural Networks have an input layer, an output layer and few hidden layers between them. These networks not only have the ability to handle unstructured data, unlabeled data, but also non-linearity as well. They have a hierarchical organization of neurons similar to the human brain. The neurons pass the signal to other neurons based on the input received. If the signal value is greater than the threshold value, the output will be passed else ignored. As you can see the data is passed to the input layer and they yield output to the next layer and so on until it reaches the output layer where it provides the prediction yes or no based on probability. A layer consists of many neurons, and each neuron has a function called Activation Function. They form a gateway of passing the signal to the next connected neuron. The weight has the influence of the input to the output of the next neuron and finally, the last output layer. The weights initially assigned are random, but as the network gets trained iteratively, the weights are optimized to make sure that the network makes a correct prediction.
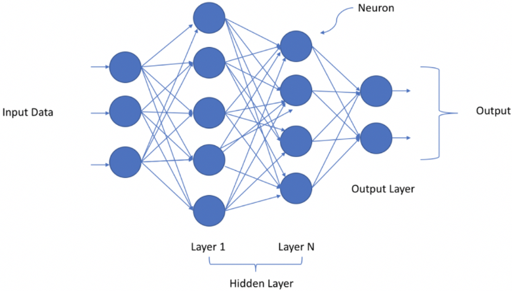
For better understanding, let’s take the human brain which can identify different people though they have two eyes, one nose two ears. These variations and deviations can be learned by the neurons in the brain and combine all these differences and can identify the people. These all are done in the fraction of second.
The same logic is applied to Deep Neural Network by using a mathematical approach. Based on the simple rule, the signal from one neuron is transferred to another neuron, similar to the process learned by the brain. When the output of the neuron has a high value, then, the dimension corresponding to that has high importance. Similarly, all the importance of one layer been captured in the form of deviation and finally combine all the deviations and fed it to the next layer. Thus the system learns the process intuitively.
Learning of DNN Neural Network
We provide input data to the network and based on that the output prediction would be correct or incorrect with the steps of numerous matrix multiplication. Based on the output, the feedback is fed back to the network, the system learns by adjusting its weights between the layers. This process is called Backpropagation by providing feedback and updating the weights. This process of training the network is computationally very high, and because of data involved, it is now it’s been more popular because of the improvisation of technologies recently.
Examples of DNN Neural Network
Below are mentioned the examples:
1. MNIST Data
These networks can be further explained by three concepts like Local receptive fields, shared weights, and pooling Say we are using 28*28 square of neurons whose values are intensities. So let’s say we connect the one neuron of hidden layer to the input layer of 5 * 5 region as shown in the fig below
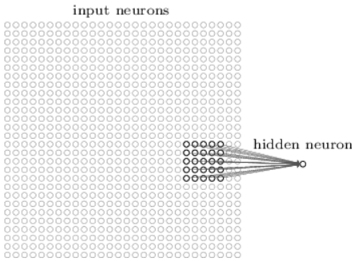
2. Local Receptive Fields
In the above diagram, the small region is called Local receptive fields. Each connection has a weight and is associated with the hidden layer neuron through the layer trains and learns. This has 28 * 28 input image, 5 * 5 local receptive fields then it will 24 * 24 neurons in the hidden layer.
![]()
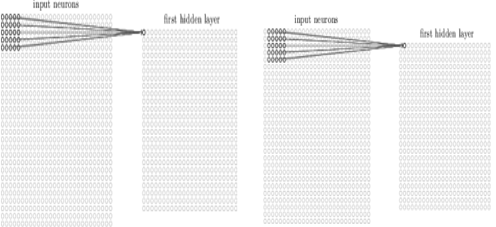
Here in the above diagram, the stride length is 1 when the local 5 * 5 is moved to the nearby region. When we move the local receptive region to the right by 2 pixels, then we say the stride is 2. Strides can be of different lengths and can be considered as one of the hyperparameters.
3. Sharing Weights
Each neuron in the hidden layer has a 5 * 5 weights and a bias for its local receptive region. This bias b is the same for all the hidden layer neurons. Here w(l,m) is shared weights, and an (x,y) is the activation function at that point. This implies that the neurons will learn a similar feature. Here the map from the input layer to the hidden layer is called a feature map. The weights are called shared weights; bias here is called shared bias. Weights and bias are called filters or kernels.
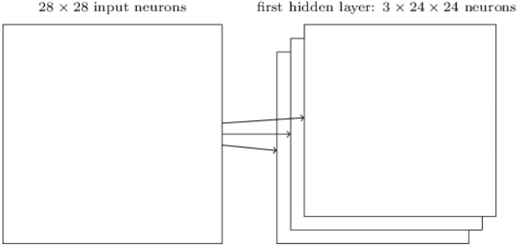
The local receptive field corresponds to one single kind of feature map. Likewise, we need a lot number of feature maps for prediction of images, The example shown above has three feature maps and each has a single bias and 5 *5 shared weights. This sample concept is used in LeNet and is used in MNIST classification of digits with more than 30 features maps. When sharing weights is used, the number of parameters is less for the network to learn.
4. Pooling Layer
These layers come after the convolution layer they normally compress the output produced from feature maps and in other words the reduced information comes out after the pooling layer. You can also specify the region size for max-pooling say for example if you have 2 * 2 region if you use max-pooling you get the max output activation in that 2 * 2 region.
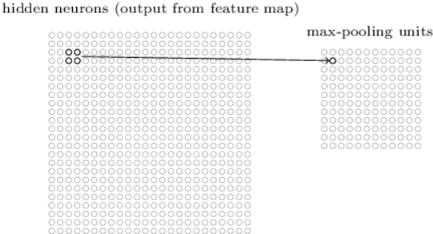
Likewise, for each feature map, you get max layer output. Another form of pooling is called L2 pooling. Here we take the square root of the sum of activations in that 2 * 2 region rather than taking the max of the activations.
Conclusion
Hence Deep Learning Network is used in may vertical of the industry right from Health-care in detecting cancer, Aviation industry for optimization, Banking Industry for detecting fraudulent transactions to retail for customer retention. All these are possible with the advent of GPUS for complex processing of data.
Recommended Articles
This is a guide to DNN Neural Network. Here we discuss an introduction, structures with deep learning and examples to implement with proper explanation. You can also go through our other related articles to learn more –

