What is Data Sampling?
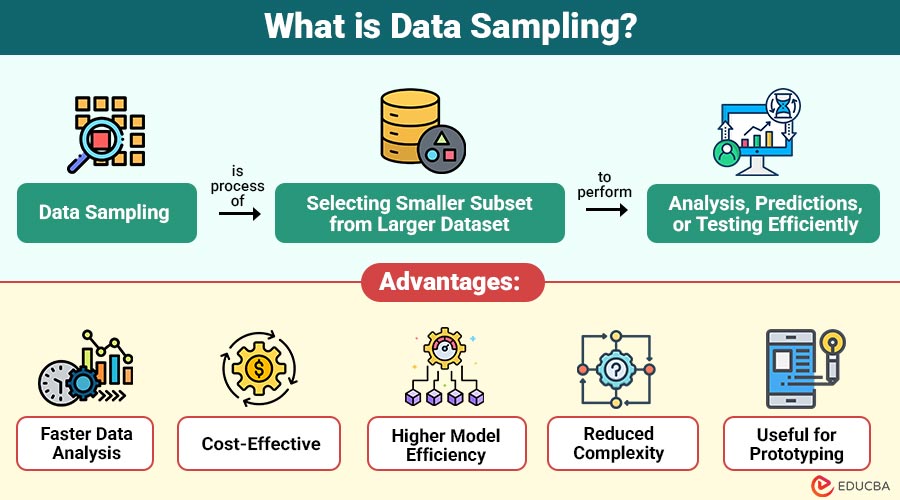
Data sampling is the process of selecting a smaller subset (sample) from a larger dataset (population) to perform analysis, predictions, or testing efficiently. The goal is to ensure the sample accurately represents the entire dataset, enabling reliable insights without analyzing every data point.
Table of Contents:
Key Takeaways:
- Data sampling enables faster, cost-effective analysis by working with smaller, representative subsets instead of complete datasets.
- Machine learning models train faster and more accurately when using well-chosen, balanced, and representative sampled datasets.
- Proper sampling reduces overfitting, ensures balanced representation, and helps avoid misleading insights caused by biased datasets.
- Sampling allows analysts to gain meaningful insights from large datasets without processing every single record, making data-driven decisions more practical and timely.
Why is Data Sampling Important?
Here are the key reasons why data sampling is crucial for efficient analysis and decision-making:
1. Faster Data Processing
Sampling reduces dataset size, enabling analyses to finish much more quickly than processing complete large datasets.
2. Lower Cost
Using smaller samples lowers storage, computation, and processing expenses compared to working with massive full datasets.
3. More Efficient Model Training
Models train faster and more efficiently on structured samples, especially during initial experiments or prototyping phases.
4. Helps Avoid Overfitting
Balanced samples improve model generalization, preventing algorithms from memorizing the training data and significantly reducing the risk of overfitting.
5. Useful for Real-Time Decision Making
Sampling enables rapid insights by providing quick, actionable information necessary for timely, real-time business decisions.
Types of Data Sampling
Data sampling methods are broadly categorized into Probability Sampling and Non-Probability Sampling.
| Sampling Type | Sub-Type | Description | Example |
|
Probability Sampling |
Simple Random Sampling | Every data point has an equal chance of being selected. | Randomly selecting 500 customers from 50,000 for a satisfaction study. |
| Systematic Sampling | Selection occurs at regular intervals. | Choosing every 10th record in a dataset. | |
| Stratified Sampling | The dataset is divided into groups (strata), and samples are taken from each group to maintain balance. | Ensuring equal representation of age groups in a health dataset. | |
| Cluster Sampling | Clusters are formed from the population, and whole clusters are chosen at random. | Selecting 5 cities from a country and analyzing all the people in those cities. | |
|
Non-Probability Sampling |
Convenience Sampling | Selecting data points that are easiest to access. | Surveying students in a nearby college because it is convenient. |
| Judgmental / Purposive Sampling | Samples are selected based on expert judgment. | Choosing only experienced traders for a financial behavior study. | |
| Quota Sampling | Ensures certain categories have a fixed number of samples. | 30 men and 30 women in a survey, regardless of population proportion. | |
| Snowball Sampling | Used when subjects are hard to find; existing subjects recruit new subjects. | Surveys involving rare disease patients. |
Advantages of Data Sampling
Here are the key advantages of using data sampling in analytics and machine learning:
1. Faster Data Analysis
Sampling reduces dataset size, enabling quicker processing, faster insights, and significantly improved overall analytical efficiency.
