Updated March 23, 2023

Introduction to DFS Algorithm
DFS is known as the Depth First Search Algorithm which provides the steps to traverse each and every node of a graph without repeating any node. This algorithm is the same as Depth First Traversal for a tree but differs in maintaining a Boolean to check if the node has already been visited or not. This is important for graph traversal as cycles also exist in the graph. A stack is maintained in this algorithm to store the suspended nodes while traversal. It is named so because we first travel to the depth of each adjacent node and then continue traversing another adjacent node.
Explain the DFS Algorithm
This algorithm is contrary to the BFS algorithm where all the adjacent nodes are visited followed by neighbors to the adjacent nodes. It starts exploring the graph from one node and explores its depth before backtracking. Two things are considered in this algorithm:
- Visiting a Vertex: Selection of a vertex or node of the graph to traverse.
- Exploration of a Vertex: Traversing all the nodes adjacent to that vertex.
Pseudo Code for Depth First Search:
proc DFS_implement(G,v):
let St be a stack
St.push(v)
while St has elements
v = St.pop()
if v is not labeled as visited:
label v as visited
for all edge v to w in G.adjacentEdges(v) do
St.push(w)
Linear Traversal also exists for DFS that can be implemented in 3 ways:
- Preorder
- Inorder
- PostOrder
Reverse postorder is a very useful way to traverse and used in topological sorting as well as various analyses. A stack is also maintained to store the nodes whose exploration is still pending.
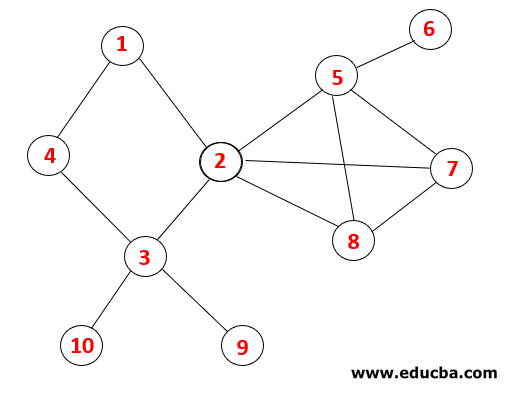
Graph Traverse in DFS
