Updated February 17, 2023

Definition of Beautifulsoup lxml
Beautifulsoup lxml is a library of python which was used with HTML. It can now employ a variety of HTML parsers, each with its own set of benefits and drawbacks. BeautifulSoup can be used by lxml and as a parser by BeautifulSoup. The default is to utilize python’s built-in HTML parser, which is found in the html.Parser module. It is preferable to use html5lib’s HTML5 parser instead by going straight to lxml.html.
What is beautifulsoup lxml?
- It’s used to parse and act on markup languages, specifically XML and HTML. BeautifulSoup is a wrapper around various libraries that do this purpose.
- BeautifulSoup lxml allows us to parse HTML and XML files. It’s frequently used in web scraping.
- BeautifulSoup turns complicated HTML content into a complex tag, navigable strings, and comments.
- We can control how Element objects are created during the tree conversion process. The HTML parser specified in lxml.html is used as a default.
- For a quick comparison, soup attempts harder to stick to an HTML document’s structure and relocate misplaced tags to where they (most likely) belong. However, depending on the parser version, the outcome may differ.
- The lxml operations from string and parse perform as expected. The first gives us a root Element, whereas the second gives us an ElementTree.
- A legacy module, lxml.html, is also available. ElementSoup is a clone of Fredrik Lundh’s ElementSoup module’s user interface. ElementSoup was the only module 2.0.x.
- It’s a python library for parsing HTML and XML files and extracting data.
- It collaborates with a parser to provide navigation, searching, and modifying the parse tree.
- It’s a Python library, similar to lxml.html, for working with real-world and broken HTML. It uses the parser from lxml. BeautifulSoup can use Lxml as a backend for its parser.
- Its package for scraping the web and extracting the contents of HTML and XML documents.
- We initially acquire the HTML material, which we may then parse into a needed format or the original format of the content. We can transform our content into HTML using the “lxml” key.
Beautifulsoup lxml parser
- We need to follow the steps below to create an example of an lxml parser using beautifulsoup.
- In this step, we are installing the bs4 package by using the pip command. In the below example, we have already installed the bs4 package in our system, so it will show that the requirement is already satisfied, so we do not need to do anything.
pip install bs4
- After installing the bs4 package in this step, we install the request packages. In the below example, we have already established a requests package in our system, so it will show that the requirement is already satisfied, so we do not need to do anything.
pip install requests
- After installing all the modules, we open the python shell by using the python3 command.
python3
- After logging into the python shell in this step, we check bs4, and the requests package is installed in our system.
import bs4
import requests
- After checking all the prerequisites in this step, we import the library of bs4 and request packages.
from bs4 import BeautifulSoup
import requests

- The below example shows beautifulsoup lxml by using a web url. We are using a web url as a python website.
Code –
from bs4 import BeautifulSoup
import requests
py_wurl = input("URL is : ")
py_doc = requests.get (py_wurl)
py_con = py_doc.content
py_lxml = BeautifulSoup (py_con , "lxml")
print (py_lxml)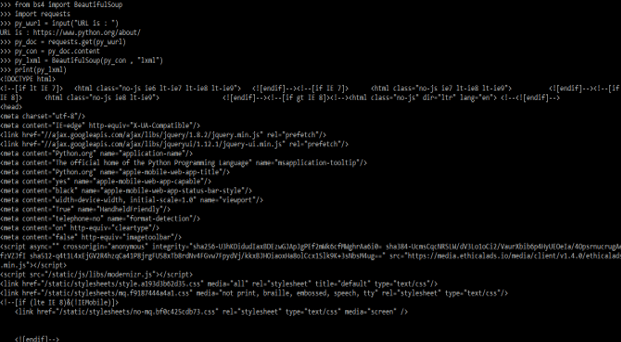
Beautifulsoup lxml Web scraping
- There are numerous Python modules available that can assist with web scraping. For example, there’s lxml, BeautifulSoup, and Scrapy, a full-fledged framework. For example, the steps below show beautifulsoup lxml web scraping.
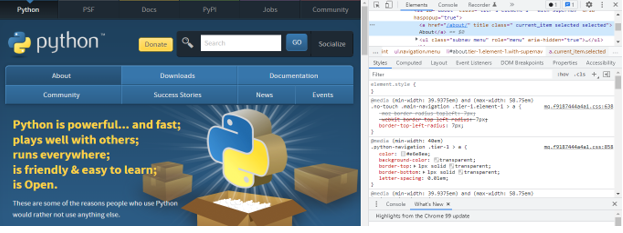
1. Exploring url –
-
- We are using the element inspector tool. We may inspect a single element on the page with only one click.
- The below example shows exploring the url are as follows.
2. Create a python script –
-
- In this step, we are writing the python script. First, we need to install bs4 and the requests module to write the python script. We can install those modules by using the pip command.
- In this script, we are importing the request and lxml.html module. We’ll use the requests package in python to open a web page. We could have opened the HTML page with lxml, but it doesn’t work with all web pages.

