Updated March 17, 2023
Introduction to Azure Data Factory Data Flow
Azure Data Factory Data Flow are visually designed data transformations in Data Factory. Azure Data Factory is managed by serverless data integration services of Azure Data Platform. Building pipelines, users can manipulate and transfer data from various data sources. In this article, we shall see Azure Data Flow, how to create and use Data Flows in Azure, and also go through why data flows should be used.
Key Takeaways
- Azure Data Factory has introduced the concept of Data Flow, which is powerful, scalable, and flexible transformation capabilities.
- Data Flow is not suitable for smaller datasets as there is a considerable overhead of underlying clusters.
- Pre-requisites for working with Data Flow are to have a Subscription and Azure Storage Account.
- Data Flow allows various data types such as binary, array, boolean, decimal, complex, integer, date, float, short, map, string, long, and timestamp.
- Mapping data flow is operationalized within the Data Factory pipeline using data flow activity and integrates with existing ADF monitoring capabilities.
- Also, various data flow transformations are available such as SPLIT, JOIN, UNION, EXISTS, DERIVED COLUMN, LOOKUP, AGGREGATE, SELECT, PIVOT, SEGGREGATE KEY, UNPIVOT, RANK, WINDOW, PARSE, FLATTEN, SORT, and FILTER.
Overview of Azure Data Factory Data Flow
It allows Data flow, a feature in Azure Data Factory that allows data engineers to develop data transformation logic without writing logic in a graphical approach. Resultant data flow can be executed as the activities within the Data Factory pipeline, which uses a scale-out spark cluster.
Azure Data Factory handled all code translation, execution of a transformation, and spark optimization internally. These Data flow activities are operationalized through existing Data Factory control, scheduling, and monitoring capabilities.
Two types of Data Flow are available in Data Factory:
- Wrangling Data Flow
- Mapping Data Flow
How to Use Azure Data Factory in Data Flow?
Data Flow in Azure Data Factory allows users to pull data to ADF runtime and manipulate it, then write back to the destination. It is similar to the data flow concept in SSIS but has more flexibility and scalability.
ADF has two types of Data Flows:
- Power Query
- Data Flow
1. Power Query
Data Flow uses Power Query Technology, found on the Power BI desktop. On writing, it stands in preview mode. And was also called as Wrangling Data Flow previously.
2. Data Flow
It is the regular data flow, also known as Mapping Data Flow. Data Flow in Azure is a visual and code-free transformation layer that uses the Azure Databricks cluster behind. DF’s are abstraction layers on top of Azure Databricks and can be executed in a regular pipeline.
When a user wants to perform transformations by using two or more datasets, then can use Mapping Data Flow. Users can perform various transformations like Filter, Aggregate, JOIN, Lookup, Sort, UNION, etc, using Mapping Data Flow. Azure Data Factory handles code transformations and execution of the Mapping Data Flow behind the scenes. It can be created individually or within the ADF pipeline.
How to Create a Mapping Azure Data Factory in Data Flow?
Step 1: When DF starts to run, it uses the default cluster of AutoResolveIntegrationRuntime, or creates new runtime.
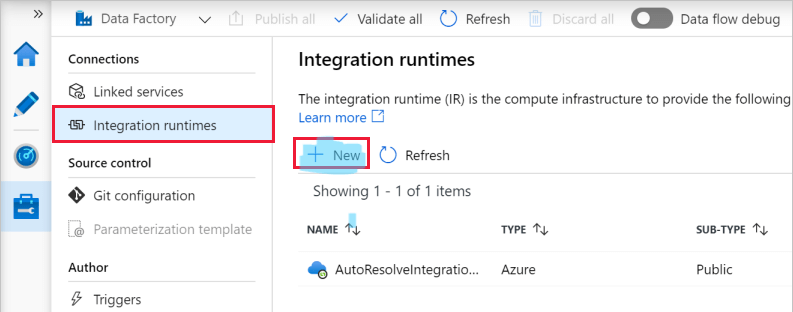
Step 2: Creating own runtime allows choosing different cluster sizes and times to live smaller. If the cluster gets paused, the user need not pay while on pause. Hence, to save costs, can pause as soon as possible when not needed. Below are mentioned few options that need to be selected.