In DFS, the below steps are followed to traverse the graph. For example, a given graph, let us start traversal from 1:
| Stack | Traversal Sequence | Spanning Tree |
| 1 |  |
|
 |
1,4 | 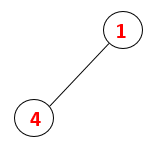 |
 |
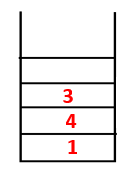
1,4,3 | 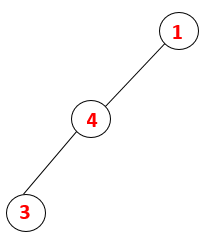 |
 |
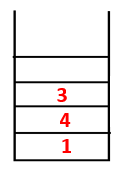
1,4,3,10 | 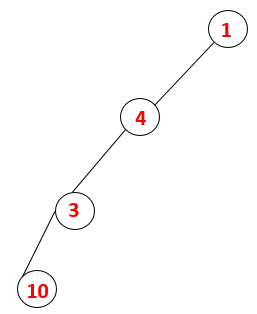 |
 |
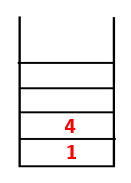
1,4,3,10,9 | 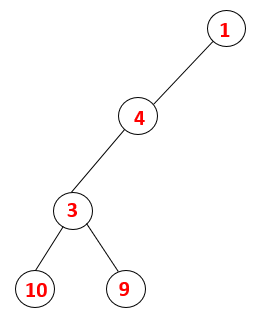 |
 |
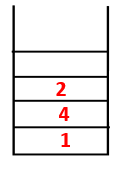
1,4,3,10,9,2 | 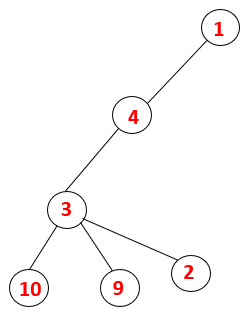 |
 |
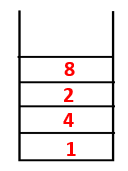
1,4,3,10,9,2,8 | 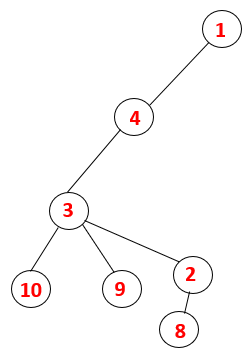 |
 |
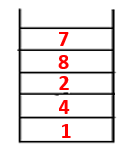
1,4,3,10,9,2,8,7 | 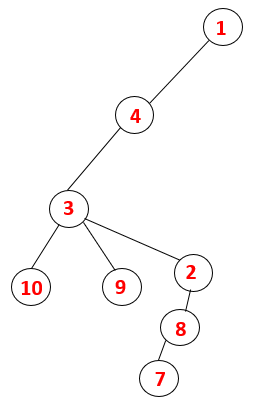 |
 |
1,4,3,10,9,2,8,7,5 | 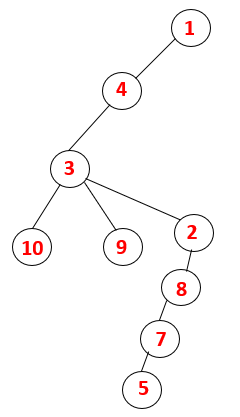 |
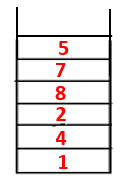 |
1,4,3,10,9,2,8,7,5,6 | 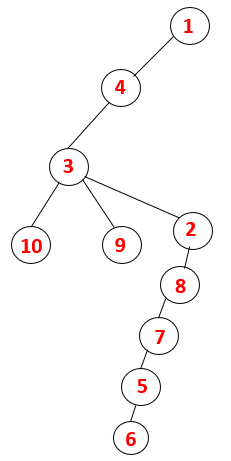 |
 |
1,4,3,10,9,2,8,7,5,6 | 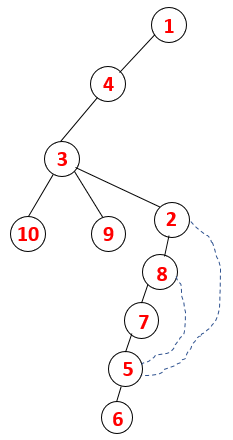 |
 |
1,4,3,10,9,2,8,7,5,6 | 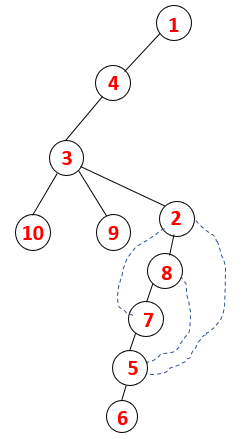 |
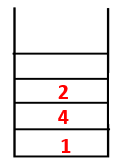 |
1,4,3,10,9,2,8,7,5,6 | 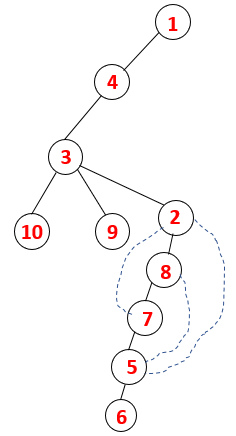 |
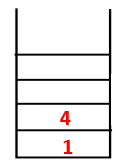 |
1,4,3,10,9,2,8,7,5,6 | 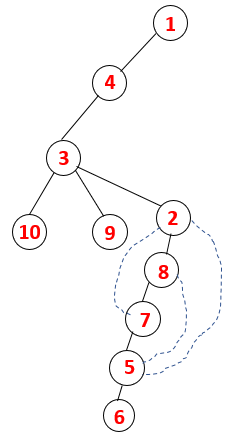 |
 |
1,4,3,10,9,2,8,7,5,6 | 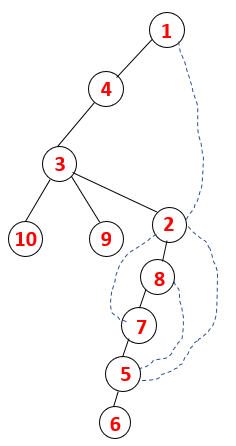 |
 |
1,4,3,10,9,2,8,7,5,6 | 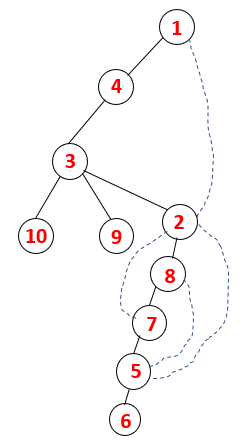 |
Explanation to DFS Algorithm
Below are the steps to DFS Algorithm with advantages and disadvantages:
Step1: Node 1 is visited and added to the sequence as well as the spanning tree.
