What is Data Deduplication?
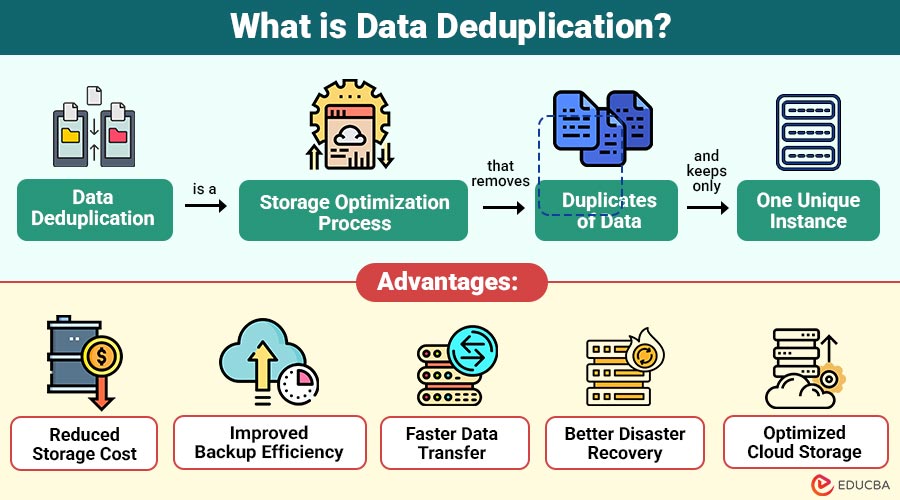
Data deduplication is a storage optimization process that removes duplicates of data and keeps only one unique instance. Instead of storing the same file or data block multiple times, the system stores a single copy and replaces duplicates with references to the original data.
For example, if the same file exists in multiple folders or backups, deduplication ensures that only one copy is stored, while the other copies point to the original. This reduces storage usage and improves efficiency.
Deduplication can occur at different levels, such as file level, block level, or byte level, depending on the system design. It can also be performed during data transfer, during storage, or after data is stored.
Table of Contents:
Key Takeaways:
- Data deduplication removes duplicate data blocks, significantly reducing storage usage and improving system efficiency.
- Different deduplication methods, such as file, block, and byte level, provide varying levels of storage optimization.
- Deduplication improves backup speed, reduces storage cost, and optimizes bandwidth usage in large data environments.
- Although powerful, deduplication requires extra processing power and works best with non-encrypted, repetitive data.
How Does Data Deduplication Work?
Data deduplication works by analyzing data and identifying duplicate patterns. The process generally follows these steps:
1. Data Segmentation
The system divides data into smaller chunks called blocks or segments. These blocks can be fixed-size or variable-size.
2. Hash Generation
Each block is processed using a hash algorithm to create a unique identifier. If two blocks produce the same hash value, they are considered identical.
3. Duplicate Detection
The system compares the hashes of new data with those of existing data stored in it. If a match is found, the block is marked as a duplicate.
4. Storage Optimization
Instead of storing the duplicate block again, the system stores a reference to the existing block. Unique data is stored.
5. Metadata Management
The system maintains metadata to track references, ensuring data can be restored correctly when needed.
Types of Data Deduplication
Here are the main types of data deduplication used in storage and backup systems to reduce duplicate data and save space.
1. File-Level Deduplication
File-level deduplication removes duplicate files by comparing entire files and storing only one copy, reducing storage usage but not detecting partial file changes.
- Simple to implement
- Less efficient for small changes in files
2. Block-Level Deduplication
Block-level deduplication splits files into smaller blocks, compares each block individually, and stores only unique blocks, improving storage efficiency compared to file-level methods.
- More efficient than file-level
- Commonly used in enterprise storage systems
3. Byte-Level Deduplication
Byte-level deduplication analyzes data at the smallest byte unit, detecting even tiny duplicates, providing maximum storage efficiency but requiring high processing power and time.
- Highest efficiency
- Used in advanced storage systems
4. Inline Deduplication
Inline deduplication removes duplicate data during the write process before storing it on disk, saving storage immediately but increasing CPU and processing overhead.
- Saves storage immediately
- Requires more processing power
5. Post-Process Deduplication
Post-process deduplication stores data first, then scans and removes duplicates later, reducing the performance impact during writes but requiring additional temporary storage space.
- Less impact on performance during storage
- Requires additional storage temporarily
6. Source-Based Deduplication
Source-based deduplication eliminates duplicate data at the originating system before transmission, significantly reducing network bandwidth usage, improving backup speed, and minimizing storage requirements.