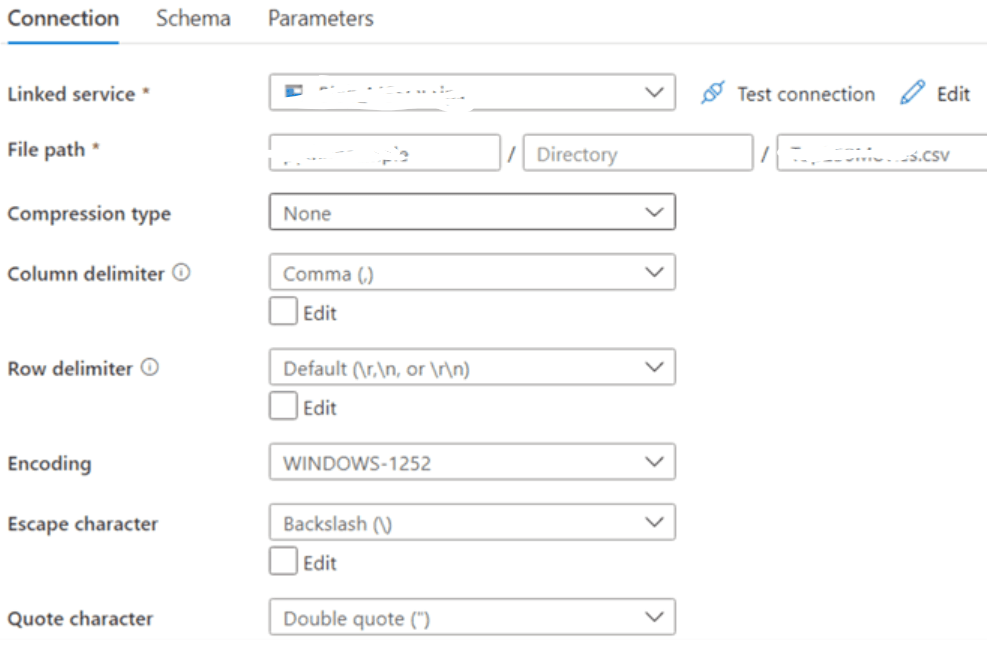
Step 3: Take a sample flat file in Blob Storage with a single column. Let us consider Various Company names with numbers beside them and separate the number and company name into two columns, writing results to a database. The first step is to create a dataset in Data Factory pointing to the file.
Step 4: Data options like schema drift and sampling can be configured as below.
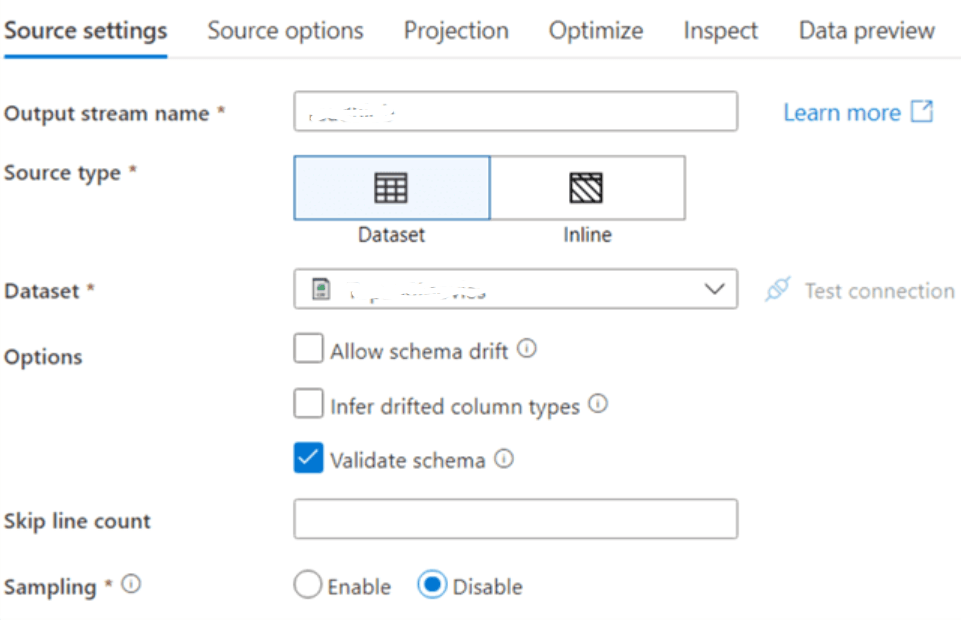
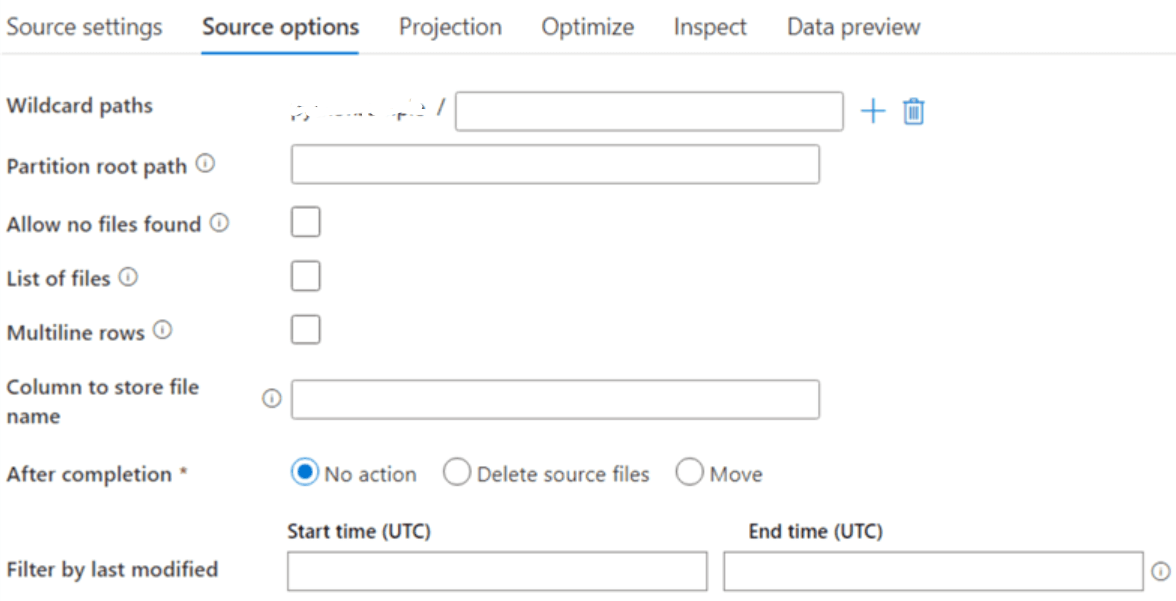
Step 5: In Source options, the user can configure partitioning, filtering, and wildcards.
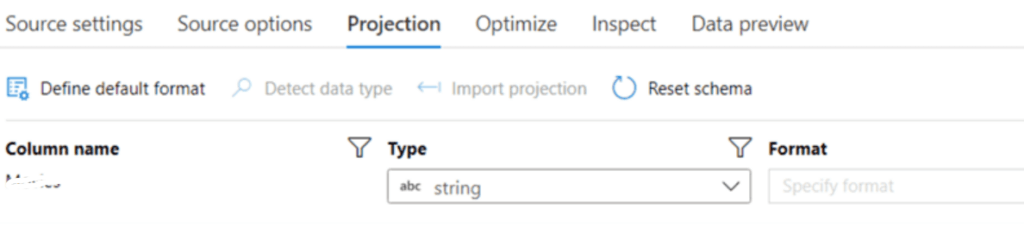
Step 6: In projection, the user can import the schema of the source file.
Step 7: Debug mode needs to be enabled on data flow for data preview. If Time to Live cluster is reached, data flow gets turned off to save cost, and the user has to start again. Extra branches can be added by clicking plus icon beside the transformation or source.
Step 8: Here user splits the columns using split function.