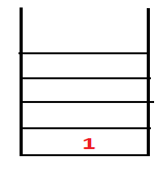
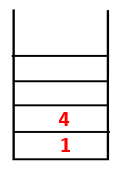
Step2: Adjacent nodes of 1 are explored that is 4 thus 1 is pushed to stack and 4 is pushed into the sequence as well as spanning tree.
Step3: One of the adjacent nodes of 4 is explored and thus 4 is pushed to the stack, and 3 enters the sequence and spanning tree.
Step4: Adjacent nodes of 3 are explored by pushing it onto the stack and 10 enters the sequence. As there is no adjacent node to 10, thus 3 is popped out of the stack.
Step5: Another adjacent node of 3 is explored and 3 is pushed onto the stack and 9 is visited. No adjacent node of 9 thus 3 is popped out and the last adjacent node of 3 i.e 2 is visited.
A similar process is followed for all the nodes till the stack becomes empty which indicates the stop condition for the traversal algorithm. — -> dotted lines in the spanning tree refers to the back edges present in the graph.
In this way, all the nodes in the graph are traverse without repeating any of the nodes.
Advantages and Disadvantages
- Advantages: The memory requirements for this algorithm is very less. Lesser space and time complexity than BFS.
- Disadvantages: Solution is not guaranteed Applications. Topological Sorting. Finding Bridges of the graph.
Example to Implement DFS Algorithm
Below is the example to implement DFS Algorithm:
Code:
import java.util.Stack;
public class DepthFirstSearch {
static void depthFirstSearch(int[][] matrix, int source){
boolean[] visited = new boolean [matrix.length];
visited[source-1] = true;
Stack<Integer> stack = new Stack<>();
stack.push(source);
int i,x;
System.out.println("Depth of first order is");
System.out.println(source);
while(!stack.isEmpty()){
x= stack.pop();
for(i=0;i<matrix.length;i++){
if(matrix[x-1][i] == 1 && visited[i] == false){
stack.push(x);
visited[i]=true;
System.out.println(i+1);
x=i+1;
i=-1;
}
}
}
}
public static void main(String[] args){
int vertices=5;
int[][] mymatrix = new int[vertices][vertices];
for(int i=0;i<vertices;i++){
for(int j=0;j<vertices;j++){
mymatrix[i][j]= i+j;
}
}
depthFirstSearch(mymatrix,5);
}
}
Output:
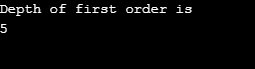
Explanation of the above program: We made a graph having 5 vertices (0,1,2,3,4) and used a visited array to keep track of all visited vertices. Then for each node whose adjacent nodes exist same algorithm repeats till all the nodes are visited. Then the algorithm goes back to calling vertex and pop it from the stack.
Conclusion
The memory requirement of this graph is less as compared to BFS as only one stack is needed to be maintained. A DFS spanning tree and traversal sequence is generated as a result but is not constant. Multiple traversal sequence is possible depending on the starting vertex and exploration vertex chosen.
Recommended Articles
This is a guide to DFS Algorithm. Here we discuss step by step explanation, traverse the graph in a table format with advantages and disadvantages. You can also go through our other related articles to learn more –

