Updated April 1, 2023
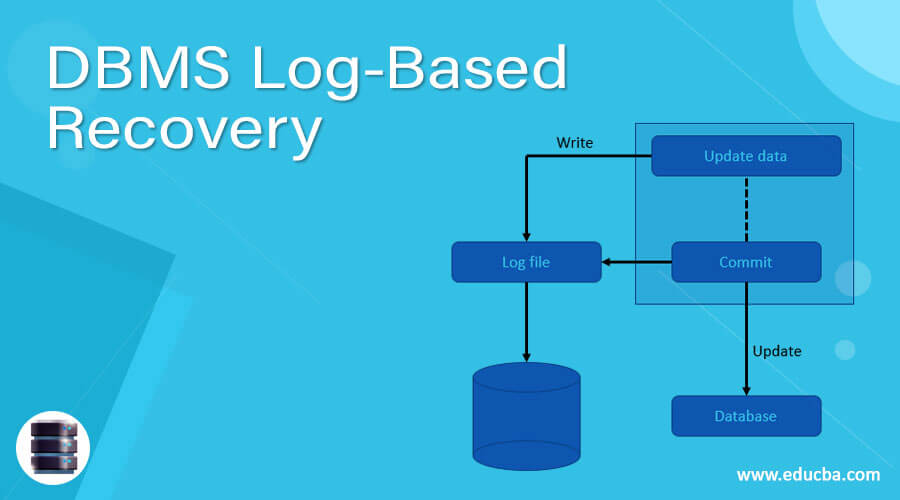
Definition of DBMS Log-Based Recovery
Log-based recovery provides the facility to maintain or recover data if any failure may occur in the system. Log means sequence of records or data, each transaction DBMS creates a log in some stable storage device so that we easily recover data if any failure may occur. When we perform any operation on the database at that time it will be recorded into a log file. Processing of the log file should be done before the original transaction is applied to the database. Why we use log-based recovery the main reason is that the Atomicity property of transaction states that we can either execute the whole transaction or nothing else, modification of the aborted transaction is not visible to the database, and modification of the transaction is visible so that reason we use log-based recovery system.
Syntax:
<TRX, Start>Explanation:
In the above syntax, we use TRX and start in which TRX means transaction and when a transaction in the initial state that means we write start a log.
<TRX, Name, 'First Name', 'Last Name' >Explanation:
In this syntax where TRX means transaction and name is used to First Name and Last Name. When we modify the name First Name to the Last Name then it writes a separate log file for that.
<TRX, Commits>Explanation:
In the above syntax, we use two-variable
transactions as TRX and commits, when transaction execution is finished then it is written into another log file that means the end of the transaction we called commits.
How to perform Log-Based Recovery in DBMS?
Log-based recovery uses the following term for execution as follows.
- Transaction Identifier: It used to uniquely identify the transaction.
- Data item Identifier: It is used to uniquely identify the used data in the database.
- Old Value: It is the value of data before the write operation of a transaction.
- New Value: It is the value of data after the write operation of a transaction.
Let’s see the transaction with various log types.
First, we start the transaction by using <TRX, Start> this syntax after that we perform the write operation of the transaction that means we update the database. After the write operation, we check whether the transaction is committed or aborted.
For recovery purposes, we use the following two operations as follows.
- Undo (TRX): This command is used to restore all records updated by transactions to the old value.
- Redo (TRX): This command is used to set the value of all records updated by a transaction to the new value.
Transaction Modification Techniques
There are two different types we use in database medication and that are helpful in the recovery system as follows. Transaction Modification Techniques as follows:
1. Immediate Database Modification
In this type, we can modify the database while the transaction is an inactive state. Data modification done by an active transaction is called an uncommitted transaction. When a transaction is failed or we can say that a system crash at that time, the transaction uses the old transaction to bring the database into a consistent state. This execution can be completed by using the undo operation.
Example:
<TRX1 start>
<TRX1 X, 2000, 1000>
<TRX1 Y, 3000, 1050>
<TRX1 commit>
<TRX2 start>
<TRX2 Z, 800, 500>
<TRX2 commit>Explanation:
In the above example we consider the banking system, the transaction TRX1 is followed by TRX2. If a system crash or a transaction fails in this situation means during recovery we do redo transaction TRX1 and undo the transaction TRX2 because we have both TRX start and commit state in the log records. But we don’t have a start and commit state for transaction TRX2 in log records. So undo transaction TRX2 done first the redo transaction TRX1 should be done.
2. Deferred Modification Technique
In this technique, it records all database operations of transactions into the log file. In this technique, we can apply all write operations of transactions on the database if the transaction is partially committed. When a transaction is partially committed at that time information in the log file is used to execute deferred writes. If the transaction fails to execute or the system crashes or the transaction ignores information from the log file. In this situation, the database uses log information to execute the transaction. After failure, the recovery system determines which transaction needs to be redone.
Example
(X) (Y)
<TRX1 start> <TRX1 start>
<TRX1 X, 850><TRX1 X , 850>
<TRX1 Y, 105><TRX1 Y, 1050>
<TRX1 commit>
<TRX2 start>
<TRX 2 Z, 500>Explanation:
If the system fails after write Y of transaction TRX1 then there is no need to redo operation because we have only <TRX1 start> in log record but don’t have <TRX1 commit>. In the second transaction Y, we can do the redo operation because we have <TRX1 start> and <TRX1 commit> in log disk but at the same time, we have <TRX2 start> but don’t have <TRX2 commit> as shown in the above transaction.
(Z)
<TRX1 start>
<TRX1 X , 850>
<TRX1 Y, 1050>
<TRX1 commit>
<TRX2 start>
<TRX2 Z, 500>
<TRX2 commit>Explanation:
In the above transaction, we have <TRX start> and <TRX commit> in log disk so we can redo operation during the recovery system.
Suppose we need to restore records from binary logs and by default, server creates binary logs. At that time you must know the name and current location of the binary log file, so by using the following statement we can see the file name and location as follows.
show binary logs;Explanation:
In the above statement, we use the show command to see binary logs. Illustrate the final result of the above statement by using the following snapshot.
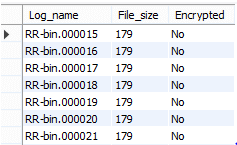
Example
show master status;Explanation:
Suppose we need to determine the current binary log file at that time we can use the above statement. Illustrate the final result of the above statement by using the following snapshot.
![]()
Conclusion
We hope from this article you have understood about the Log-based Recovery in DBMS. From the above article, we have learned the basic syntax Log-based Recovery. We have also learned how we can implement them in SQL Server with different examples of Log-based Recovery. From this article, we have learned how we can handle Log-based Recovery in DBMS.
Recommended Articles
We hope that this EDUCBA information on “DBMS Log-Based Recovery” was beneficial to you. You can view EDUCBA’s recommended articles for more information.