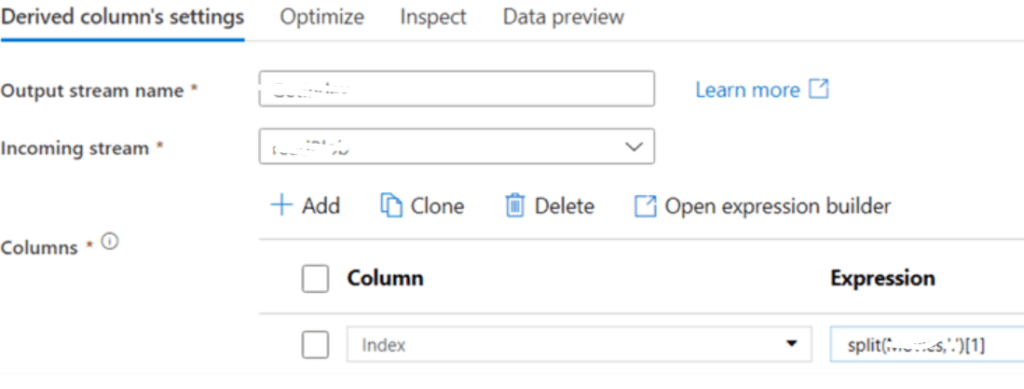
Step 9: User can also create column patterns besides creating expressions for a single column with Add Column option, which allows the reusing of similar expressions over several columns. Once the final column is generated, the index column gets converted to an integer.
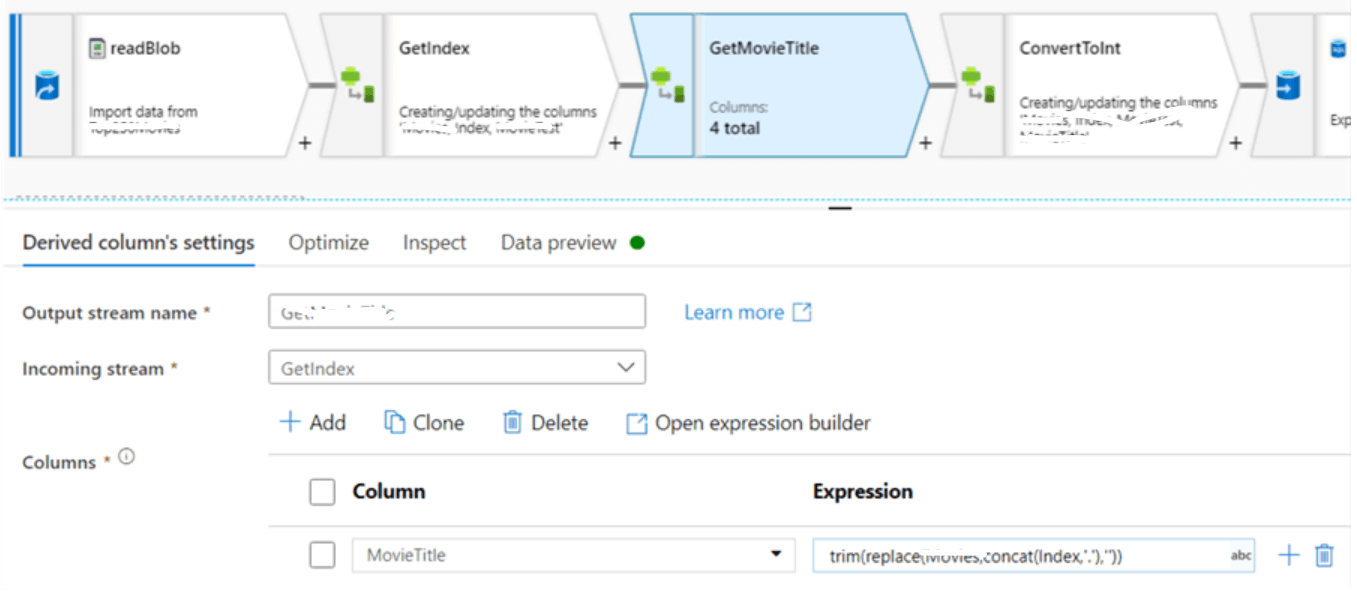
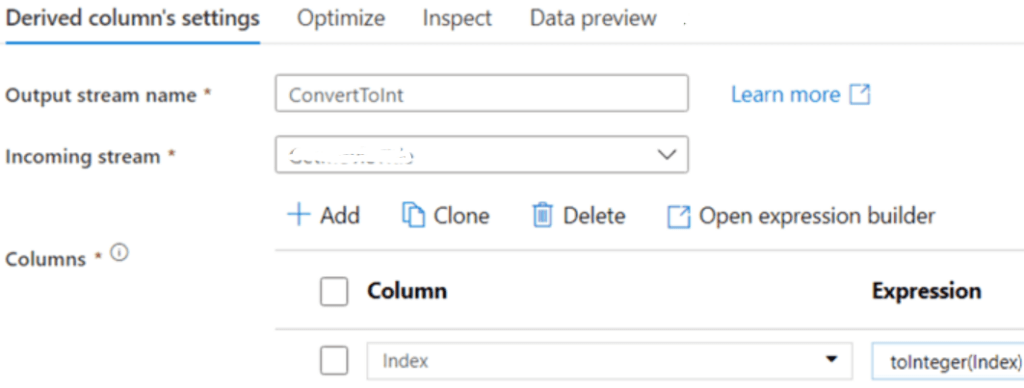
Step 10: The data is written to SQL database in Azure, as in source, the user needs to define the dataset. Sink can handle insertion, deletion, and updation; the table can be dropped and created again or truncated. User can even specify the script which needs to run before or after data has been written.
