
What is Microsoft Azure Databricks?
Microsoft Azure databricks is a full platform managed service and it is an apache spark based analytics platform and used as a Microsoft azure cloud service. Databricks uses apache-spark hence it is fast and easy and can be used to generate a big data pipeline to ingest data into the Azure data factory. It is integrated with the other azure cloud services and has a one-click setup using the azure portal and also it supports streamlined workflows and an interactive workspace that helps developer, data engineers, data analyst and data scientist to collaborate.
How does Microsoft Azure Databricks Work?
Azure databricks platform is a first-party microsoft service as it is natively integrated with azure to provide the best platform for the engineering and data scientists team. It is combined with apache spark to provide fast and easy cloud service for data analytics. To generate an end to end data pipeline the data (raw or structured) is ingested into azure in batches using the azure data factory service or for streaming, Kafka, event hub, or IoT hub is used which basically takes data from different sources like SFTP, MySQL or CSV/JSON format files, etc. This data is ingested and loaded into the data lake for an indefinite time in persisted storage or in azure blob or azure data lake storage.
It can read data from sources such as azure blob, azure data lake, cosmos DB or Azure SQL data warehouse, and users, developers, or data scientists can make business insights on this data by processing using apache spark.
Below is a brief explanation of the components used in Azure Databricks:
- Apache Spark in Databricks: It provides a cloud platform with zero management with an interactive workspace for data visualization and analysis.
- Databrick Runtime: It is built for an azure cloud on top of apache spark. Databricks has a “serverless” option which removes the infrastructure complexity of setting up and configuring databricks as per data which helps data scientists. As part of support to data engineers as they manage the performance of jobs. Databricks has a spark engine that has multiple optimizations at the I/O layer and processing layer also called as “Databricks I/O”.
- Workspace for Collaboration: Using the collaborative environment can set up the process of exploring data and running spark applications. Document or notebook used in the workspace can be in r, python, scala or SQL which uses spark engines to interact with data.
- Databricks Enterprise Security: It has enterprise-grade security like azure directory integration, role-based control and to protect business there as defined.
How to Create and Use Databricks in Azure?
Pre-requisites: Before learning to create the azure databricks workspace users must have an Azure subscription so that you can log in with valid credentials to the azure portal and create azure databricks workspace.
Steps using Azure Portal:
Here we discuss the steps using Azure portal:
Create an Azure Databricks Workspace:
Step 1: Login into the Azure Portal using the below URL:
https://portal.azure.com/learn.docs.microsoft.com

Step 2: From the azure portal home page select the +create a resource.
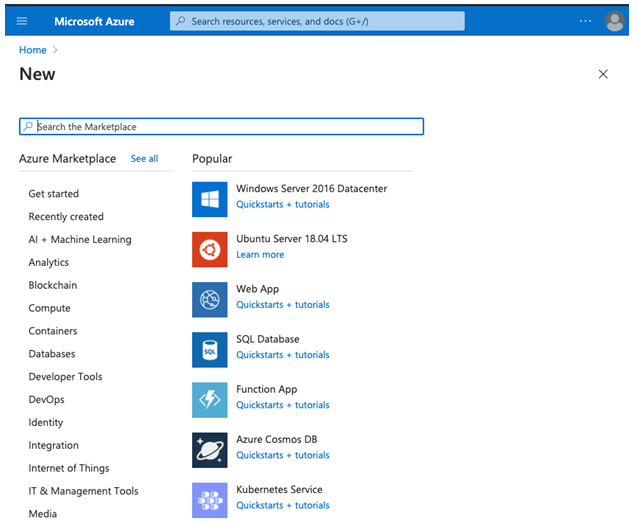
Step 3: In the search field of azure marketplace search for azure databricks and click on enter to open the azure databricks create page.
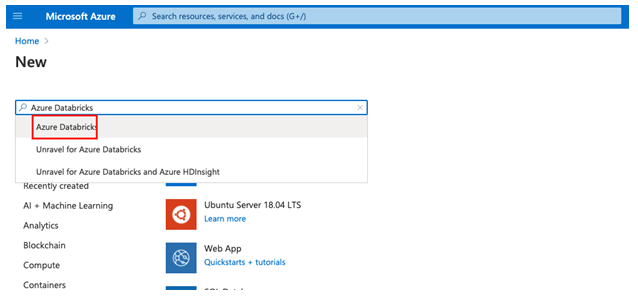
Step 4: From the azure databricks page select create.
