Updated March 23, 2023
Introduction to Create Decision Tree
The following article provides an outline for Create Decision Tree. With the recent rapid growth of the amount of data generated by information systems to handle large data sets, there is a dominant need for the decision tree to reduce computation complexity. Therefore, a decision tree can be considered the most important approach for representing classifiers. In other words, we can say the data are structured using a divide and conquer strategy. A decision tree is structured as a framework to accurate the values and probability of outcomes decisions from each level of the node, helping decision-makers to choose correct predictions among the various inappropriate data.
What is a Decision Tree?
A decision tree is a binary hierarchical structure that identifies the way where each node split a data set based on different conditions. To construct an optimal tree with a model approach to classify a response variable that predicts the value of a target variable with simple decision rules (if-then-else statements). The approach is supervised learning mostly used in classification problems and is considered to be a very effective predictive model. They are used in different application domains like Game theory, Artificial Intelligence, Machine Learning, Data Mining, and areas like security and medicine.
How to Create a Decision Tree?
A decision tree is created in simple ways with the top-down manner; they consist of nodes that form a directed node which has root nodes with no incoming edges all other nodes are called decision – nodes (internal node and leaf nodes which corresponds to attribute and class labels) with at least one incoming edges. The main goal of the data sets is to minimize generalization errors by finding the optimal solution in the decision tree.
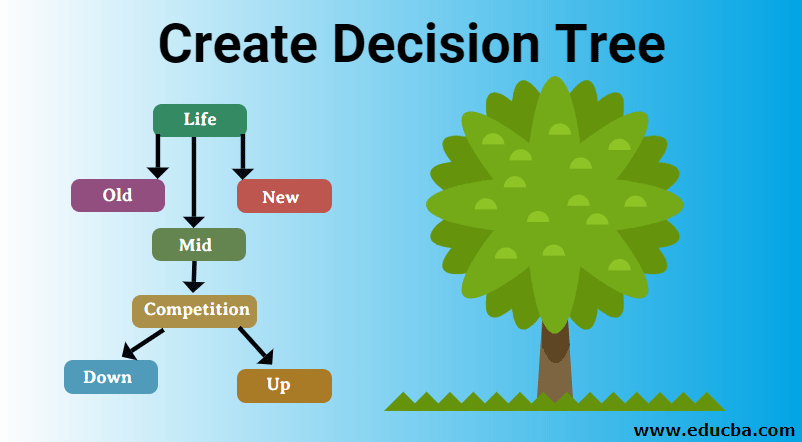
An example of a decision tree is explained below with a sample data set. The goal is to predict whether a profit is down or up using the attributes of life and competition. Here the decision tree variables are categorical (Yes, No).
Data Set:
| Life | Competition | Type | Profit |
| Old | Yes | Software | Down |
| Old | No | Software | Down |
| Old | No | Hardware | Down |
| Mid | Yes | Software | Down |
| Mid | Yes | Hardware | Down |
| Mid | No | Hardware | Up |
| Mid | No | Software | Up |
| New | Yes | Software | Up |
| New | No | Hardware | Up |
| New | No | Software | Up |
From the above data set: life, competition, Type are the predictors and the attribute profit is the target. There are various algorithms to implement a decision tree, but the best algorithm used to build a decision tree is ID3 which emphasis on greedy search approach. The decision tree follows the decision inference rule or disjunctive normal form(^).
Decision Tree:

Initially, all the training attribute is considered to be the root. The order priority for placing the attributes as root is done by the following approach. This process is known to attribute selection to identify which attribute is made to be a root node at each level. The tree follows two steps: construction of a tree, tree pruning. And the data are been split in all the decision nodes.
Information Gain:
It is the measure of the change in entropy based on the independent variable. The decision tree must find the highest information gain.
![]()
Entropy:
Entropy is defined as for the finite set, the measure of randomness in data or event predictability, if the sample is similar values then entropy is zero and if it is equally divided with the sample then it is one.
Entropy for the Class:
![]()
Where p is the probability of getting profit to say ‘yes’ and N is loss say ‘No’.
![]()
Therefore, entropy =1
Once entropy value is calculated it is necessary to decide a root node from the attribute.
Entropy of Age:

According to the data set for Life attribute we have old =3 down, mid = 2 down and one up concerning profit label.
![]()
| Life | Pi | ni | I(pi,ni) | |
| Old | 0 | 3 | 0 | |
| Mid | 2 | 2 | 1 | |
| New | 3 | 0 | 0 |
Gain = Class Entropy – Entropy of Life = 1 – 0.4 = 0.6
Entropy (competition) = 0.87
| Competition | Pi | ni | I(pi,ni) | |
| Yes | 1 | 3 | 0.8 | |
| No | 4 | 2 | 0.9 |
Gain = Class Entropy – Entropy of Life = 1 – 0.87 = 0.12
Now the problem arises in the attribute Life where the mid has an equal probability on both up and down. therefore, entropy is 1. similarly, it is calculated for type attribute again the entropy is 1 and gain is 0. Now a complete decision has been created to get an accurate result for mid-value.
Advantages and Disadvantages of Decision Tree
Given below are the advantages and disadvantages mentioned:
Advantages:
- They are easy to understand and the rules generated are flexible. Has little effort for data preparation.
- A visual approach to represent decisions and outcomes is very helpful.
- The decision tree handles the training data set with errors and missing values.
- They can handle discrete values and numerical attributes. It works with categorical and continuous variables for input and output.
- They are a useful tool for the business domain who has to take decisions after analyzing under certain conditions.
Disadvantages:
- Learners can create a complex decision tree depending on trained data. this process is termed as overfitting, a difficult process in decision tree models.
- The values preferred to be is categorical, if it is continuous, the decision tree loses information which leads to error-prone. Exponential calculation growth is higher while analyzing.
- Many class labels lead to incorrect complex calculations and give low prediction accuracy of the dataset.
- The information gained in the DT algorithm gives a biased response to categorical higher values.
Conclusion
Therefore, to conclude, decision trees provide a practical and easy method for learning and are strongly known as efficient tools for machine learning as in a short time they perform well with large datasets. It’s a learning task that uses a statistical approach to make a generalized conclusion. Now it’s better understood why the decision tree is used in predictive modeling and for data scientists they are a powerful tool.
Recommended Articles
This is a guide to Create Decision Tree. Here we discuss how to create a decision tree along with various advantages and disadvantages. You can also go through our other suggested articles to learn more –