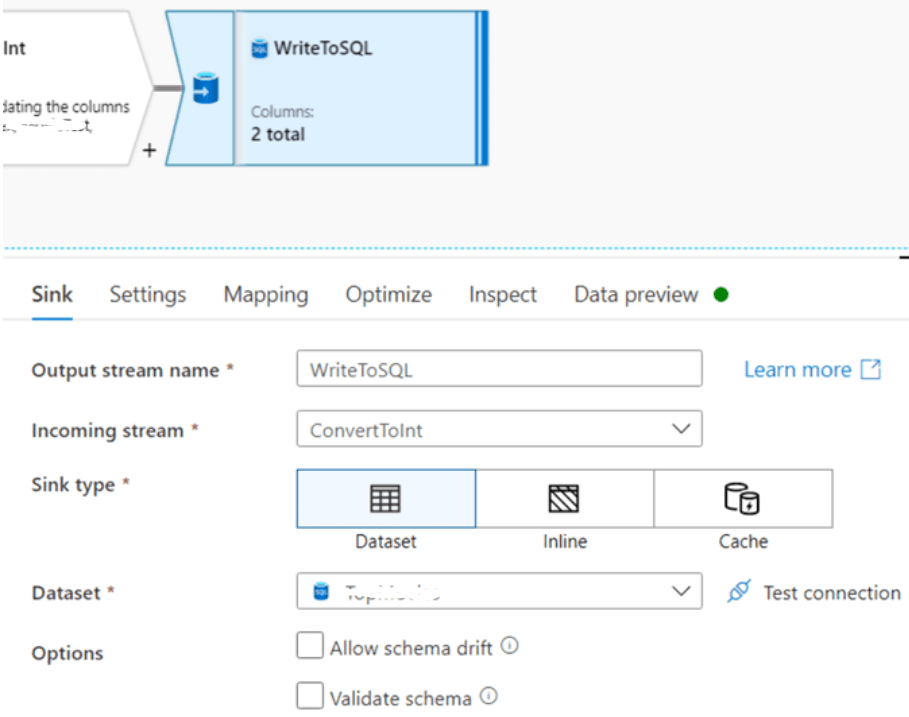
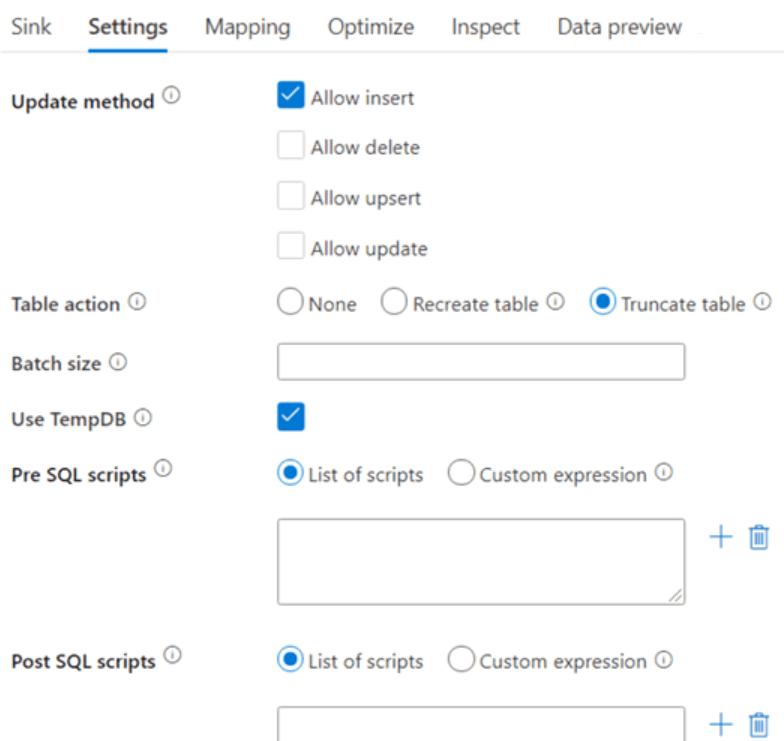
Azure Data Factory uses a staging table to write data before updating the destination table, and the temp table is the default table. If the user wants to transfer a large amount of data, needs to uncheck “Use TempDB” and specify schema, where Azure Data Factory stages data.