- Reduces bandwidth usage
- Useful for remote backups
7. Target-Based Deduplication
Target-based deduplication removes duplicate data at the storage device after it has been transferred, making it easier to set up and compatible with current backup and storage systems.
- Easy to implement
- Works with existing systems
Advantages of Data Deduplication
Here are some important advantages of data deduplication.
1. Reduced Storage Cost
Removes duplicate data, significantly reducing storage requirements and lowering hardware, maintenance, and cloud storage expenses for organizations.
2. Improved Backup Efficiency
Deduplication minimizes backup data size, allowing faster backups, reduced storage usage, and improved efficiency in data protection processes across systems.
3. Faster Data Transfer
With fewer duplicate files, less data is transmitted over networks, improving bandwidth utilization and significantly increasing overall data transfer speed.
4. Better Disaster Recovery
Smaller backup sizes enable faster data replication and restoration, helping organizations recover systems more quickly during failures or disaster recovery situations.
5. Optimized Cloud Storage
Deduplication reduces the volume of stored data, helping organizations lower cloud storage costs while efficiently managing large volumes of digital information.
Disadvantages of Data Deduplication
The following are the major disadvantages.
1. High Processing Overhead
Requires hashing, indexing, and comparisons, which consume significant CPU, memory, and processing resources during storage operations.
2. Complex Implementation
Implementing deduplication systems requires careful configuration, monitoring, and management, making deployment difficult without proper planning, expertise, and maintenance tools.
3. Risk of Data Corruption
If deduplication metadata becomes corrupted, multiple files depending on shared data blocks may become inaccessible or permanently damaged in storage.
4. Not Suitable for Encrypted Data
Encrypted data appears unique after encryption, significantly reducing the effectiveness of deduplication in secure storage environments.
5. Initial Setup Cost
Enterprise deduplication solutions often require specialized hardware, software licenses, and configuration, resulting in higher initial implementation and deployment costs for organizations.
Difference Between Data Deduplication and Data Compression
The following table highlights the key differences between data deduplication and data compression.
| Feature | Data Deduplication | Data Compression |
| Purpose | Remove duplicate data | Reduce data size |
| Method | Stores a single copy of duplicates | Encodes data efficiently |
| Storage Saving | High when duplicates exist | Moderate |
| Performance Impact | Higher processing required | Lower processing |
| Use Case | Backup, cloud, storage | File transfer, archiving |
| Data Integrity | Maintains original data | Requires decompression |
Real-World Use Cases
The following are common real-world use cases in which it improves storage efficiency and performance.
1. Backup and Recovery Systems
Backup systems use deduplication to store only changed data blocks, reducing storage space, speeding backups, and significantly improving recovery efficiency.
2. Cloud Storage Services
Cloud storage providers use deduplication to eliminate duplicate data across users, reducing storage consumption, lowering costs, and improving resource utilization efficiency.
3. Virtualization Platforms
Virtualization platforms store many similar virtual machines, and deduplication removes duplicate operating system files, saving storage space and improving performance efficiency.
4. Email Servers
Email servers often store identical attachments across multiple accounts, and deduplication keeps one copy, reducing storage usage and improving server efficiency.
5. Big Data and Analytics
Big data systems often contain duplicate records and datasets, and deduplication removes them, reducing storage requirements and improving processing efficiency for analytics tasks.
6. Disaster Recovery
Disaster recovery systems use deduplication to replicate only changed data between locations, reducing bandwidth usage and enabling faster, more efficient recovery operations.
Final Thoughts
Data deduplication is a key storage optimization technology that helps organizations manage large data volumes efficiently by removing duplicate data. It reduces storage costs, speeds up backups, improves performance, and optimizes cloud usage. Despite requiring additional processing power, it is essential in cloud computing, virtualization, and big-data environments for efficient storage, lower infrastructure costs, and reliable data protection.
Frequently Asked Questions (FAQs)
Q1. Does deduplication affect performance?
Answer: It may increase CPU usage, but it improves overall storage and backup performance.
Q2. Can deduplication be used with cloud storage?
Answer: Yes, cloud providers widely use deduplication to reduce storage costs.
Q3. When should data deduplication not be used?
Answer: Data deduplication is less effective for encrypted, compressed, or highly unique data because duplicates are difficult to detect.
Recommended Articles
We hope that this EDUCBA information on “Data Deduplication” was beneficial to you. You can view EDUCBA’s recommended articles for more information.