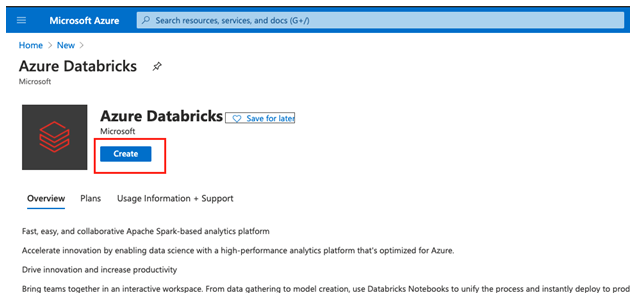
Step 5: On a create an azure databricks workspace user need to enter the project details.
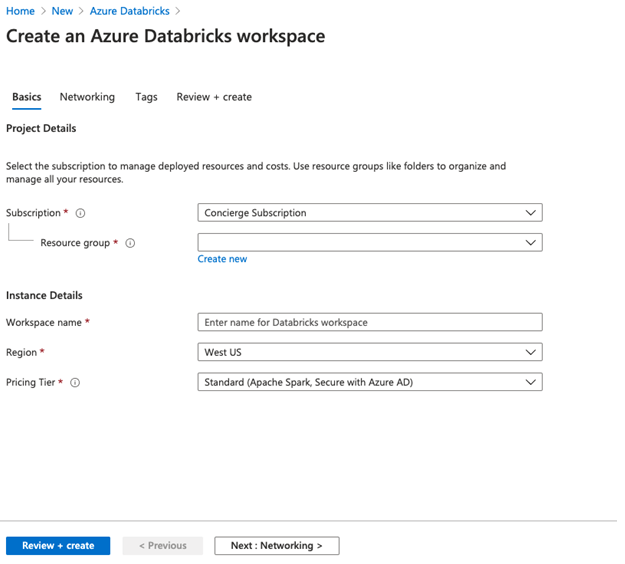
Step 6: Enter the details of the new bastion as below.
- Subscription: Select your subscribed plan from the drop-down list.
- Resource group: Select the resource group in which you want to create a bastion.
- Workspace name: Enter the unique name for the databricks workspace instance.
- Location: Select region/location from the down list.
- Pricing tier: Select pricing tier from drop-down list below are the three pricing tiers (for demo purpose I have selected 14-day free).

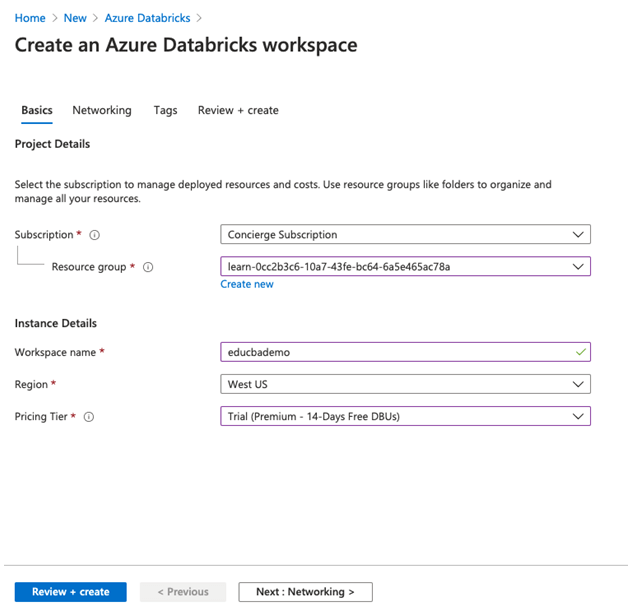
Step 7: Select review+create and then click on create from the page to deploy the workspace.