Step 11: Input columns can be mapped to columns in a table in the Mapping pane.
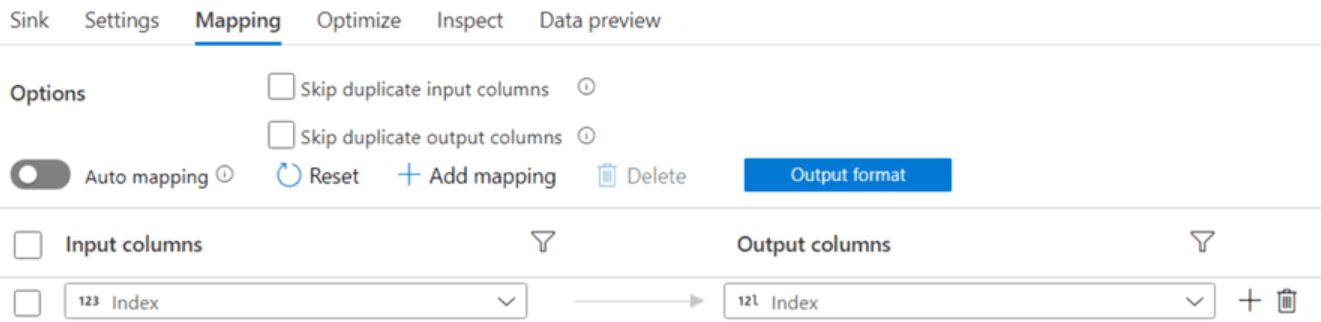
And hence the data will be written to SQL table.
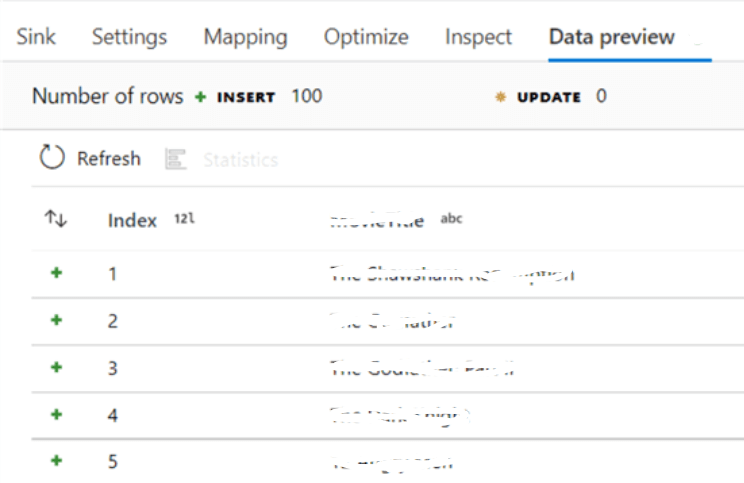
Step 12: To test the data flow, the user needs to create a pipeline with data flow activity.
Step 13: When pipeline is debugged, the data flow will also run.
**** Details in screenshots are hidden due to privacy issues.
Conclusion
We have seen what Data Flow means in Azure Data Factory and its overview. We have also gone through the usage of Data Flow in Azure and have worked on creating Mapping Data Flow. Listed out a few key takeaway points for better understanding.
Recommended Articles
This is a guide to Azure Data Factory Data Flow. Here we discuss the introduction, use, and how to create a mapping azure data factory in the data flow. You can also look at the following articles to learn more –

