Difference between Azure Data Factory vs Databricks
Azure data factory vs databricks is two clouds based ETL and data integration tools that handle various types of data like batch streaming and structured and non-structured data. Azure data factory is an orchestration tool that is used for services of data integration which carries the ETL workflow and scaling the data transmission. Azure databricks provide a platform of single collaboration for engineers and data scientists.
Azure data factory is used in the service of data integration, so we can say that it is used for orchestrating data movement and ETL. Databricks focuses on collaboration with other team members like data scientists and data engineers; for using ML models, we need a single platform.
Azure data directory is a GUI based integration tool that contains less learning curve. Azure databricks requires learning Scala, Java, R, Python, and spark for data engineers and data scientists-related activities, which use notebooks for writing code and collaborating with peers.
Basically, the azure data directory is GUI based tool, so we have less flexibility; if we have to modify our code to complete the activity in less time, we are doing a programming approach. Databricks developer will contain the code flexibility and fine-tuning for improving the processing capabilities and methods of performance optimization.
Azure data directory and databricks both are supporting for streaming and batch operations, but azure data factory is not supporting to real-time streaming. Databricks uses real-time streaming.
What is Azure Data Factory?
Azure data factory is a cloud service of ETL for scaling out the data integration and the transformation of data. Azure data factory offers the code-free UI of single pane glass monitoring and UI intuitive for management. We are also shifting and lifting the package of SSIS for azure and run the same by using full compatibility of azure data factory. The integration runtime of SSIS offers a fully managed service, so we have no worries about the management of infrastructure.
Azure data factory is a cloud-based PaaS that offers an azure platform to integrate the different types of data services and sources. It will come with pre-built connectors and provide the solution for ETL, ELT, and other types of data integration pipelines. ETL tool extracts the data and transforms data to intended analytical use cases.
What is Databricks?
Azure databricks is a SaaS based tool of data engineering which processes massive quantities of data for building models of machine learning. Azure databricks is supported by various services of cloud-like google cloud, azure, and AWS. Azure databricks are optimized by using the Azure cloud platform, which offers data science and data engineering environments for developing the applications.
By using azure data bricks, we are running SQL queries on Data Lake to create multiple visualizations for exploring the results of queries for building the dashboards of share. Databricks provides a collaborative and interactive workspace for machine learning engineers and data engineers to build complex projects of data science.
Head to Head Comparison Between Azure Data Factory vs Databricks (Infographics)
Below are the top 10 differences between Azure Data Factory vs Databricks:
Key Difference Between Azure Data Factory vs Databricks
Let us discuss some of the major differences between Azure Data Factory vs Databricks:
- Azure data factory is a data integration service and orchestration tool for performing the ETL process and orchestrating the data movements. Azure data bricks is providing a unified collaborative platform for data scientists and data engineers.
- By using data bricks, we can use python, spark, and java for performing data engineering and data science activities. Azure data directory provides the drag-and-drop feature for creating and maintaining the data pipelines for tools of the graphical user interface.
- Azure data factory is facilitating the process of the ETL pipeline by using GUI tools; developers will contain less flexibility for modifying the code. Databricks is implementing the programmatic approach for providing flexibility and fine-tuning code to optimize performance.
- Databricks offers batch streaming processing while working with a large amount of data. Batch deals with the bulk data. Data bricks support the archive streaming options.
- Data factory is offering the transformation of the data integration layer, which supports digital transformation activities. Azure data factory enables work efficiently with an open and unified platform for any kind of analytics workload.
- Data factory is enabling the data engineers to manage and prepare the data and develop the ETL workloads. Azure data factory is providing an easy control version of the notebook by using GitHub.
Azure Data Factory Requirement
Azure data factory requires the following essential components. Pipeline is the most important component.
- Pipeline – It is a logical group activity that was used to perform the unit of work. Single pipeline performs different actions like blob storage.
- Activities – It is representing the unit of work in the pipeline. It includes the activities which were used to copy the blob data for the storage table for transferring JSON data into the blob storage.
- Datasets – It represents the data structures within the data store. Datasets point to the data activities which need to use in inputs and outputs.
- Triggers – It defines the way to execute in pipeline. Triggers are determining when we are beginning our execution of the pipeline.
It will contain three types:
-
- Schedule trigger
- Window trigger
- Event based trigger
- Integration runtime – It will contain the computing infrastructure which was providing the capabilities of data integration like data movement or data flow.
Databricks Requirement
The developers in data bricks have the freedom to tweak the code activities by using a variety of performance optimization techniques which enhances the capabilities of data processing. Databricks is supporting the spark clusters, it will handle more data efficiently, and the data factory is connecting to the various types of data sources.
By using databricks, we can seamlessly integrate open-source libraries and its access by the most recent versions of apache spark. Due to the global scalability of azure, we are easily creating the clusters and building the managed spark environment. By using azure machine learning, databricks is giving us access to automated machine learning capabilities which enable the algorithms.
