Updated February 18, 2023

Introduction to BeautifulSoup get text
BeautifulSoup get text is the process of retrieving information from a web page’s HTML or XML content using software bots known as web scrapers. It is a python module that allows us to scrape data. BeautifulSoup collaborates with a parser to allow for iteration, searching, and modification of the parser’s content (in the form of a parse tree). As a result, BeautifulSoup makes it relatively simple to crawl through web pages.
What is BeautifulSoup get text?
- Handling the documents of XML and HTML requires several parsers, such as lxml and html parser.
- BeautifulSoup allows us to travel around the HTML document tree and edit it programmatically in addition to extracting data.
- BeautifulSoup is typically used with the requests package, which gets a page from which BeautifulSoup extracts the data.
- A string is one of the most basic types of filter. BeautifulSoup will do a match on a string if we pass it to the search method. We can search for all tags that begin with a specific string or tag.
- The get text method in BeautifulSoup is used to get the text from an element. We can use it by simply invoking the object method. However, because the object represents a string, get text does not operate on Navigable String.
- BeautifulSoup gives several parameters to help us refine our search, one of which is a string.
- We have a variety of filters that we are passing into this method, and it’s essential to understand them because they’re used often throughout the search API.
- These filters can be applied to tags based on their names, attributes, string text, or combination.
- The HTML file can be found in the anchor tag a>, span span span>, paragraph tag p>, and other tags. As a result, the lovely soup assists us in obtaining our desired output, such as extracting paragraphs from a specific url/html file.
- BeautifulSoup package for extracting information from HTML and XML documents. Python doesn’t include this module by default.
- Queries make it incredibly simple to send HTTP/1.1 requests. Unfortunately, python does not include this module as well.
BeautifulSoup get text Web Pages
To create an example of get text web pages by using BeautifulSoup, we need to follow the below steps:
1. In this step, we install the bs4 package using the pip command. In the below example, we have already installed the bs4 package in our system, so it will show that requirement is already satisfied, then we have no need to do anything.
Code:
pip install bs4
Output:

2. After installing the bs4 package in this step, we install the requested packages. In the below example, we have already installed the requests package in our system, so it will show that requirement is already satisfied, then we have no need to do anything.
Code:
pip install requests
Output:

3. After installing all the modules, we open the python shell using the python3 command.
Code:
python3
Output:
4. After logging into the python shell in this step, we check bs4, and the requests package is installed in our system.
Code:
import bs4
import requests
Output:
5. After checking all the prerequisites in this step, we import the library of bs4 and request packages.
Code:
from bs4 import BeautifulSoup
import requests
Output:

6. After importing the library in this step, we assign the URL; we use the Google URL.
Code:
url = https://www.google.com/
Output:

7. After assigning the URL in this step, we are fetching the raw html content from this URL as follows.
Code:
py_con = requests.get(url).text
Output:

8. After fetching raw html content in this step, we are parsing through the content; after parsing the content, we are printing its text.
Code:
py_soup = BeautifulSoup(py_con, "html.parser")
print(py_soup.find('title').text)
Output:

BeautifulSoup get text Method
- The URLLib method corresponds to the specified URL. After obtaining the HTML using the urlopen (html).read() function, BeautifulSoup’s get text() method is used to acquire the HTML text.
- NLTK.clean html() is recommended in a few NLP publications. However, in the latest NLTK implementation, the NLTK.clean html method is deprecated.
- To remove HTML markup, utilise BeautifulSoup’s get text() function, according to the NLTK.clean html technique.
- Once HTML content has been acquired, use the NLTK word tokenize method to recover words and punctuations.
- Then, using word filtering techniques, we can further filter out terms that fit the criteria, such as word length.
- We may also use NLTK Text to construct frequency distributions using NLTK. The below example shows BeautifulSoup get text method.
Code:
from bs4 import BeautifulSoup
import requests
py_url = "https://www.google.com/"
py_con = requests.get (py_url).text
py_soup = BeautifulSoup (py_con, "html.parser")
print (py_soup.find ('title').text)
Output:
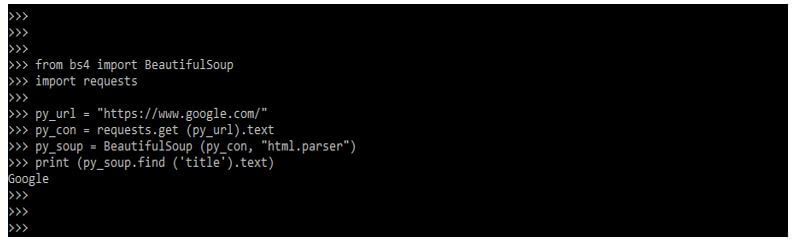
- In the above example, after assigning the URL, we fetched the raw content after parsing the content using the py_soup variable.
BeautifulSoup get text Tags
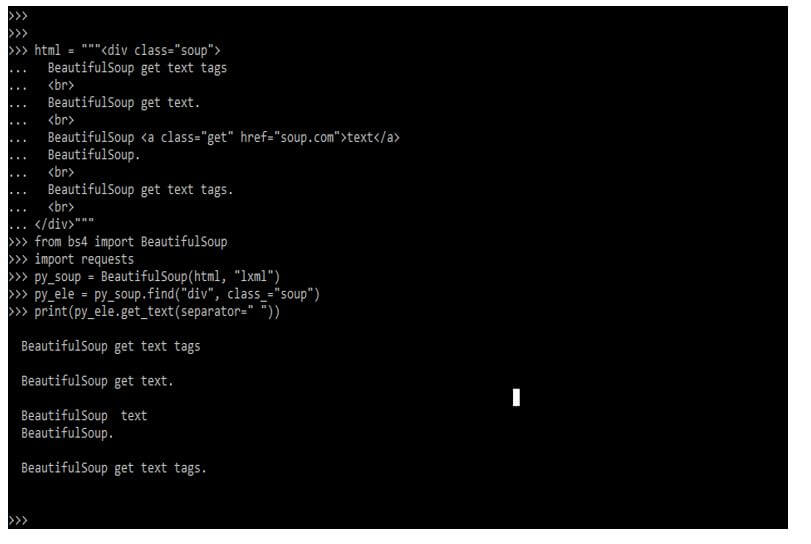
- Every time a tag is closed, BeautifulSoup get text and adds a new line character. Therefore, there are situations when we need to split it by br> tags rather than the correct tags.
- The below example shows the use of BeautifulSoup get text.
Code:
html = """<div class="soup">
BeautifulSoup get text tags
BeautifulSoup get text.
BeautifulSoup <a class="get" href="soup.com">text</a>
BeautifulSoup.
BeautifulSoup get text tags.
</div>"""
from bs4 import BeautifulSoup
import requests
py_soup = BeautifulSoup(html, "lxml")
py_ele = py_soup.find("div", class_="soup")
print (py_ele.get_text(separator=" "))
Output:
In the below example, we are replacing every tag with a string.
Code:
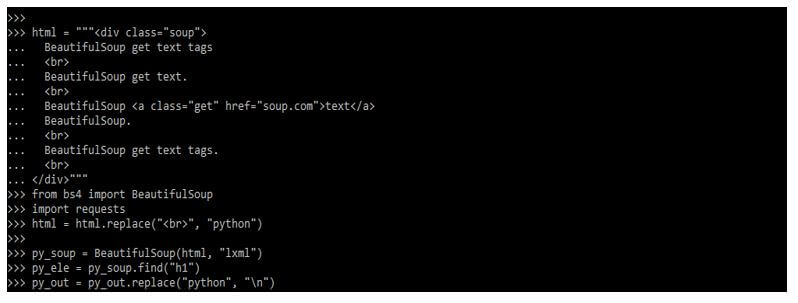
html = """<div class="soup">
BeautifulSoup get text tags
BeautifulSoup get text.
BeautifulSoup <a class="get" href="soup.com">text</a>
BeautifulSoup.
BeautifulSoup get text tags.
<br>
</div>"""
from bs4 import BeautifulSoup
import requests
html = html.replace ("<br>", "python")
py_soup = BeautifulSoup(html, "lxml")
py_ele = py_soup.find("h1")
py_out = py_out.replace ("python", "\n")
Output:
Conclusion
Handling the documents of XML and HTML requires several parsers, such as lxml and html parser. BeautifulSoup get text is the process of retrieving information from a web page’s HTML or XML content using software bots known as web scrapers. BeautifulSoup get text method is critical in python.
Recommended Articles
This is a guide to BeautifulSoup get text. Here we discuss the introduction; BeautifulSoup get text web pages, method, and tags. You may also have a look at the following articles to learn more –