2. Cost-Effective
Smaller samples lower computation, storage, and processing expenses, making data analysis more affordable and resource-efficient.
3. Higher Model Efficiency
Machine learning models train faster and perform better when using balanced, clean, and well-selected sampled datasets.
4. Reduced Complexity
Sampling decreases data volume, simplifying statistical analysis, easing experimentation, and making hypothesis testing more manageable.
5. Useful for Prototyping
Sampling enables rapid experimentation, allowing quick testing of concepts before applying models to full, large datasets.
Disadvantages of Data Sampling
Here are the key disadvantages associated with using data sampling:
1. Sampling Bias
Poorly chosen samples distort population representation, causing inaccurate conclusions and unreliable analytical or predictive outcomes.
2. Loss of Information
Using smaller subsets can overlook important trends or subtle patterns present only in complete datasets.
3. Wrong Method Selection
Incorrect sampling techniques produce misleading insights, reducing analysis accuracy and weakening the reliability of data-driven decision-making.
4. Harder for Rare Events
Sampling may miss rare cases or outliers, especially in sensitive fields like fraud detection.
Real-World Examples
Here are practical, real-world examples of data sampling across different industries:
1. Market Research Surveys
Brands analyze small customer samples to understand preferences and behaviors without surveying their entire user base.
2. Quality Control in Manufacturing
Factories inspect selected product samples to detect defects efficiently, rather than examining every item manufactured daily.
3. Medical Research
Clinical trials rely on representative samples to evaluate drug safety and effectiveness before widespread population approval.
4. Website A/B Testing
Teams test features on random visitor samples to estimate performance improvements without impacting the entire audience.
Difference Between Data Sampling and Data Filtering
Here is a comparison table highlighting the differences between Data Sampling and Data Filtering:
| Feature | Data Sampling | Data Filtering |
| Purpose | Reduce dataset size | Remove unnecessary or irrelevant records |
| Basis | Statistical selection | Logical conditions or rules |
| Accuracy Impact | High if representative | Low if relevant data is removed |
| Use Cases | ML model training, surveys | Cleaning and preprocessing |
Use Cases of Data Sampling
Here are some practical use cases of data sampling across different industries:
1. Finance
Fraud detection systems use oversampling to ensure that minority fraud cases are adequately represented, thereby improving model accuracy.
2. Healthcare
Researchers sample patient records to analyze disease patterns, enabling efficient studies without processing every single record.
3. eCommerce
Data analysts sample customer behavior to enhance recommendation engines, improving personalized recommendations and boosting overall user engagement.
4. Telecom
Network load sampling helps predict peak usage times, supporting efficient resource allocation and avoiding system overloads.
5. Marketing
Marketing campaigns use sampling to estimate performance and customer response without analyzing the entire dataset.
Final Thoughts
Data sampling is a crucial statistical method that enables faster, cost-effective, and efficient analysis by using smaller, representative datasets. It supports fields such as machine learning, healthcare, finance, and market research by simplifying data handling without sacrificing accuracy. Selecting the right sampling method ensures reliable insights, improved model performance, reduced processing time, and overall better decision-making.
Frequently Asked Questions (FAQs)
Q1. What is an ideal sample size?
Answer: Depends on data variability, model complexity, and accuracy goals. Larger samples generally improve reliability.
Q2. What is sampling bias?
Answer: A distortion that occurs when the selected sample does not represent the total population.
Q3. Why is stratified sampling popular?
Answer: It ensures all groups (strata) in a dataset are represented proportionally, improving reliability.
Q4. Can sampling affect model accuracy?
Answer: Yes. If the sample is representative, accuracy remains high. Poor sampling can reduce accuracy by missing key patterns or rare events.
Recommended Articles
We hope that this EDUCBA information on “Data Sampling” was beneficial to you. You can view EDUCBA’s recommended articles for more information.