Comparison Table of Azure Data Factory vs Databricks
Below is the top comparisons between Azure Data Factory vs Databricks:
| Sr. No | Azure Data Factory | Azure Databricks |
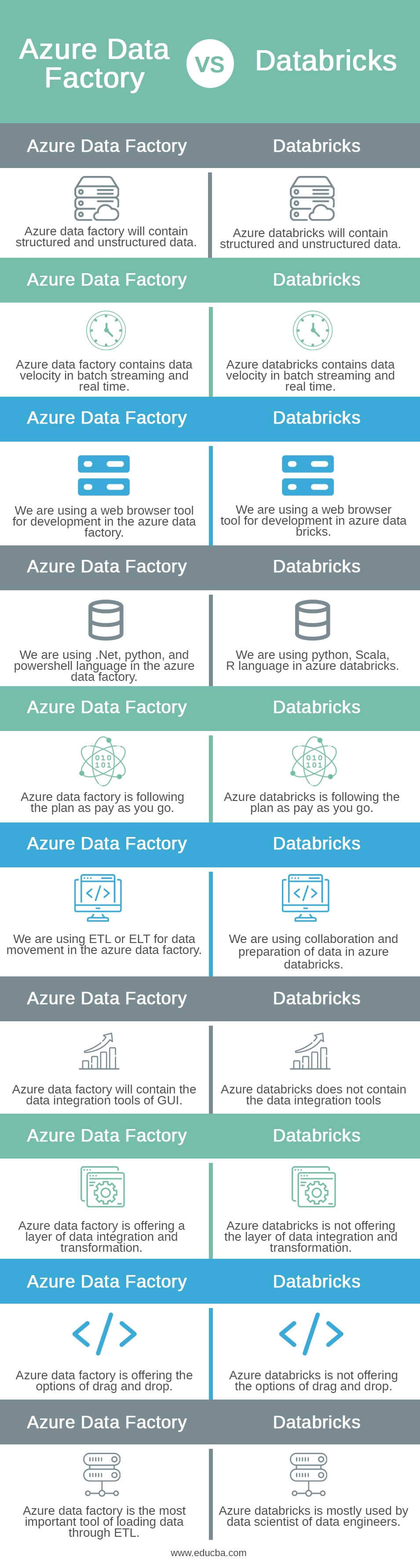
| 1 | Azure data factory will contain structured and unstructured data. | Azure databricks will contain structured and unstructured data. |
| 2 | Azure data factory contains data velocity in batch streaming and real-time. | Azure databricks contains data velocity in batch streaming and real-time. |
| 3 | We are using a web browser tool for development in the azure data factory. | We are using a web browser tool for development in azure data bricks. |
| 4 | We are using .Net, python, and powershell language in the azure data factory. | We are using python, Scala, R languages in azure databricks. |
| 5 | Azure data factory is following the plan as pay-as-you-go. | Azure databricks is following the plan as pay-as-you-go. |
| 6 | We are using ETL or ELT for data movement in the azure data factory. | We are using collaboration and preparation of data in azure databricks. |
| 7 | Azure data factory will contain the data integration tools of GUI. | Azure databricks does not contain the data integration tools |
| 8 | Azure data factory offers a layer of data integration and transformation. | Azure databricks is not offering the layer of data integration and transformation. |
| 9 | Azure data factory offers the options of drag and drop. | Azure databricks is not offering the option of drag and drop. |
| 10 | Azure data factory is the most important tool for loading data through ETL. | Azure databricks is mostly used by data scientists of data engineers. |
Purpose of Azure Data Factory
Azure data factory is primarily used for data integration services to perform the ETL process and orchestrate the data movement as per the scale. The azure data factory is providing the visual data pipeline interface, which was code free. Also, it describes the workflows which were allowing data engineers and data integrator which were non-expert to accomplish their tasks of data manipulation.
Azure data factory is providing the movement of azure blob storage data by using pipeline of azure. By using azure data factory, we are integrating our data with a fully managed service of data integration. By using the azure data factory, we can also integrate the service azure synapse for unlocking the business insights of the azure data factory; we are using ADF in multiple scenarios.
Purpose of Databricks
Databricks provides a collaborative platform for data scientists and data engineers to perform the operations of ETL for building machine learning models into a single platform. The main purpose of using azure databricks is to analyze, monitor, and monetize the datasets.
We are using the azure databricks platform for building multiple applications. The azure data bricks workspace provides user interfaces for providing multiple core data tasks, which include the tools.
Conclusion
Azure data factory is used in the service of data integration, so we can say that it is used for orchestrating data movement and ETL. Azure data factory vs databricks is two cloud-based ETL and data integration tools which were handling various types of data like batch streaming and structured and non-structured data.
Recommended Articles
This is a guide to Azure Data Factory vs Databricks. Here we discuss the key differences with infographics and a comparison table. You may also look at the following articles to learn more –