Code –
import requests
import lxml.html
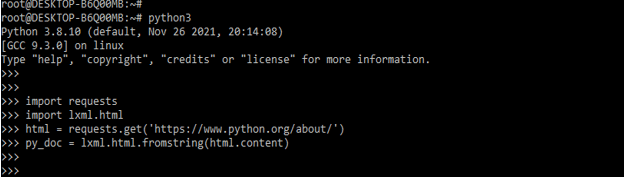
html = requests.get('https://www.python.org/about/')
py_doc = lxml.html.fromstring (html.content)3. Execute the code on the python interpreter –
-
- After creating the above python script, we execute the same using the python interpreter in this step.
- To check the XPath, we are executing the same manually. We are also writing the xpath to extract the div.
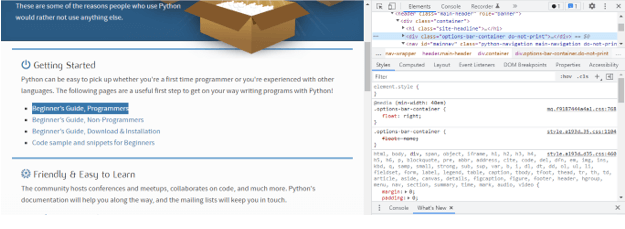
4. Extract the tabs –
-
- The below example shows extracting the tabs from the python website. We are extracting a single tab. The tab is contained in the div class.
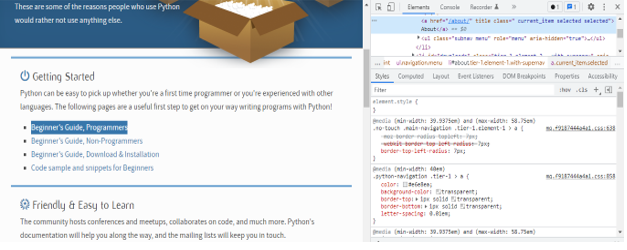
5. Extracting the tags –
-
- In this step, we are extracting the tags as follows. We are extracting the tag as per titles.
6. Example of lxml web scraping –
- The below example shows that lxml web scraping is as follows.
Code –
import requests
import lxml.html
py_url = requests.get ('https://store.steampowered.com/explore/new/')
py_doc = lxml.html.fromstring (py_url.content)
py_rel = py_doc.xpath ('//div[@id="tab_newreleases_content"]')[0]
py_title = py_rel.xpath ('.//div[@class = "tab_item_name"]/text()')
py_price = py_rel.xpath('.//div[@class = "discount_final_price"]/text()')
py_tags = [tag.text_content () for tag in py_rel.xpath ('.//div[@class = "tab_item_top_tags"]')]
py_tags = [tag.split (', ') for tag in py_tags]
py_plat = py_rel.xpath ('.//div[@class="tab_item_details"]')
tot_plat = []
for game in py_plat:
py_temp = game.xpath ('.//span[contains(@class, "platform_img")]')
plat = [t.get ('class').split(' ')[-1] for t in py_temp]
if 'hmd_separator' in plat:
plat.remove ('hmd_separator')
tot_plat.append (plat)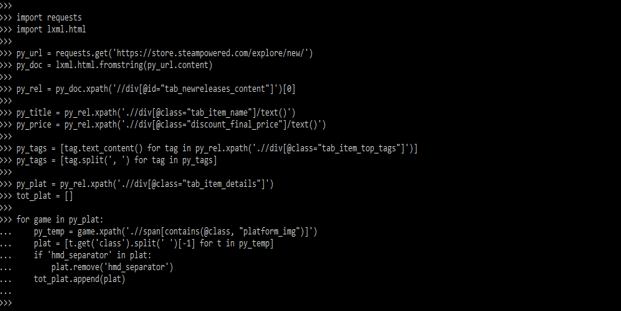
Conclusion
BeautifulSoup’s outstanding encoding identification support helps improve web pages’ outcomes that disclose their encoding. The lxml.html.soupparser module connects lxml to BeautifulSoup. It has three primary functions from string and parses, which convert BeautifulSoup into Elements and convert tree, which converts an existing BeautifulSoup tree into a list of top-level Elements.
Recommended Articles
This is a guide to Beautifulsoup lxml. Here we discuss the Definition, What is beautifulsoup lxml, parser, Web scraping, and examples with code implementation. You may also have a look at the following articles to learn more –