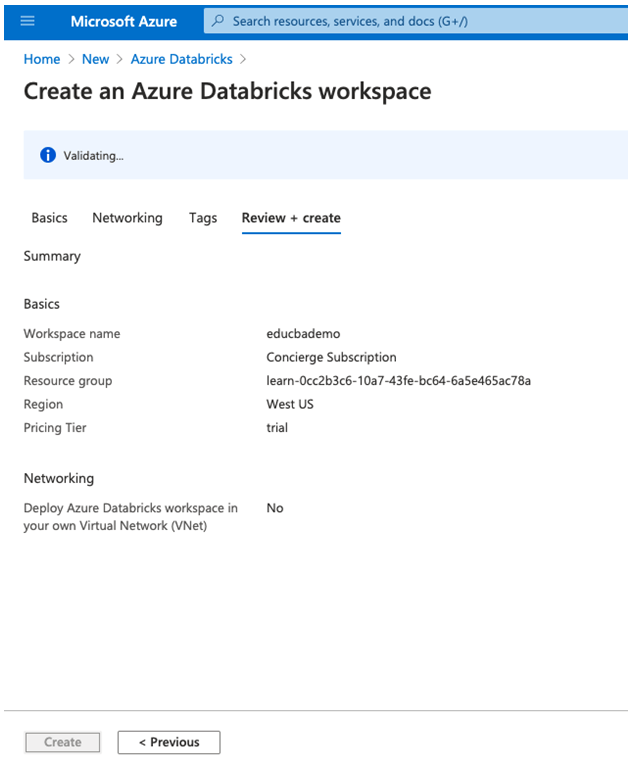
Create a Cluster:
Step 8: Once the workspace is created from the Azure portal select databricks workspace you created and click on launch workspace.
Step 9: Once the launch is completed portal will open and select a new cluster from the portal.
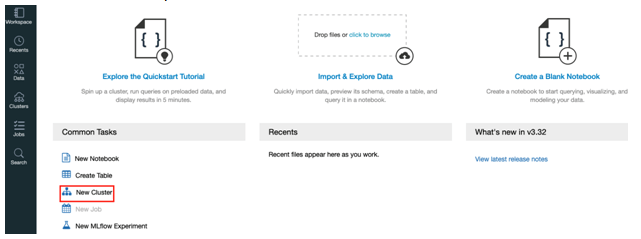
Step 10: Now on the new cluster page enter the values to create a cluster.
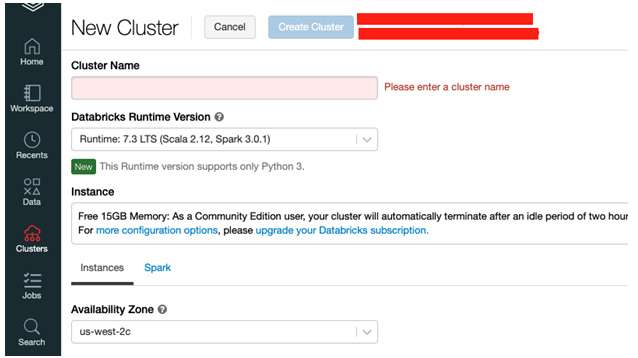
Users will be prompted with some other values in new cluster creation:
- Enter the name of the cluster.
- Provide worker type and driver type users can select the runtime version.
Step 11: click on create cluster to create a new cluster.
Step 12: Once the cluster is running users can attach a notebook or create a new notebook in the cluster by clicking on the azure databricks.
- User can select a new notebook to create a new notebook.
- Import or export data.
Uses of Azure Databricks
Given below are the uses mentioned:
- Fast Data Processing: It uses an apache spark engine which is very fast compared to other data processing engines and also it supports various languages like r, python, scala, and SQL.
- Optimized Environment: It is optimized to increase the performance as it has advanced query optimization and cost efficiency in the cloud as it reduces cost by 10-100x while running on azure.
- Integration with Other Azure Services: It is seamlessly and deeply integrated with azure databases and storage like a blob, cosmos DB, etc. Users can also leverage various external Databricks connectors for scalable data storage and in-depth analytics.
- Enterprise Security: It has enterprise-level security as it uses azure active directory and role-based access control system of Azure cloud.
Conclusion
In conclusion, users can use Azure databricks service to get more business and Data insight as there will be less hassle of security, management, and also data processing will be fast with low latency due to the use of apache spark.
Recommended Articles
This is a guide to Azure Databricks. Here we discuss the introduction and how microsoft azure databricks work along with steps using Azure portal. You may also have a look at the following articles to learn more –

